当向Oracle提交一个sql命令时,Oracle到底做了哪些事情?对这个问题有很好的理解,能帮助你更好的分析sql语句的优化。
执行一条sql语句从开始到结束,需要经历4个步骤:
分析--对提交的语句进行语法分析、语义分析和共享池检查。
优化--生成一个可在数据库中用来执行语句的最佳计划
行资源生成--为会话取得最佳计划并建立执行计划
语句执行--完成实际执行查询的行资源生成步骤的输出。对应DDL来说,这一步就是语句的结 束。对应SELECT来说,这一步是取数据的开始。
以上步骤,有的是可以省略的,例如优化、行资源生成器阶段。这样可以节省大量的时间。
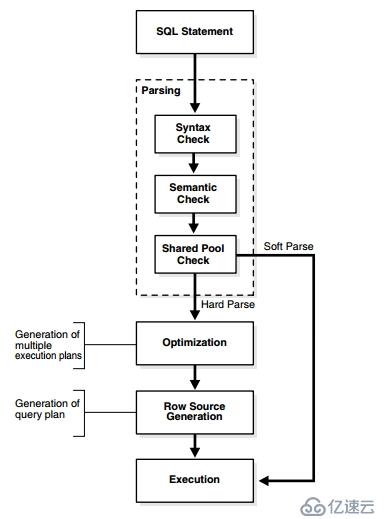
一、分析:
语法分析,sql是否符合语法标准。
SQL> select * form tab;
select * form tab
*
ERROR at line 1:
ORA-00923: FROM keyword not found where expected语义分析,假设sql是合法的,但是它有意义吗?你要访问的对象,你有访问权限吗?查询的列存在吗?是否存在歧义等待。
SQL> conn scott/tiger
Connected.
SQL> select x from dual;
select x from dual
*
ERROR at line 1:
ORA-00904: "X": invalid identifier
SQL> select * from dba_objects;
select * from dba_objects
*
ERROR at line 1:
ORA-00942: table or view does not exist对于DML语句,还有第三步。
共享池检查,此语句是否被其他用户使用过?可以重用已经执行过的工作吗?如果是,就是软解析soft parse,如果否,那就是硬解析。
DDL总是硬解析,语句从不重用。
Shared pool是SGA中的一部分,用来缓存以前执行过的sql语句、PLSQL、数据字典内容的缓存(以行的形式缓存内容,而buffer cache是以block的方式缓存内容)以及其他许多信息,以供会话重用。
从技术上来说,Oracle的语句解析分为两种:
硬解析--语句通过语句执行的每一个步骤从分析到优化,到行资源生成,到语句执行。
软解析--语句通过语句执行的某些步骤,特别是跳过优化步骤(最昂贵的步骤)。为了执行软解析,必须通过两个步骤。首先Oracle必须进行语义匹配,查看提交给Oracle的语句是否已经被执行过。然后,进行环境匹配。比如一个会话的初始化参数optimizer_mode=ALL_ROWS,一个会话的初始化参数optimizer_mode=FIRST_ROWS,这两个会话的环境就不一样。
为了开始这个处理,Oracle必须在Shared pool中寻找语句。为了高效的完成此操作,oracle将每个提交的sql语句,进行hash算法,生成一个hash_values。oracle使用hash_values查找Shared pool中是否有相同的语句。
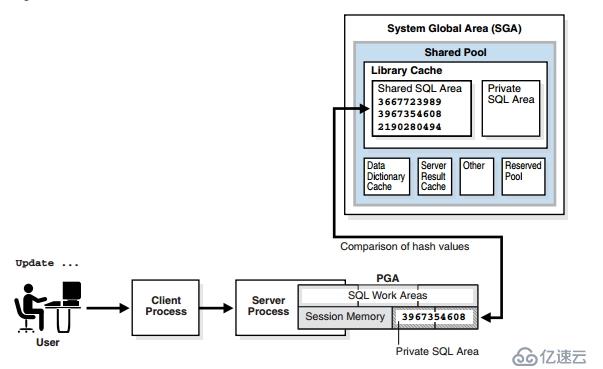
一旦找到,Oracle将进行语义和环境检查,sql语句都相同,难道还有语义不同的吗?我们看下面的例子。
建立两个用户
SQL> create user a identified by a;
User created.
SQL> create user b identified by b;
User created.2. 赋予用户权限
SQL> grant connect ,resource to a;
Grant succeeded.
SQL> grant connect,resource to b;
Grant succeeded.3.启用一个会话
SQL> conn a/a
Connected.
SQL> create table emp (id int);
Table created.
SQL> select * from emp;
no rows selected4. 启用另一个会话
SQL> conn b/b
Connected.
SQL> create table emp (id int);
Table created.
SQL> select * from emp;
no rows selected
SQL> select * from emp;
no rows selected5.启用另一会话,使用sys用户连接,进行如下查询。
SQL> SET LINESIZE 200
SQL> COL SQL_TEXT FOR A50
SQL> SELECT address, executions, sql_text
FROM v$sql
WHERE UPPER (sql_text) LIKE 'SELECT * FROM EMP';
ADDRESS EXECUTIONS SQL_TEXT
---------------- ---------- --------------------------------------------------
00000000893DF470 2 select * from emp
00000000893DF470 1 select * from emp
SQL>可见,虽然发出的语句是一样的,但是语义不同,所以v$sql中会有两条记录。b用户下,相同的语句执行了两次,因为语义相同,所以是一条记录,但是executions是2 。
我们再看看,语义相同,但是环境不同,会是什么结果。
以上的连接全部退出,新建一个连接进行如下查询。
SQL> conn / as sysdba
Connected.
SQL> alter session set optimizer_mode=ALL_ROWS;
Session altered.
SQL> SELECT * FROM A.EMP;
no rows selected
SQL> alter session set optimizer_mode=FIRST_ROWS;
Session altered.
SQL> SELECT * FROM A.EMP;
no rows selected查看sql解析情况
SQL> SET LINESIZE 200
SQL> COL SQL_TEXT FOR A50
SQL> select address,executions,sql_text
from v$sql
where upper(sql_text) like 'SELECT * FROM A.EMP';
ADDRESS EXECUTIONS SQL_TEXT
---------------- ---------- --------------------------------------------------
0000000091CD7810 1 SELECT * FROM A.EMP
0000000091CD7810 1 SELECT * FROM A.EMP可见,虽然语义相同,但是环境不同,Oracle也会当成2条语句来解析。
分析总结:
分析阶段做了如下操作,语法检查、计算散列值、语义检查、环境检查、计算子游标的散列值等。 此外Oracle还可能做了如下步骤:
在Shared pool中查找匹配的hash_value,如果能找到,确认访问对象的权限、检查环境。生成子游标hash_value。如果子游标hash_value也能匹配。那么将跳过优化和行资源生成。(此部门我们将在游标中详细讨论)
二、优化和行资源生成
当所有的DML语句第一次提交给Oracle时,在它的生命周期中至少被优化一次。优化发生在硬解析中。语义和语法完全相同,并且执行环境也相同的语句的执行可以利用以前的硬解析工作。这种情况下,对他们将进行软解析。
优化是一个费劲的、CPU密集型的处理,可能花在优化上的时间比实际执行还要长。优化不单耗cpu,还是导致Shared pool 高栓锁率。优化的规则有两种
1. 基于规则的优化法则(RBO)
2. 基于成本的优化法则(CBO)
优化就是根据优化法则,生成各种各样的执行计划,并且选择一个最好的执行计划。
行资源生成器是一个软件,就是将执行计划转化成其他部分可以利用的数据结构。
三、执行
利用行资源生成器输出的执行计划结构,执行具体的步骤。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



