小编给大家分享一下怎样使用python网络爬虫抓取视频,希望大家阅读完这篇文章后大所收获,下面让我们一起去探讨吧!
准备工作:
l Chrome 浏览器、
l Vim
l Python3 开发环境
l Kali Linux
API 寻找 && 提取
1、我们通过 F12 打开开发者模式。
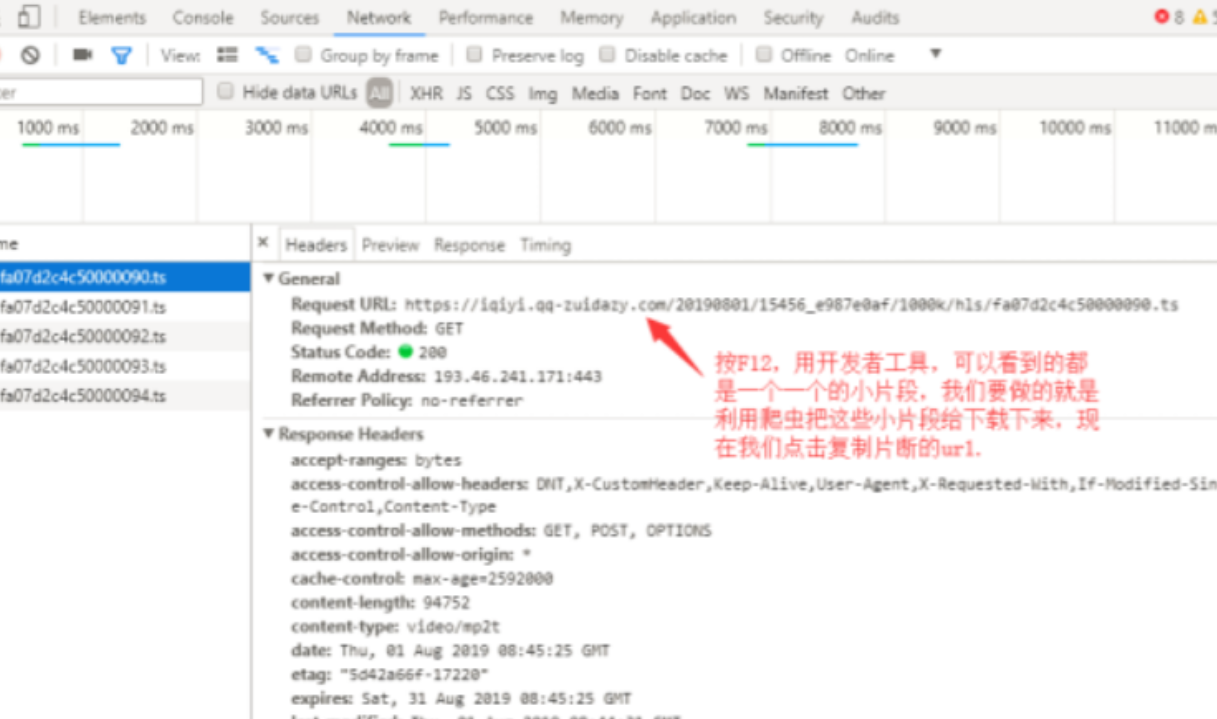
2、再查看一下 Headers 属性
3、再看下看到Request URL这个属性值
代码实现
写好脚本,利用爬虫下载片断
##导入的两个模块,其中requests模块需要自行下载
from multiprocessing import Pool
import requests
##定义一个涵数
def demo(i):
##定义了一个url,后面%3d就是截取后面三位给他加0,以防止i的参数是1的时候参数对不上号,所以是1的时候就变成了001
url="https://vip.okokbo.com/20180114/ArVcZXQd/1000kb/hls/phJ51837151%03d.ts"%i
##定义了请求头信息
headers={"user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36"}
##构建自定义请求对象
req=requests.get(url,headers=headers)
##将文件保存在当前目录的mp4文件中,名字以url后十位数起名
with open('./mp4/ {}'.format(url[-10:]), 'wb') as f:
f.write(req.content)
##程序代码的入口
if __name__=='__main__':
##定义一个进程池,可以同时执行二十个任务,不然一个一个下载太慢
pool = Pool(20)
##执行任务的代码
for i in range(100):
pool.apply_async(demo, (i,))
pool.close()
pool.join()复制电影存放的路径
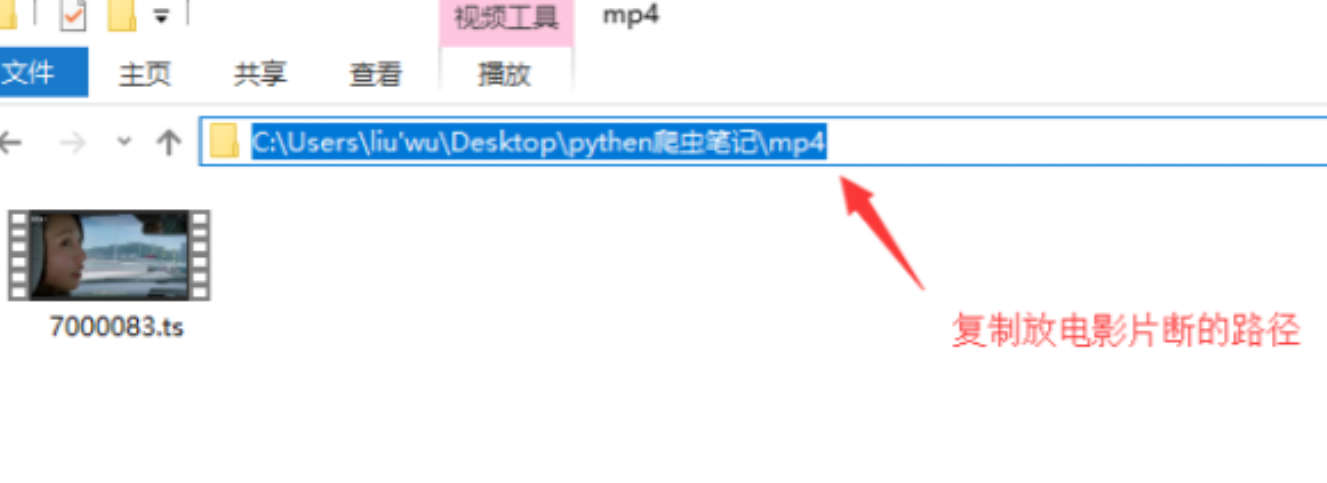
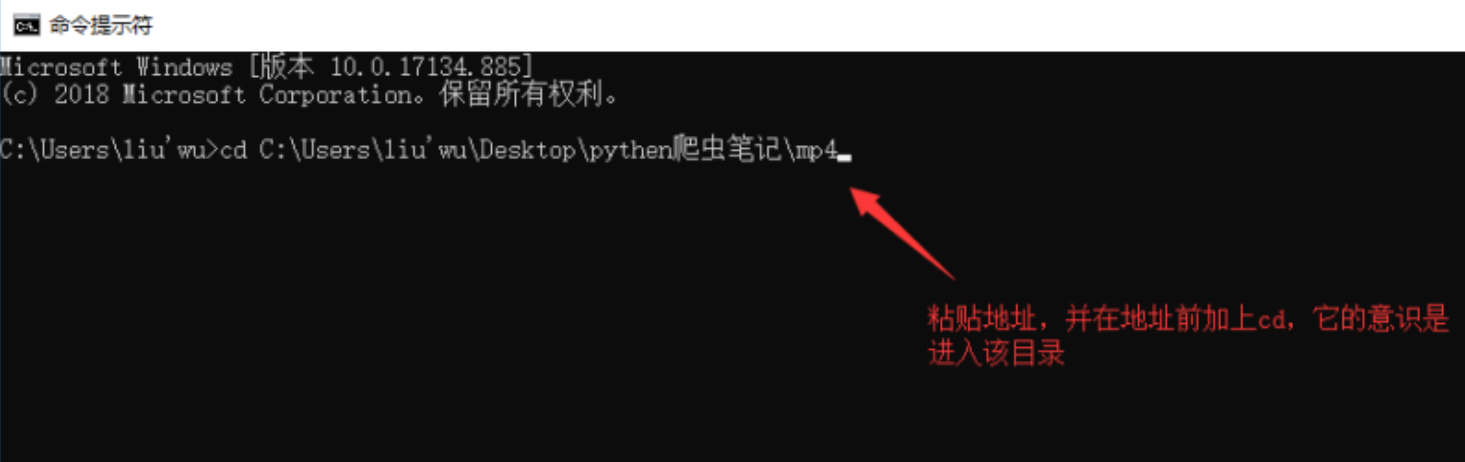
用进入windows命令行模式,粘贴地址
复制该目录下所有以*.ts结尾的文件,复制成一个文件
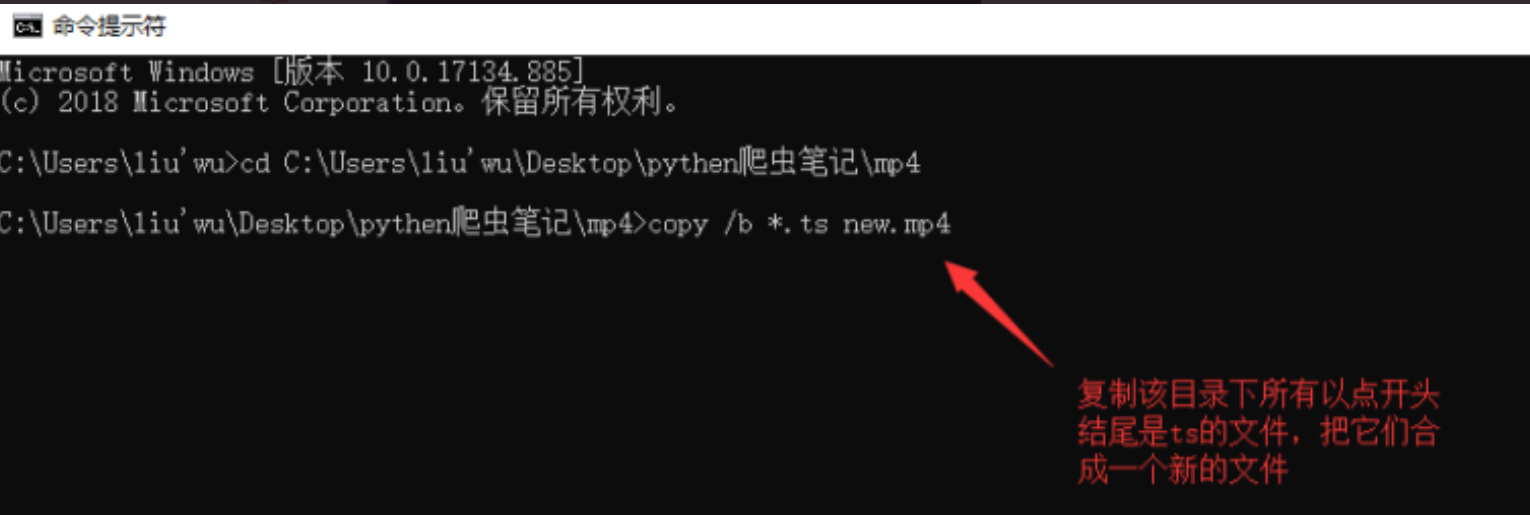
进行合并
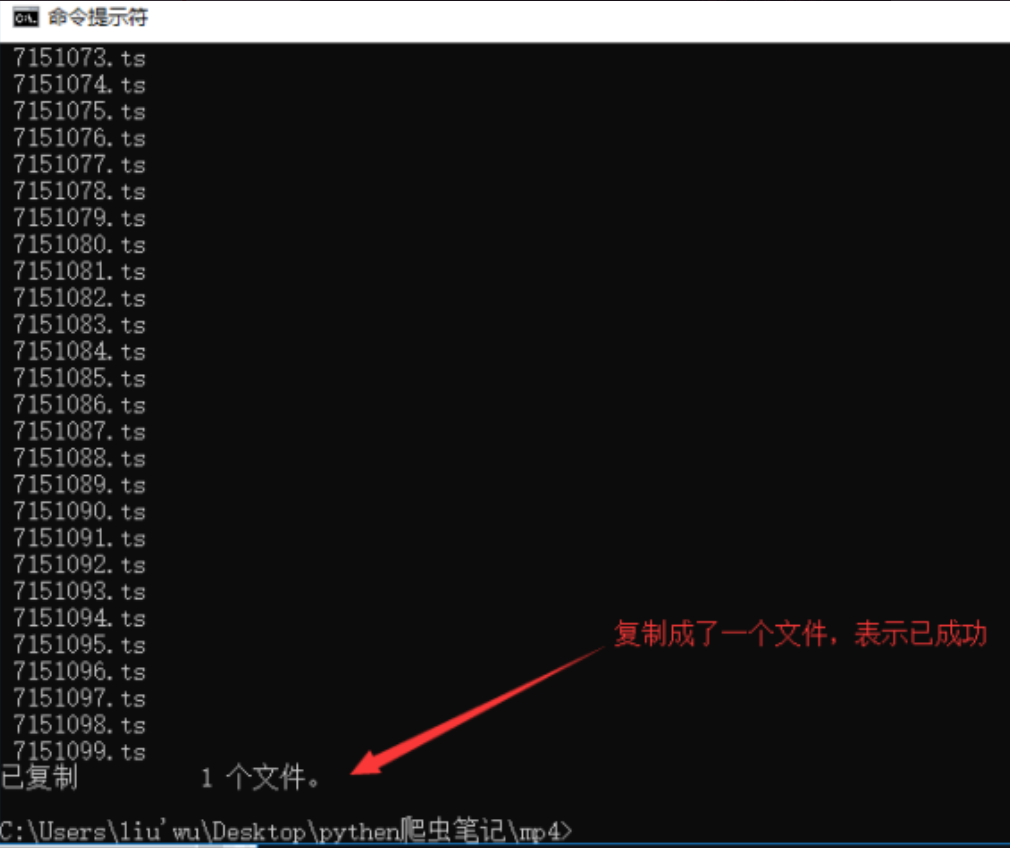
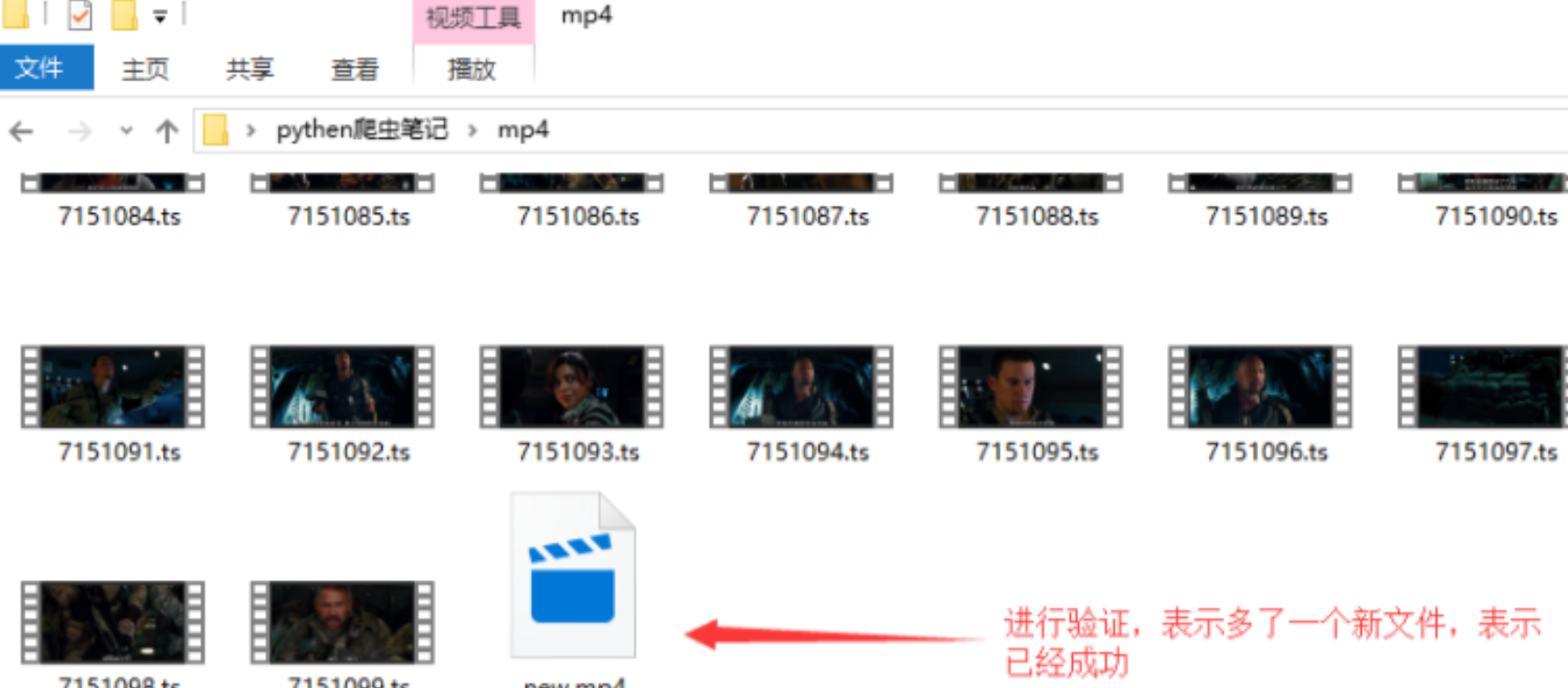
进行验证
看完了这篇文章,相信你对怎样使用python网络爬虫抓取视频有了一定的了解,想了解更多相关知识,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://www.py.cn/jishu/jichu/20711.html



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



