mysql数据库中如何实现动态修改复制过滤器?针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
MySQL动态修改复制过滤器
说说今天遇到的问题吧,今天在处理一个业务方的需求,比较变态,我大概描述一下:
1、线上的阿里云rds上面有个游戏的日志库,里面的表都是日表的形式,数据量比较大了,每次备份的时候,都会导致线上的rds报警,报警内容是IO资源占用过多。
2、这个rds上有一个本地的ECS只读从库,这个只读从库会实时同步线上的rds数据库中的数据,这个只读从库供业务方查询使用
3、业务方说这些数据都还有用,只读从库上的数据必须有,线上rds上的数据可以删除,保留两个星期即可。
场景就是这么个场景,DBA想要解决报警这个问题,业务方想要保证拥有完整的数据。请问,怎么解决?
当时看到这个问题,我想骂人,这需求一看就不合理,哪儿有删除一个库,另外一个库上还保留的道理,况且都是些日志数据,不直接搞个冷备份,然后删除线上,搞这么一出干啥啊。但是啊,怎么说也没有缓和的余地,于是就开始思考这个问题应该怎么解决。我想到的解决办法有以下几个:
1、扩容,提升性能。数据量大,扩磁盘呗,IO使用率高,提升性能么,这是最直接的解决办法,也是最贵的解决办法,首先被砍掉。
2、先备份再删除再还原。rds主库上提前备份日表数据,然后删除数据,此时从库会同步删除数据,然后再将第一步备份的数据还原到从库上。这个办法从可行性上来讲是可以的,因为保证了没有数据丢失。但是操作起来比较麻烦,手续太多,不够方便。
3、使用replicate-ignore-table参数进行对于指定的表进行过滤。设置了这个参数,可以让你过滤指定数据表的所有操作。我们看看官方文档对这个参数的描述,给个链接:https://dev.mysql.com/doc/refman/5.7/en/replication-options-slave.html#option_mysqld_replicate-wild-ignore-table
描述如下:
Creates a replication filter which keeps the slave thread from replicating a statement in which any table matches the given wildcard pattern. To specify more than one table to ignore, use this option multiple times,
上面的意思是你可以使用这个参数创建一个过滤器,从而过滤掉匹配你制定的规则的特定表的操作(听着很绕口),就是说你可以制定过滤规则,加入规则中制定了表a,那么表a的操作就不会同步到从库中了。
这和我们的需求符合,也就是我们如果设置了要过滤的表,那么当我们进行删除表操作的时候,从库中不会对表进行删除,就实现了我们想要的结果。测试一下这个功能吧:
首先我们创建数据库test_ignore,然后在其中创建表:
主库上操作:
mysql :test_ignore >>show tables;
Empty set (0.00 sec)
mysql :test_ignore >>create table aaa (id int not null);
Query OK, 0 rows affected (0.19 sec)
mysql :test_ignore >>create table aab (id int not null);
Query OK, 0 rows affected (0.01 sec)
mysql :test_ignore >>create table aac (id int not null);
Query OK, 0 rows affected (0.00 sec)
mysql :test_ignore >>create table aad (id int not null);
Query OK, 0 rows affected (0.01 sec)
mysql :test_ignore >>create table aae (id int not null);
Query OK, 0 rows affected (0.01 sec)从库上查看:
mysql :test_ignore >>show tables;
+-----------------------+
| Tables_in_test_ignore |
+-----------------------+
| aaa |
| aab |
| aac |
| aad |
| aae |
+-----------------------+
5 rows in set (0.00 sec)发现已经同步过来了。此时是处于主从同步状态,如果现在我们在主库上删除表,那么从库上的表一定会删除,这不是我们想要的结果。
很显然,接下来的一步是配置replicate-wild-ignore-table这个参数了,一般情况下,我们需要通过停止从库的服务进行my.cnf文件的配置,如果我们要配置多个表,则需要在my.cnf文件中写多条通配的记录。例如,在本例子中,需要配置该参数的值为test_ignore.aa%,其中%代表通配符,也就是说,test_ignore数据库中形如aa%这种格式的表操作都会被过滤掉。而我们创建的表aaa、aab、aac、aad、aae都是形如这种的,所以针对这几个表的操作一定不会同步到从库了,我们测试一下:
首先查看当前的复制状态:
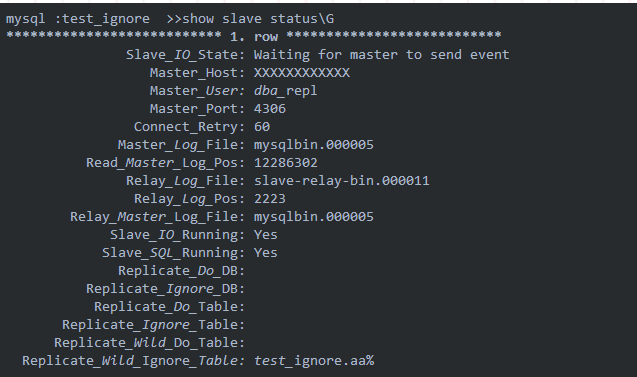
双Yes状态,说明复制关系没有问题
主库进行操作:
mysql :test_ignore >>drop table aaa;
Query OK, 0 rows affected (0.01 sec)
mysql :test_ignore >>drop table aab;
Query OK, 0 rows affected (0.00 sec)从库上进行查看:
mysql :test_ignore >>show tables;
+-----------------------+
| Tables_in_test_ignore |
+-----------------------+
| aaa |
| aab |
| aac |
| aad |
| aae |
+-----------------------+
5 rows in set (0.00 sec)从库上的表还在,说明主库上的操作没有被同步到从库,我们配置的参数
replicate-wild-ignore-table=test_ignore.aa%
起作用了。此时,如果我们在主库上创建一个表:
`主库`
mysql :test_ignore >>create table aaf(id int);
Query OK, 0 rows affected (0.00 sec)
`从库`
mysql :test_ignore >>show tables;
+-----------------------+
| Tables_in_test_ignore |
+-----------------------+
| aaa |
| aab |
| aac |
| aad |
| aae |
+-----------------------+
5 rows in set (0.00 sec)发现从库并没有同步主库的表aaf,因为aaf也匹配了test_ignore.aa%这条规则。
利用这个特性,我们能够很好的解决这个业务场景,也就是主库删除,从库保留数据。但是,这里要说但是了,这个方法有一个比较严重的问题,就是每次都需要重启从库,如果我们需要配置第二条规则,第三条规则,则需要重启从库2次,3次,这个过程中,从库对于业务方是不可见的,如果无法访问,很可能造成程序报错,这是我们不能忍受的。
这个过程肯定是要解决的,怎么解决呢?能不能找到不停机就能修改复制过滤器的方法?找找官方文档。
果然,停机是不可能停机的,这辈子都不可能停机。官方文档中有这么一句话:
You can also create such a filter by issuing a CHANGE REPLICATION FILTER REPLICATE_WILD_IGNORE_TABLE statement.
我去,这是个啥语句,表示从来没有用过,可以通过在线变更复制过滤器的方法来对过滤器进行修改,看看官方文档中的介绍:

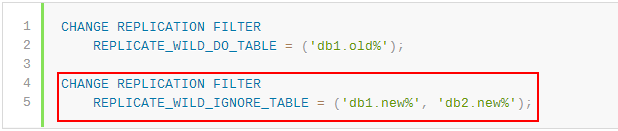
看到了一个神奇的语句,赶紧来试试:
mysql :test_ignore >>change replication filter replicate_wild_ignore_table=('test_ig%.aa%');
ERROR 3017 (HY000): This operation cannot be performed with a running slave sql thread; run STOP SLAVE SQL_THREAD first
mysql :test_ignore >>stop slave;
Query OK, 0 rows affected (0.00 sec)
mysql :test_ignore >>change replication filter replicate_wild_ignore_table=('test_ig%.aa%');
Query OK, 0 rows affected (0.00 sec)
mysql :test_ignore >>start slave;
Query OK, 0 rows affected (0.01 sec)直接使用,提示需要stop slave sql_thread,想想也能理解,不停止复制直接修改复制的规则好像有点不妥,索性停止了整个复制,然后重新修改复制过滤器,妥了,成功执行,开启复制,一套操作行云流水。
再来看看复制关系中的状态:
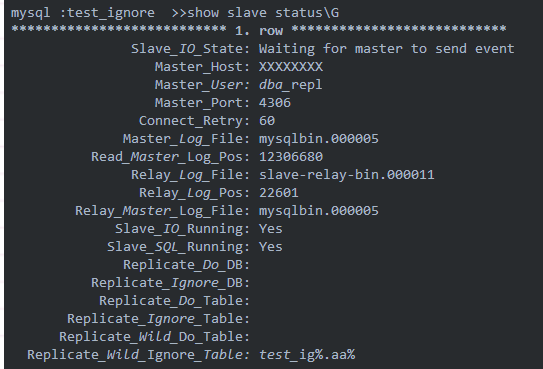
忽略的表规则已经变成了test_ig%.aa%,也就是说,以test_ig开头的数据库中以aa开头的表的操作,都不会被同步到从库,包括对表的alter和drop以及create操作。
但这里,方案就出来了,我们知道,日表一般是YYYYMMDD这种形式的,我们只要过滤YYYYMM%这种格式的日表,然后在主库上对它进行删除,这个操作将不会被同步到从库,那么这个问题就可以顺利解决了。
当然,除了这个方案之外,还有一些方案,例如:
如果业务容忍部分数据丢失,我们还可以使用关闭binlog---删表---打开binlog的方式使得从库不会同步主库的drop操作;
线上所有的日表操作都配置成ignore,然后利用触发器将日表中的更新同步到从库中;
这一系列的操作,其实不是从本质上解决问题,本质上还是业务设计的问题,日表中的打点日志太多,可以适当减少这些打点日志,对于打点日志,需要确定保留周期,过期的日志,需要及时清理,保证服务器的指标和性能。
关于mysql数据库中如何实现动态修改复制过滤器问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



