使用Django如何实现正则URL匹配?相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
一、引子
在day17 作业中,我们查看主机详细信息的时候,是通过 在url 中拼接,传参数。urls 中匹配 path("detail/",views.detail)
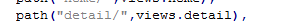
这样url 变成类似 http://127.0.0.1:8000/detail/?nid=2 今天我们来学习,类似http://127.0.0.1:8000/detail-3.html 这样的URL
据说,以前我们使用的方式 ,在seo 时候算是动态页面,后面这种方式算静态页面。可能在做搜索优化的时候有好处吧。
二、开搞栗子
忽略掉数据库,先在 views 新建一个用户字典
2.1 动态页面的栗子
views 代码:
info_dic={
1:{"name":"zhangsan","email":"zhangsan@163.com","age":22},
2:{"name":"lisi","email":"lisi@163.com","age":27},
3:{"name":"wangwu","email":"wangwu@163.com","age":29},
4:{"name":"laoliu","email":"laoliu@163.com","age":30},
5:{"name":"chenpi","email":"chenpi@163.com","age":32},
}
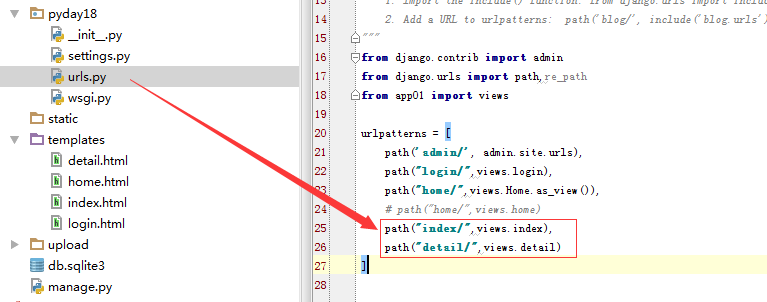
def index(request):
return render(request,"index.html",{"info_dic":info_dic})
def detail(request):
nid=request.GET.get("nid")
print(nid,type(nid))
info=info_dic.get(int(nid))
print(info)
return render(request,"detail.html",{"info":info})urls
前端,index.html,
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
</head>
<body>
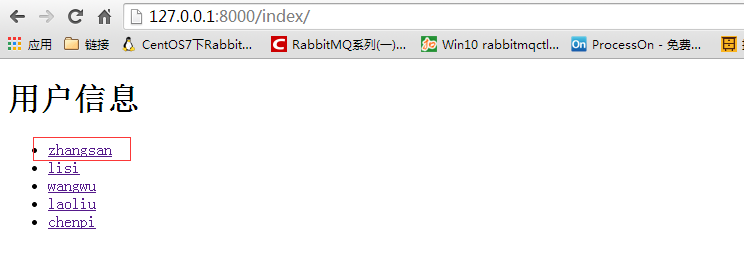
<h2>用户信息</h2>
<ul>
{% for k,v in info_dic.items %}
<li><a target="_blank" href="/detail/?nid={{ k }}" rel="external nofollow" >{{ v.name }}</a></li>
{% endfor %}
</ul>
</body>
</html>前端,detail
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
</head>
<body>
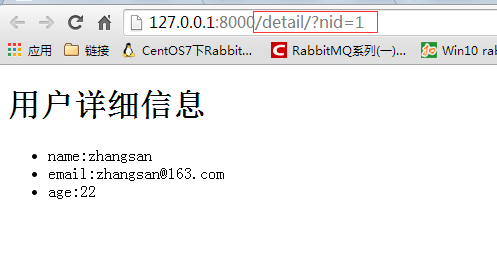
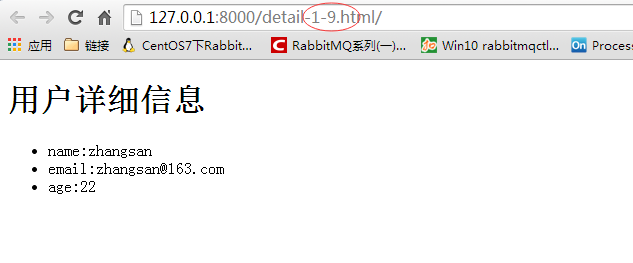
<h2>用户详细信息</h2>
<ul>
<li>name:{{ info.name }}</li>
<li>email:{{ info.email }}</li>
<li>age:{{ info.age }}</li>
</ul>
</body>
</html>结果:
2.2 下面用 正则表达式来 搞URL 匹配,静态页面,
urls
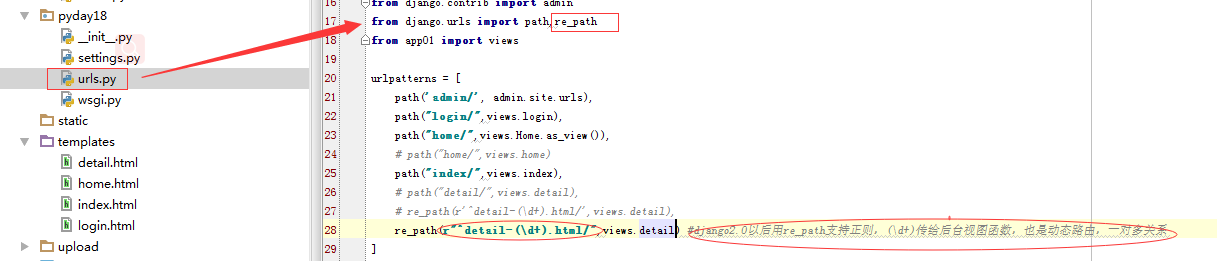
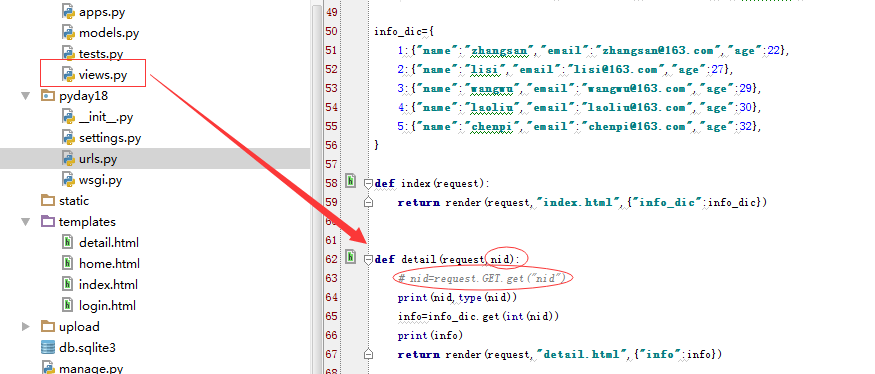
views ,
直接在函数中传参数,nid 形式参数。不像之前需要自己到 reques.method 中去取
结果

上面的栗子中,我们得知参数是通过形参传递的,类似定义函数的形参数,
下面再搞一个栗子验证
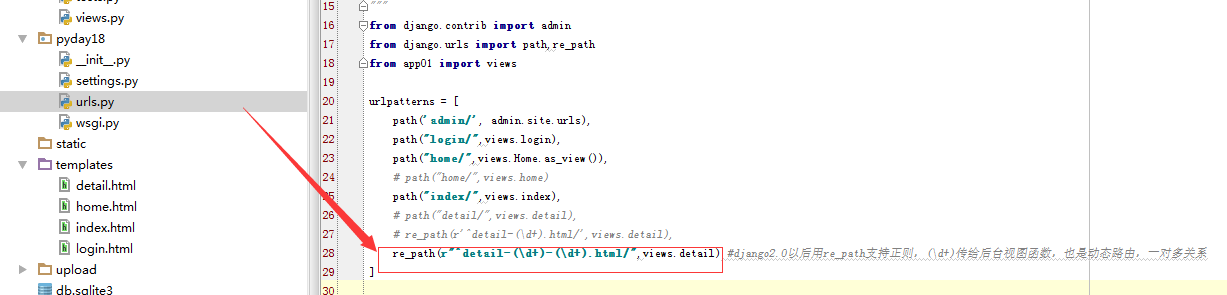
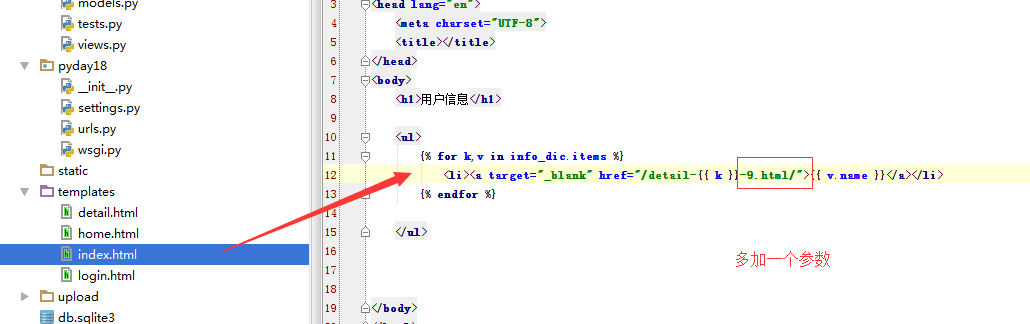
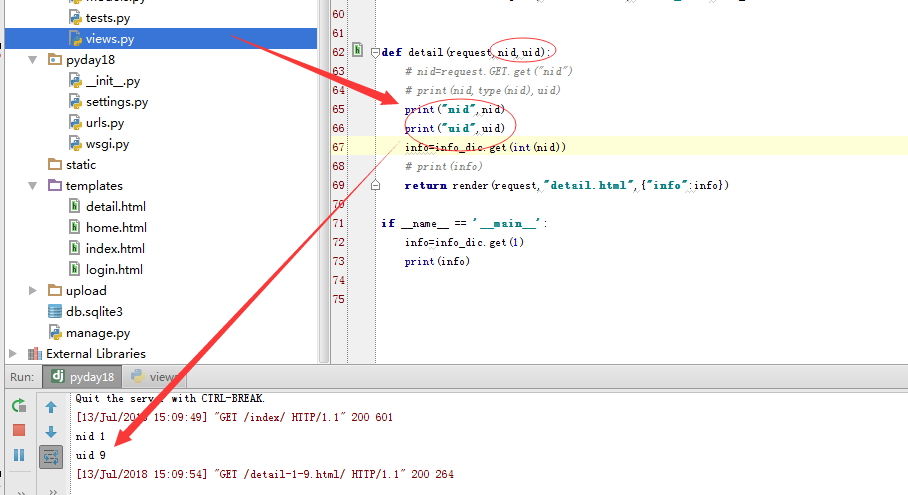
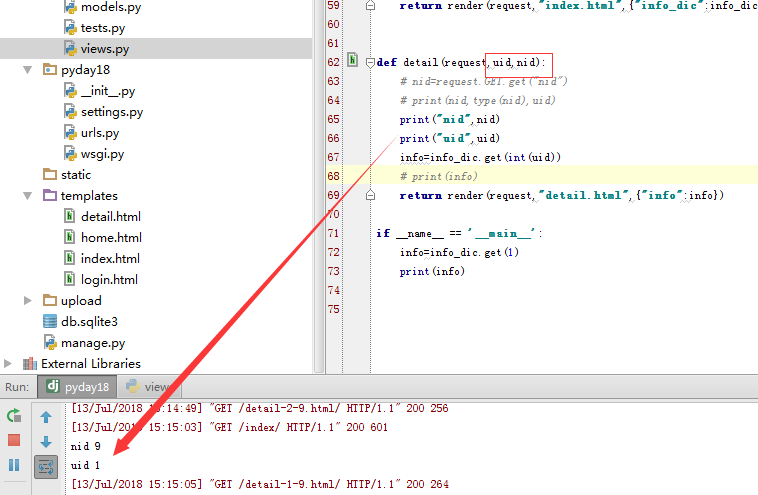
参数位置变换后 ,获取的数值也变了
三、分组传参
在上面的栗子中,我们知道如果不分组,那么参数就是类似函数的位置参数,靠天吃饭,
很显然,这样不方便我们在实际的使用中去调用。那么使用关键字参数呢,在URL 匹配中就需要分组
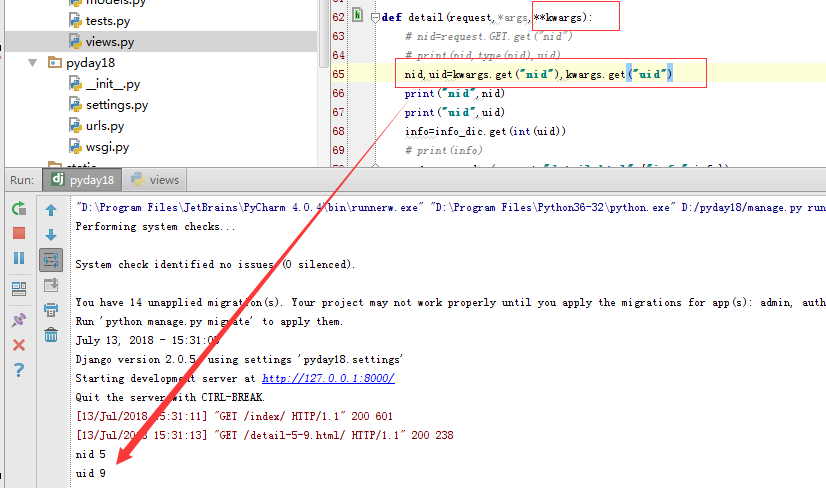
下面搞栗子,变换nid,uid 位置之后,打印的结果是一样的。
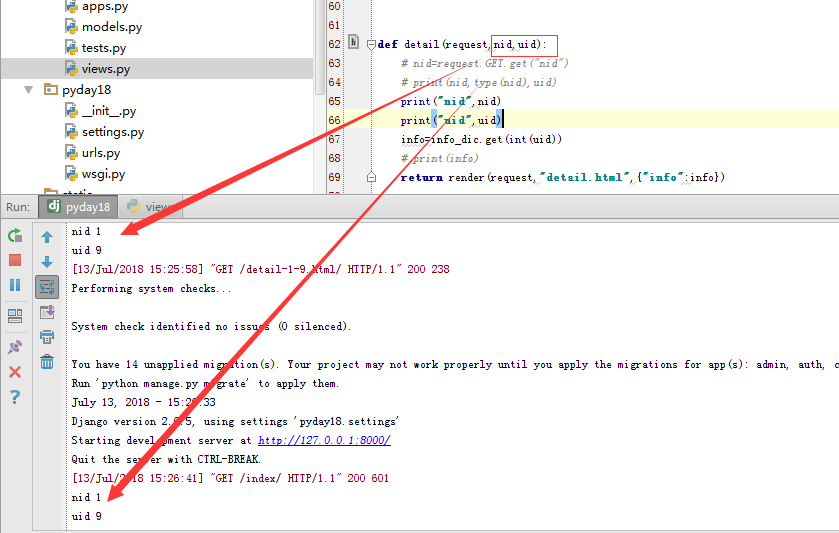
位置参数可以在 *arg 中获取,关键字参数可以在 **kwargs 中获取
四、总结
路由系统:URL
看完上述内容,你们掌握使用Django如何实现正则URL匹配的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



