这篇文章主要介绍了怎么用scrapy框架构建python爬虫,具有一定借鉴价值,需要的朋友可以参考下。希望大家阅读完这篇文章后大有收获。下面让小编带着大家一起了解一下。
制作爬虫,总体来说分为两步:先爬再取。
也就是说,首先你要获取整个网页的所有内容,然后再取出其中对你有用的部分。
要建立一个Spider,你必须用scrapy.spider.BaseSpider创建一个子类,并确定三个强制的属性:
name:爬虫的识别名称,必须是唯一的,在不同的爬虫中你必须定义不同的名字。
start_urls:爬取的URL列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。
parse():解析的方法,调用的时候传入从每一个URL传回的Response对象作为唯一参数,负责解析并匹配抓取的数据(解析为item),跟踪更多的URL。
创建douban_spider.py文件,保存在douban\spiders目录下。并导入我们需用的模块
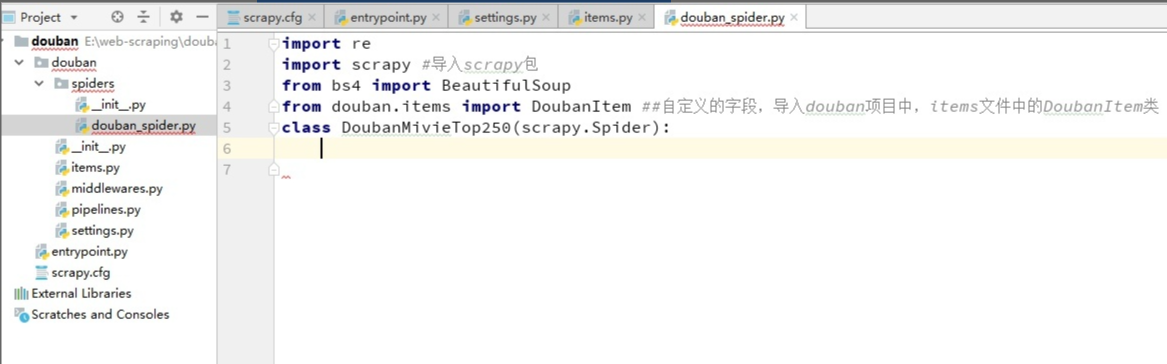
编写主要模块:
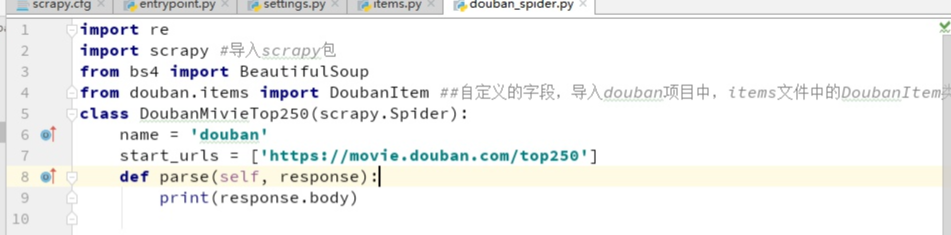
然后运行一下,
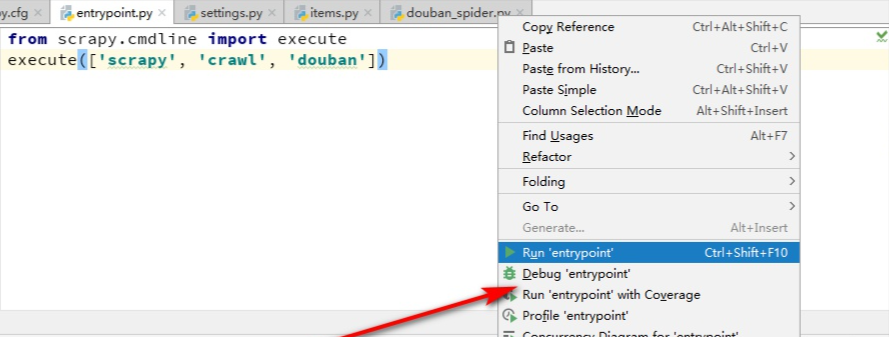
会看到有403错误,是因为我们爬取的时候没加头部导致的:
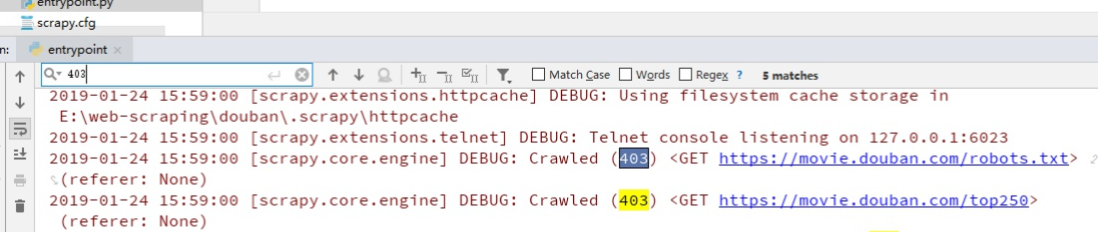
我们来伪装一下,在settings.py里加上USER_AGENT:
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.54 Safari/536.5'
再次运行,即可看到正确结果。
感谢你能够认真阅读完这篇文章,希望小编分享怎么用scrapy框架构建python爬虫内容对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,遇到问题就找亿速云,详细的解决方法等着你来学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





