今天就跟大家聊聊有关python爬虫中怎么利用分布式获取数据,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
假设我有三台爬虫服务器A、B和C。我想让我所有的账号登录任务分散到三台服务器、让用户抓取在A和B上执行,让粉丝和关注抓取在C上执行,那么启动A、B、C三个服务器的celery worker的命令就分别是
celery -A tasks.workers -Q login_queue,user_crawler worker -l info -c 1 # A服务器和B服务器启动worker的命令,它们只会执行登录和用户信息抓取任务。
celery -A tasks.workers -Q login_queue,fans_followers worker -l info -c 1 # C服务器启动worker的命令,它只会执行登录、粉丝和关注抓取任务。
然后我们通过命令行或者代码(如下)就能发送所有任务给各个节点执行了
# coding:utf-8
from tasks.workers import app
from page_get import user as user_get
from db.seed_ids import get_seed_ids, get_seed_by_id, insert_seeds, set_seed_other_crawled
@app.task(ignore_result=True)
def crawl_follower_fans(uid):
seed = get_seed_by_id(uid)
if seed.other_crawled == 0:
rs = user_get.get_fans_or_followers_ids(uid, 1
rs.extend(user_get.get_fans_or_followers_ids(uid, 2))
datas = set(rs)
# 重复数据跳过插入
if datas:
insert_seeds(datas)
set_seed_other_crawled(uid)
@app.task(ignore_result=True)
def crawl_person_infos(uid):
""
根据用户i来爬取用户相关资料和用户的关注数和粉丝数(由于微博服务端限制,默认爬取前五页,企业号的关注和粉丝也不能查看)
:param uid: 用户id
:return:
"""
if not uid:
return
# 由于与别的任务共享数据表,所以需要先判断数据库是否有该用户信息,再进行抓取
user = user_get.get_profile(uid)
# 不抓取企业号
if user.verify_type == 2:
set_seed_other_crawled(uid)
return
app.send_task('tasks.user.crawl_follower_fans', args=(uid,), queue='fans_followers',
routing_key='for_fans_followers')
@app.task(ignore_result=True)
def excute_user_task():
seeds = get_seed_ids()
if seeds:
for seed in seeds:
# 在send_task的时候指定任务队列
app.send_task('tasks.user.crawl_person_infos', args=(seed.uid,), queue='user_crawler',
routing_key='for_user_info')分布式爬虫架构图
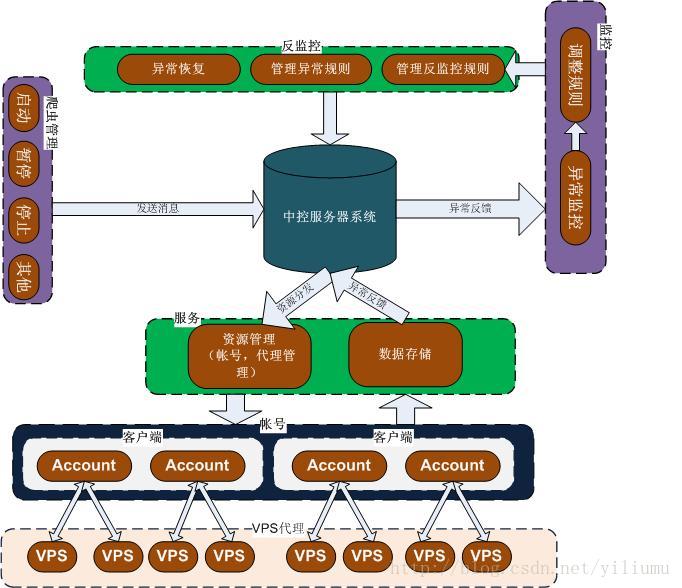
看完上述内容,你们对python爬虫中怎么利用分布式获取数据有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



