SQL语句中分组函数与聚合函数有哪些?针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
1 分组聚合的原因
SQL中分组函数和聚合函数之前的文章已经介绍过,单说这两个函数有可能比较好理解,分组函数就是group by,聚合函数就是COUNT、MAX、MIN、AVG、SUM。
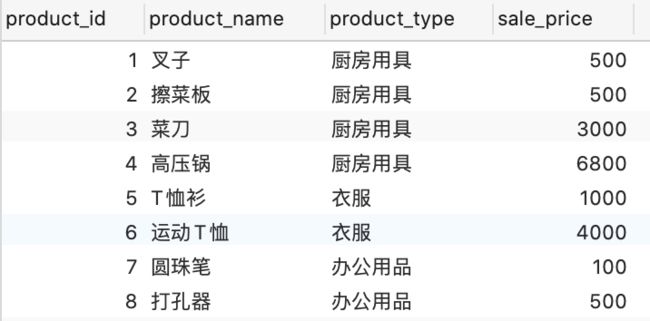
拿上图中的数据进行解释,假设按照product_type这个字段进行分组,分组之后结果如下图。
SELECT product_type from productgroup by product_type

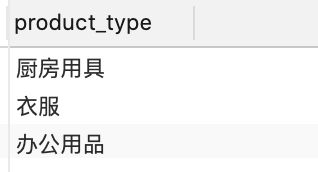
从图中可以看出被分为了三组,分别为厨房用具、衣服和办公用品,就相当于对product_type这个字段进行了去重,确实group by函数有去重的作用。
SELECT DISTINCT product_type from product
假设分组之后,我想看一下价格,也就是sale_price这个字段的值,按照如下这个写法,会报如下错误。
SELECT product_type,sale_price from productgroup by product_type

这是为什么呢?原表按照product_type分组之后,厨房用具对应4个值,衣服对应2个值,办公用品对应2个值,这就是在取sale_price这个字段的时候为什么报错了,一个空格中不能填入多个值,这时候就可以用聚合函数了,比如求和,求平均,求最大最小值,求行数。聚合之后的值就只有一个值了。
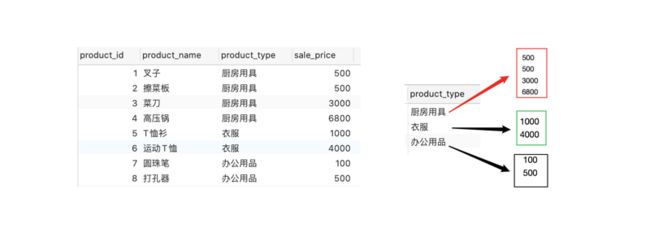
SELECT product_type,sum(sale_price),avg(sale_price),count(sale_price),max(sale_price) from productgroup by product_type

对于多个字段的分组,其原理是一样的。从上述中记住两点:分组去重和分组聚合。
2 distinct和group by去重的区别 Distinct 和group by 设计时侧重点不一样
distinct只是为了去重,而group by是为了聚合统计的。
两者都有去重的效果,但是执行的效率不一样
单个字段去重
--DISTINCTSELECT distinct product_type from product--GROUP BYselect product_type from productGROUP BY product_type
多个字段去重
--DISTINCTSELECT distinct product_name, product_type from product--GROUP BYselect product_name, product_type from productGROUP BY product_name, product_type

执行效率
select <列名1>,<列名2>from<表名>where 查询条件group by 分组类别having 对分组结果指定条件order by <列名> (desc)limit 数字

SQL语言的运行顺序,先执行上图中的第一步,然后再执行select子句,最后对结果进行筛选。distinct是在select子句中,而group by在第一步中,所以group by去重比distinct去重在效率上要高。
sql中聚合函数和分组函数
The COUNT operator is usually used in combination with a GROUP BY clause. It is one of the SQL “aggregate” functions, which include AVG (average) and SUM.
COUNT运算符通常与GROUP BY子句结合使用。 它是SQL“聚合”功能之一,其中包括AVG(平均)和SUM。
This function will count the number of rows and return that count as a column in the result set.
此函数将对行数进行计数,并将该计数作为列返回到结果集中。
Here are examples of what you would use COUNT for:
以下是将COUNT用于以下用途的示例:
Counting all rows in a table (no group by required)
计算表中的所有行(不需要按组)
Counting the totals of subsets of data (requires a Group By section of the statement)
计算数据子集的总数(需要语句的“分组依据”部分)
For reference, here is the current data for all the rows in our example student database.
作为参考,这是示例学生数据库中所有行的当前数据。
select studentID, FullName, programOfStudy, sat_score from student; -- all records with fields of interest
This SQL statement provides a count of all rows. Note that you can give the resulting COUNT column a name using “AS”.
该SQL语句提供所有行的计数。 请注意,您可以使用“ AS”为所得的COUNT列命名。
select count(*) AS studentCount from student; -- count of all records
Here we get a count of students in each field of study.
在这里,我们得到了每个学习领域的学生人数。
select studentID, FullName, count(*) AS studentCount from the student table with a group by programOfStudy;
Here we get a count of students with the same SAT scores.
在这里,我们得到了具有相同SAT分数的学生人数。
select studentID, FullName, count(*) AS studentCount from the student table with a group by sat_score;
Here is an example using the campaign funds table. This is a sum total of the dollars in each transaction and the number of contributions for each political party during the 2016 US Presidential Campaign.
这是使用广告系列资金表的示例。 这是2016年美国总统大选期间每笔交易的总金额和每个政党的捐款额。
select Specific_Party, Election_Year, format(sum(Total_$),2) AS contribution$Total, count(*) AS numberOfContributions
from combined_party_data
group by Specific_Party,Election_Year
having Election_Year = 2021;As with all of these things there is much more to it, so please see the manual for your database manager and have fun trying different tests yourself.
关于所有这些事情,还有很多事情要做,所以请参阅数据库管理员手册,并尝试自己进行不同的测试,这很有趣。
group by可以根据给定数据列的每个成员对查询结果进行分组统计,最终得到一个汇总表。
group by几个比较重要的约束:
(1)select字句中的列名和having或where中的列名必须为分组列或列函数.列函数对于group by字句定义的每个组返回一个结果
(2)group by一般和聚合函数一使用才有意义,比如count,sum,avg等,使用group by 的两个要素:
(3)出现在select后面的字段,要么是聚合函数中的,要么是group by中的.
(4)要筛选结果,可以先使用where再用group by或者先用group by再用having
第(4)项根据各个数据库不同不一定都能适用,因此最好不要这样用,老老实实用having
(一)聚合函数是指对列上的数据进行操作,起到统计的作用。前面的函数都是最一行记录进行操作得到的数据,包括前面的日期函数、数学函数、字符函数、转换函数以及条件判断函数。
常用的聚合函数有:count、sum、avg、max、min。这5个函数个起到统计记录数、求和、求平均值、求最大值、最小值的作用。
Count:count函数对查询的数据统计记录数量,这个函数不对字段值为NULL的值进行统计,也就是说某个查询的字段有NULL值,则NULL值的数量会被减除,这样就可以不对NULL设置查询条件了。
如果要对NULL值设置查询,则可以用WHERE 字段 IS NULL来作为条件。
Sum:sum函数求和,只能对数值型数据操作,也会忽略NULL值。举例:
Select sum(考试成绩) as 计算机总成绩
From score
Where 课号 in (select 课号 from course where 课名=”计算机”)
Avg:求平均值,参数也必须为数值型字段名或者结果为数值的表达式。
Max、min:这两个函数求最大值和最小值,但是不能放到WHERER中以及SELECT子句的字段名位置上。
例:select max(x1) from y where max(x2) in(select…) 错误的语法。
Select x1 from y where x2=max(x3) 错误的语法。
select max(x1) from y where x2) in(select max(x2,)…) 正确。
注:5个函数都可以使用distinct统计不重复的值:
Select count(distinct(课程)) as 课程数量 from 课程表
Access和mysql不能将distinct放置到参数中,解决方法:查询distinct保存为新表INTO语句,然后再使用count。
(二)数据分组是指将数据表中的数据按照指定字段的不同值分为很多组,使用group by 子句进行操作。
Group by通常不直接查询所有字段并且分组,group by和select后分组字段和查询字段通常一致。因为select * from y group by x 会产生错误,通常对某个字段分组并且利用聚合函数计算分组得到的值。
聚合函数和分组的组合并设置查询条件:可以对一个字段分组并且设定条件,这样得到的结果将会是计算分组并且满足条件的值。例:
查询各个所属院系中所有男生的值:
Select 所属院系,count(*) as 男生人数from student where 性别='男' group by 所属院系
查询直方图:利用replicate()函数,将分组得到的数据作为次数,重复一个设置的符号。
排序查询结果:order by语句,ASC、DESC 位于group by之后
Case表达式和group by的结合:
Select 所属院系,count(case
When 性别='男' then 1
Else null
End ) as 男生人数,
count(case
When 性别='女' then 1
Else null
End ) as 女生人数
From student group by 所属院系
Hanving子句设置分组group by的分组查询条件。
Having子句总是和group by子句结合使用,依赖于分组,可以在having中使用聚合函数;where 也可以设定条件,但是不依赖于分组的字段,但是不能使用聚合函数。
Select 学号,sum(考试成绩) as 考试总成绩 from score group by 学号 having sum(考试成绩)>400 order by 考试总成绩 desc
关于SQL语句中分组函数与聚合函数有哪些问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



