MySQL逻辑备份mysqldump 是我们平时用的比较多的备份方式,那么myqldump的备份原理是什么?是如何保证备份数据一致性的呢?
为了观察mysql在逻辑备份mysqldump 的时候,究竟做了哪些操作,我们开启全量日志!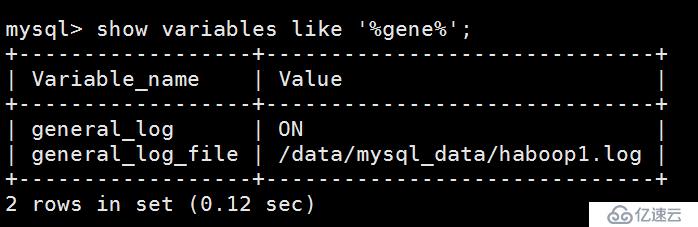
然后我们开始我们的备份操作:mysqldump -uroot -p123456 --master-data=2 --single-transaction -A >/tmp/yh2.sql
这里说说比较重要的两个参数:
--single-transaction 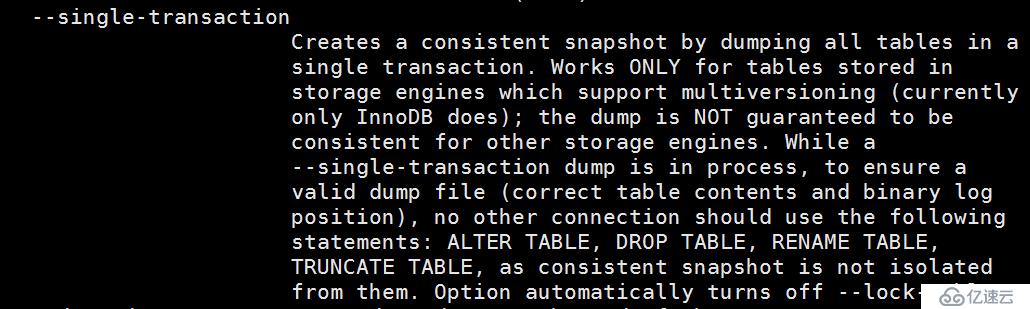
在开启dump操作时,会创建一个快照,这相当于此刻的一致性视图,即在整个dump的过程中是被当做一个事务的,这样就能保证同一事务下读取的数据都是一致的。但是此时如果有其他会话在做DDL操作(ALTER/DROP/RENAME/TRUNCATE TABLE),则会破坏数据的一致性,所以需要添加lock-tables锁住表用来保证数据的一致性。
--master-data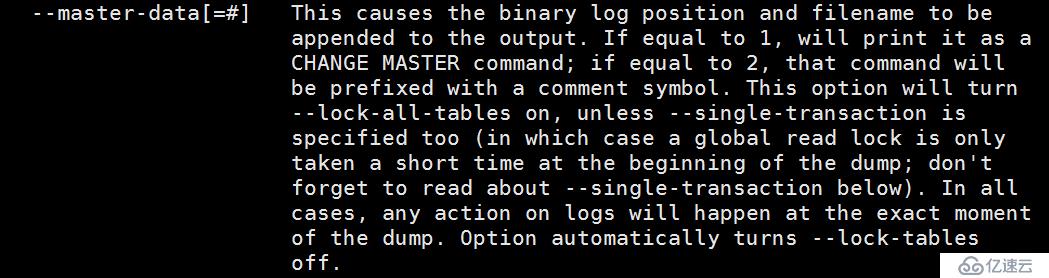
此命令是为了获取在dump时候的master 的binlog文件名和position的位置。当他等于1时,显示change master的输出结果。等于2时,注释掉此命令的输出结果。由此我们可以知道,当等于1时dump出来的数据,恢复在slave上是非常方便的。
现在我们查看刚才我们备份时候的全量日志,日质量比较打,我贴出部分主要的,
2017-12-07T07:32:24.917291Z 40 Connect root@localhost on using Socket
2017-12-07T07:32:24.917690Z 40 Query /!40100 SET @@SQL_MODE='' /
2017-12-07T07:32:24.926840Z 40 Query /!40103 SET TIME_ZONE='+00:00' /
2017-12-07T07:32:24.927033Z 40 Query FLUSH /!40101 LOCAL / TABLES
2017-12-07T07:32:24.928911Z 40 Query FLUSH TABLES WITH READ LOCK
2017-12-07T07:32:24.928994Z 40 Query SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ
2017-12-07T07:32:24.929079Z 40 Query START TRANSACTION /!40100 WITH CONSISTENT SNAPSHOT /
2017-12-07T07:32:24.929252Z 40 Query SHOW VARIABLES LIKE 'gtid_mode'
2017-12-07T07:32:24.992104Z 40 Query SELECT @@GLOBAL.GTID_EXECUTED
2017-12-07T07:32:24.992528Z 40 Query SHOW MASTER STATUS
2017-12-07T07:32:24.992613Z 40 Query UNLOCK TABLES
2017-12-07T07:32:24.992735Z 40 Query SELECT LOGFILE_GROUP_NAME, FILE_NAME, TOTAL_EXTENTS, INITIAL_SIZE, ENGINE, EXTRA FROM INFORMATION_SCHEMA.FILES WHERE FILE_TYPE = 'UNDO LOG' AND FILE_NAME IS NOT NULL AND LOGFILE_GROUP_NAME IS NOT NULL GROUP BY LOGFILE_GROUP_NAME, FILE_NAME, ENGINE, TOTAL_EXTENTS, INITIAL_SIZE ORDER BY LOGFILE_GROUP_NAME
2017-12-07T07:32:24.995255Z 40 Query SELECT DISTINCT TABLESPACE_NAME, FILE_NAME, LOGFILE_GROUP_NAME, EXTENT_SIZE, INITIAL_SIZE, ENGINE FROM INFORMATION_SCHEMA.FILES WHERE FILE_TYPE = 'DATAFILE' ORDER BY TABLESPACE_NAME, LOGFILE_GROUP_NAME
2017-12-07T07:32:24.996104Z 40 Query SHOW DATABASES
2017-12-07T07:32:24.997945Z 40 Query SHOW VARIABLES LIKE 'ndbinfo_version'
2017-12-07T07:32:24.999984Z 40 Init DB mysql
2017-12-07T07:32:25.000096Z 40 Query SHOW CREATE DATABASE IF NOT EXISTS mysql
2017-12-07T07:32:25.000211Z 40 Query SAVEPOINT sp
2017-12-07T07:32:25.000314Z 40 Query show tables
省略…………………………
2017-12-07T07:32:25.142111Z 40 Query use yhte
2017-12-07T07:32:25.142187Z 40 Query select @@collation_database
2017-12-07T07:32:25.142272Z 40 Query SHOW TRIGGERS LIKE 't'
2017-12-07T07:32:25.142579Z 40 Query SET SESSION character_set_results = 'utf8'
2017-12-07T07:32:25.142651Z 40 Query ROLLBACK TO SAVEPOINT sp
2017-12-07T07:32:25.142714Z 40 Query RELEASE SAVEPOINT sp
2017-12-07T07:32:25.142775Z 40 Init DB yhtest
2017-12-07T07:32:25.142830Z 40 Query SHOW CREATE DATABASE IF NOT EXISTS yhtest
2017-12-07T07:32:25.142991Z 40 Query SAVEPOINT sp
2017-12-07T07:32:25.143060Z 40 Query show tables
2017-12-07T07:32:25.143298Z 40 Query show table status like 't1'
2017-12-07T07:32:25.143799Z 40 Query SET SQL_QUOTE_SHOW_CREATE=1
2017-12-07T07:32:25.143872Z 40 Query SET SESSION character_set_results = 'binary'
2017-12-07T07:32:25.143972Z 40 Query show create table t1
2017-12-07T07:32:25.144064Z 40 Query SET SESSION character_set_results = 'utf8'
2017-12-07T07:32:25.144154Z 40 Query show fields from t1
2017-12-07T07:32:25.144543Z 40 Query show fields from t1
2017-12-07T07:32:25.144951Z 40 Query SELECT /!40001 SQL_NO_CACHE / FROM t1
2017-12-07T07:32:25.145135Z 40 Query SET SESSION character_set_results = 'binary'
2017-12-07T07:32:25.145207Z 40 Query use yhtest
2017-12-07T07:32:25.145282Z 40 Query select @@collation_database
2017-12-07T07:32:25.145366Z 40 Query SHOW TRIGGERS LIKE 't1'
2017-12-07T07:32:25.145668Z 40 Query SET SESSION character_set_results = 'utf8'
2017-12-07T07:32:25.145740Z 40 Query ROLLBACK TO SAVEPOINT sp
2017-12-07T07:32:25.145813Z 40 Query show table status like 't122'
2017-12-07T07:32:25.146389Z 40 Query SET SQL_QUOTE_SHOW_CREATE=1
2017-12-07T07:32:25.146464Z 40 Query SET SESSION character_set_results = 'binary'
2017-12-07T07:32:25.146533Z 40 Query show create table t122
2017-12-07T07:32:25.146621Z 40 Query SET SESSION character_set_results = 'utf8'
2017-12-07T07:32:25.146702Z 40 Query show fields from t122
2017-12-07T07:32:25.147099Z 40 Query show fields from t122
2017-12-07T07:32:25.147395Z 40 Query SELECT /!40001 SQL_NO_CACHE / FROM t122
2017-12-07T07:32:25.147545Z 40 Query SET SESSION character_set_results = 'binary'
2017-12-07T07:32:25.147615Z 40 Query use yhtest
2017-12-07T07:32:25.147690Z 40 Query select @@collation_database
2017-12-07T07:32:25.147771Z 40 Query SHOW TRIGGERS LIKE 't122'
2017-12-07T07:32:25.148128Z 40 Query SET SESSION character_set_results = 'utf8'
2017-12-07T07:32:25.148201Z 40 Query ROLLBACK TO SAVEPOINT sp
2017-12-07T07:32:25.148273Z 40 Query show table status like 'yh2'
2017-12-07T07:32:25.149056Z 40 Query SET SQL_QUOTE_SHOW_CREATE=1
2017-12-07T07:32:25.149129Z 40 Query SET SESSION character_set_results = 'binary'
2017-12-07T07:32:25.149199Z 40 Query show create table yh2
2017-12-07T07:32:25.149582Z 40 Query SET SESSION character_set_results = 'utf8'
2017-12-07T07:32:25.149665Z 40 Query show fields from yh2
2017-12-07T07:32:25.150010Z 40 Query show fields from yh2
2017-12-07T07:32:25.150293Z 40 Query SELECT /!40001 SQL_NO_CACHE / * FROM yh2
2017-12-07T07:32:25.150443Z 40 Query SET SESSION character_set_results = 'binary'
2017-12-07T07:32:25.150513Z 40 Query use yhtest
2017-12-07T07:32:25.150587Z 40 Query select @@collation_database
2017-12-07T07:32:25.150668Z 40 Query SHOW TRIGGERS LIKE 'yh2'
2017-12-07T07:32:25.151022Z 40 Query SET SESSION character_set_results = 'utf8'
2017-12-07T07:32:25.151096Z 40 Query ROLLBACK TO SAVEPOINT sp
2017-12-07T07:32:25.151158Z 40 Query RELEASE SAVEPOINT sp
2017-12-07T07:32:25.158814Z 40 Quit
通过全量日志,我们大致可以看出mysqldump的执行过程
1可以看出dump命令链接正式进入数据库。
2 flushtables操作。该操作会将内存中缓存的表结构数据同步到磁盘中。
3做了FLUSH TABLES WITH READ LOCK操作获得一个全局锁,确保此时数据是一致的。
4将当前会话的事务隔离级别恢复成默认的RR模式,使得当前事务可重复读。
5开启一个事务,并设置成快照级别。
6查询数据库的GTID是否开启。
7获取binlog的文件名及position的位置。
8释放全局锁。
9通过select语句查询test1库的状态。
10查询一下字典。
11进入要备份的test1库。
12查看建库语句。
13创建一个事务恢复点sp。
14查看需要备份的库中都有哪些表。
15查看表T1状态。
16设置表名和列名的格式。
17设置字符集为二进制。
18查看T1的建表语句。
19设置字符集为UTF8。
20输出表的所有信息。
21查询T1中数据,如果表中数据很大,mysql会使用limit来进行分段获取。
22设置字符集为二进制。
23进入test1库。
24查看数据库的编码格式。
25查看T1表的触发器。
26设置字符集为UTF8。
27ROLLBAKC到sp事务点。
28相同操作获取test1库中的T2表数据。
29当所有数据都获取完成后释放掉事务回滚点sp。
分析mysqldump过程:
FLUSH /!40101 LOCAL / TABLES
Closes all open tables, forces all tables in use to be closed, and flushes the query cache.
FLUSH TABLES WITH READ LOCK
执行flush tables操作,并加一个全局读锁,很多童鞋可能会好奇,这两个命令貌似是重复的,为什么不在第一次执行flush tables操作的时候加上锁呢?
下面看看源码中的解释:
/
We do first a FLUSH TABLES. If a long update is running, the FLUSH TABLES
will wait but will not stall the whole mysqld, and when the long update is
done the FLUSH TABLES WITH READ LOCK will start and succeed quickly. So,
FLUSH TABLES is to lower the probability of a stage where both mysqldump
and most client connections are stalled. Of course, if a second long
update starts between the two FLUSHes, we have that bad stall.
/
简而言之,是为了避免较长的事务操作造成FLUSH TABLES WITH READ LOCK操作迟迟得不到锁,但同时又阻塞了其它客户端操作。
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ
设置当前会话的事务隔离等级为RR,RR可避免不可重复读和幻读。
START TRANSACTION /!40100 WITH CONSISTENT SNAPSHOT /
获取当前数据库的快照,这个是由mysqldump中--single-transaction决定的。我们对比下加了该参数和没加的区别,日志如下:
有--single-transaction 参数: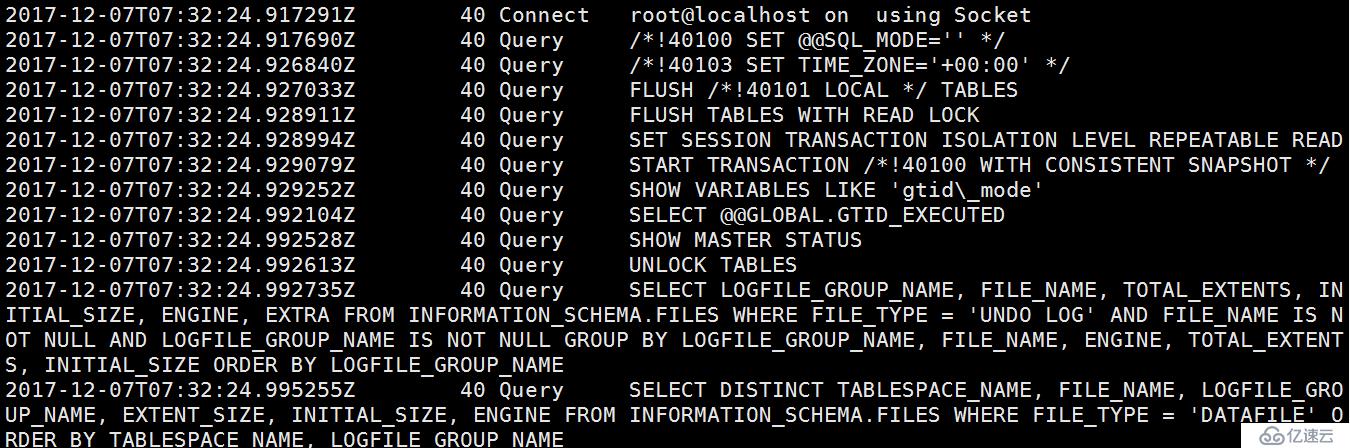
无--single-transaction 参数: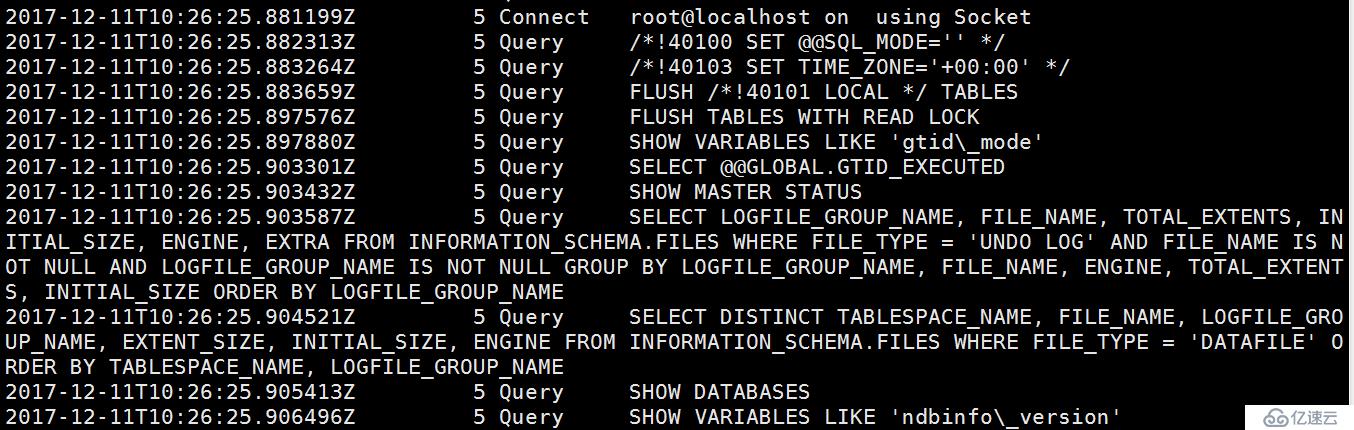
可以看到,当我们不加参数--single-transaction 参数时,将会少了对隔级别设置,少了开启事物一致性快照,少了unlock tables;
SHOW MASTER STATUS
这个是由--master-data决定的,记录了开始备份时,binlog的状态信息,包括MASTER_LOG_FILE和MASTER_LOG_POS
在备份过程中还有一个操作,设置保存点, 其实,这样做不会因为元数据锁阻塞在备份期间对已经备份表的ddl操作。
/
ROLLBACK TO SAVEPOINT in --single-transaction mode to release metadata
lock on table which was already dumped. This allows to avoid blocking
concurrent DDL on this table without sacrificing correctness, as we
won't access table second time and dumps created by --single-transaction
mode have validity point at the start of transaction anyway.
Note that this doesn't make --single-transaction mode with concurrent
DDL safe in general case. It just improves situation for people for whom
it might be working.*
/
模仿这个步骤测试一下
测试1:
隔离级别 RR模式,开启一个会话A执行如下操作: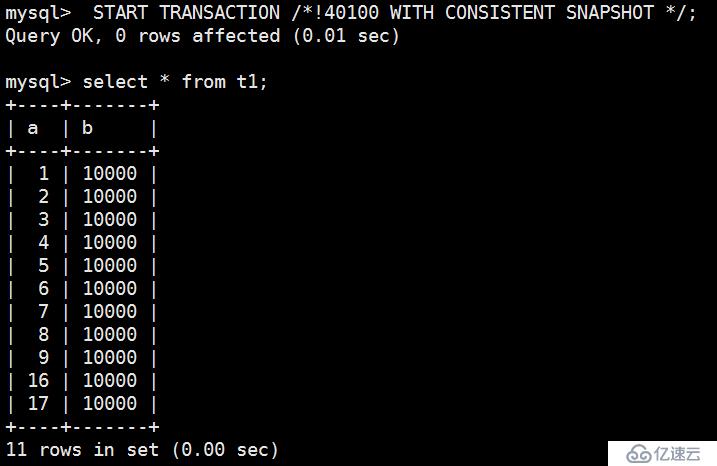
开启一个会话B执行如下操作:
开启一个会话C 查看状态,show processlist
我们可以看到,这样B会话是会被A会话元数据所阻塞的,这个时候,如果在有其他会话访问t1 表,同样会被B会话阻塞!
测试2
在A会话执行如下操作:
在B会话执行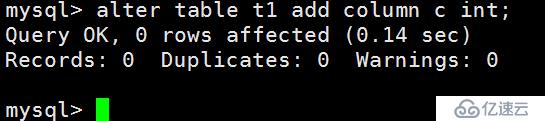
我们看到B会话的DDL操作是可以执行成功的。
在A会话执行 如下操作
在B会话执行
B会话也是可以执行成功的。
测试三:
A会话执行如下操作: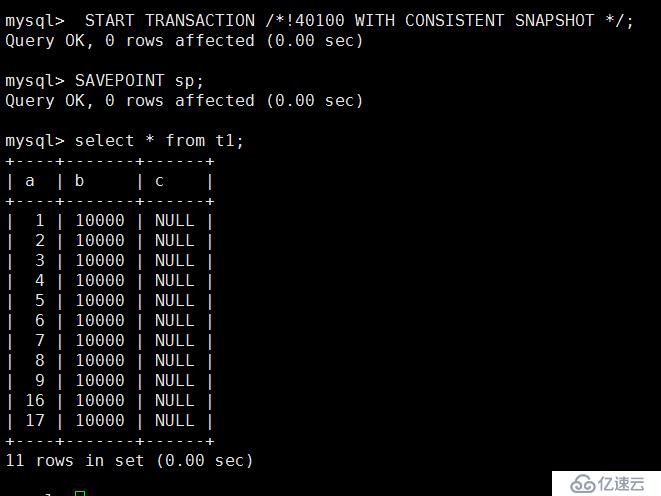
B会话执行
这个时候我们看出B会话被A会话阻塞,通过show processlist; 也可以看出B会话等待元数据锁,
我们在A会话跑 rollback to SAVEPOINT sp; 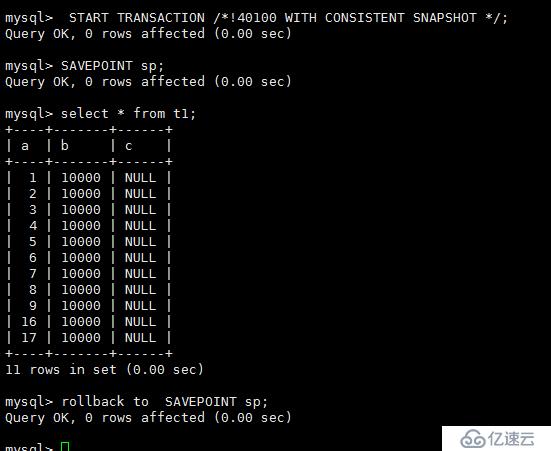
这个时候我们看到 B会话执行成功了
通过 SAVEPOINT sp; 设置保存点,通过rollback to SAVEPOINT sp; 相当于在select 完成后,立即释放了该表的元数据锁,而不会等到本次会话提交,这样可以避免DDL长时间无法获得元数据锁,从而导致该表的其他查询操作等待。
从这三个测试我们也可以看出START TRANSACTION WITH CONSISTENT SNAPSHOT开启的事务只能通过commit或者rollback来结束,而不是ROLLBACK TO SAVEPOINT sp。
需要注意的是,如果 alter table 发生在select from t1 之前,也就是第二种测试情况,DDL是可以提交成功的,那么我们再进行 select from t1 查询的时候,是会报错的,
发生在备份中,同样会报错!
总结:
至此,我们可以总结下mysqldump的备份原理:通过设置READ LOCK获取数据库全局锁后,RR事务隔离级别下记录当前的日志文件名和日志位置position,然后释放掉全局锁。接下来创建一个事务的回滚点,所有数据的获取都是获取的是这个sp回滚点数据。最后释放掉回滚点sp。当然,对于MyISAM存储引擎,备份是直接锁全表的。
值得注意点:从分析mysqldump过程中我们可以知道,此命令在开始时刻会带来数据库瞬时的锁定(FLUSHTABLES WITH READ LOCK),虽然锁定时间是非常短暂的,但是却会带来非常大的数据库隐患,因为在此过程中,如果执行有DDL语句,就会导致此命令堵塞并最终异常退出。所以在做备份时间节点的选择上,需要根据数据库环境选择在负载压力最小,且没有以上操作时候进行备份。
mysqldump的本质是通过select * from tab来获取表的数据的。
mysqldump的效率还是比较低下,START TRANSACTION /!40100 WITH CONSISTENT SNAPSHOT /只能等到所有表备份完后才结束,其实效率比较高的做法是备份完一张表就提交一次,这样可尽快释放Undo表空间快照占用的空间。但这样做,就无法实现对所有表的一致性备份。
为什么备份完成后没有commit操作
/*
No reason to explicitely COMMIT the transaction, neither to explicitely
UNLOCK TABLES: these will be automatically be done by the server when we
disconnect now. Saves some code here, some network trips, adds nothing to
server.
*/
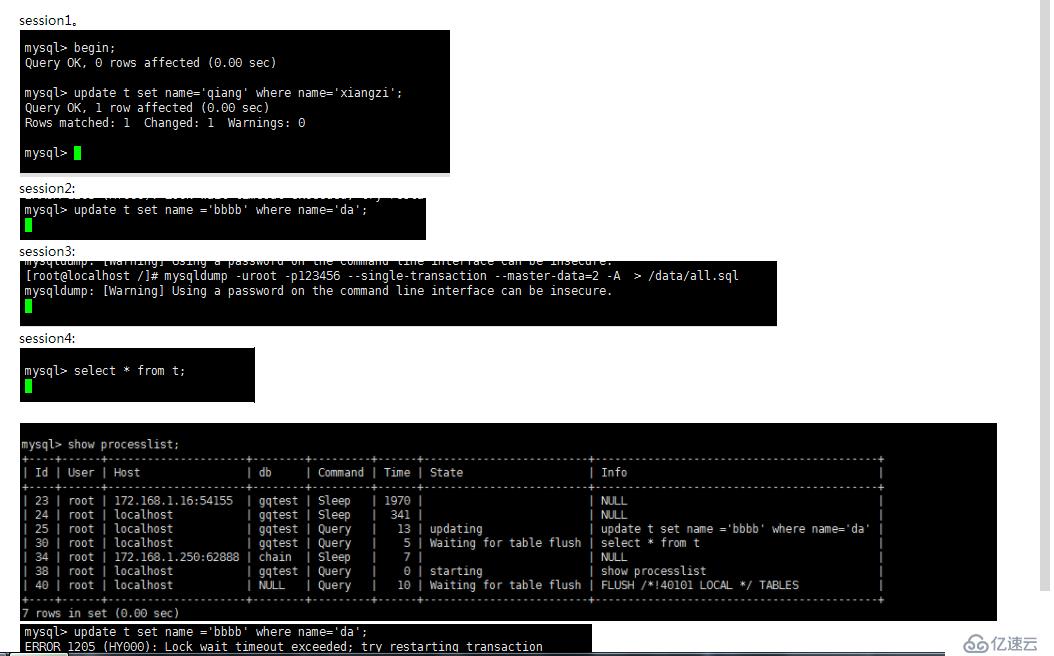
从以上截图可以看出,当我们开启第一个会话后,不进行提交,这个回收,第二个会话dump是 处于waiting for table flush 状态,第三个会话,读取和第一个会话同一张表的时候,也是会处于waiting for table flush 状态, 而不是被dump 阻塞, 当第三个会话读取其他表的时候,是可以正常读取的,也不会被dump阻塞
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





