/******************Oracle 高级分组*****************************/
/*-----------------auther:similarface-----------------------*/
/*--------------------2015年2月4日----------------------------*/
--oracle中GROUP BY中使用的列必须与select语句中没有使用聚合函数的列相匹配
/* Formatted on 2015/2/4 15:42:12(QP5 v5.256.13226.35538) */
SELECTd.dname,COUNT(e.empno)
FROMdeptd,empe
WHEREe.deptno(+)=D.DEPTNO
GROUPBYD.DNAME;
/* Formatted on 2015/2/4 15:47:45(QP5 v5.256.13226.35538) */
SELECTd.dname,COUNT(E.EMPNO)
FROMdeptd LEFTOUTERJOINempeONE.DEPTNO=D.DEPTNO
GROUPBYd.dname;
--GROUP BY 所产生的结果可以通过HAVING子句中所给出的筛选标准来进行限制
--需求:从有雇员以来的第一个完整年开始所有至少雇佣了5名员工的部门
/* Formatted on 2015/2/4 16:22:11(QP5 v5.256.13226.35538) */
SELECT D.DNAME,TRUNC(e.hiredate,'yyyy'),COUNT(e.empno)
FROMdeptd,empe
WHERE D.DEPTNO=E.DEPTNO
GROUPBYD.DNAME,TRUNC(e.hiredate,'yyyy')
HAVING COUNT(e.empno)>5
ANDTRUNC(e.hiredate,'yyyy')BETWEEN(SELECTMIN(hiredate)
FROMemp)
AND(SELECTMAX(hiredate)
FROMemp);
--CUBE将会使得对每一行都要考虑包含CUBE参数中所有可能的元素组合
CREATETABLEtestCube
(
num1 NUMBER,
num2 NUMBER
);
INSERTINTOtestCube
VALUES(1,2);
COMMIT;
SELECT*
FROMtestCube
GROUPBYCUBE(num1,num2);

--GROUPING可以排除cube生成的空值
SELECTDECODE(GROUPING(num1),1,'NUM1',num1),
DECODE(GROUPING(num2),1,'NUM2',num2)
FROMtestCube
GROUPBYCUBE(num1,num2);
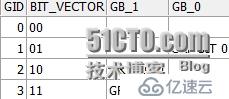
--GROUPING_ID确定其参数中的哪一行被用来生成超聚合行,然后创建一个位矢量以数值返回
WITH testGroupid AS(SELECT1 bit_1,0 bit_0 FROM DUAL),
cubed
AS( SELECTGROUPING_ID(bit_1,bit_0) gid,
TO_CHAR(GROUPING(bit_1))bv_1,
TO_CHAR(GROUPING(bit_0))bv_0,
DECODE(GROUPING(bit_1),1,'GRP BIT1') gb_1,
DECODE(GROUPING(bit_0),1,'GRP BIT0') gb_0
FROMtestGroupid
GROUPBYCUBE(bit_1,bit_0))
SELECTgid,
bv_1||bv_0 bit_vector,
gb_1,
gb_0
FROMcubed
ORDERBYgid;
GROUP BY 局限性
1、LOB列,嵌套表和数组不能使用GROUPBY
2、标量子查询表达式不允许
3、GROUP BY引用对象类型列不能并行化
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





