这篇文章主要为大家展示了“正则表达式匹配原理之逆序环视的示例分析”,内容简而易懂,条理清晰,希望能够帮助大家解决疑惑,下面让小编带领大家一起研究并学习一下“正则表达式匹配原理之逆序环视的示例分析”这篇文章吧。
说明:部分内容有待进一步研究和修正,因为最近工作太忙,暂时抽不出时间来,未研究过的可以跳过这一篇,想研究的不要被我的思路所左右了,有研究清楚的还请指正1 问题引出
前几天在CSDN论坛遇到这样一个问题:
var str="8912341253789";
需要将这个字符串中的重复的数字给去掉,也就是结果89123457。
首先需要说明的是,这种需求并不适合用正则来实现,至少,正则不是最好的实现方式。
这个问题本身不是本文讨论的重点,本文所要讨论的,主要是由这一问题的解决方案而引出的另一个正则匹配原理问题。
先看一下针对这一问题本身给出的解决方案。
代码如下:
string str = "8912341253789";
Regex reg = new Regex(@"((\d)\d*?)\2");
while (str != (str = reg.Replace(str, "$1"))) { }
richTextBox2.Text = str;
/*--------输出--------
89123457
*/
基于此有朋友提出另一个疑问,为什么使用下面的正则没有效果
“(?<=(?<value>\d).*?)\k<value>”
由此也引出本文所要讨论的逆序环视更深入的一些细节,涉及到逆序环视的匹配原理和匹配过程。前面的两篇博客中虽然也有介绍,但还不够深入,参考 正则基础之——环视 和 正则应用之——逆序环视探索 。本文将以逆序环视和反向引用结合这种复杂应用场景,对逆序环视进行深入探讨。
先把问题简化和抽象一下,上面的正则中用到了命名捕获组和命名捕捉组的反向引用,这在一定程度上增加了问题的复杂度,写成普通捕获组,并且用“\d”代替范围过大的“.”,如下
“(?<=(\d)\d*?)\1”
需要匹配的字符串,抽象一下,取两种典型字符串如下。
源字符串一:878
源字符串二:9878
与上面正则表达式类似,正则表达式相应的也有四种形式
正则表达式一:(?<=(\d)\d*)\1
正则表达式二:(?<=(\d)\d*?)\1
正则表达式三:(?<=(\d))\d*\1
正则表达式四:(?<=(\d))\d*?\1
先看一下匹配结果:
string[] source = new string[] {"878", "9878" };
List<Regex> regs = new List<Regex>();
regs.Add(new Regex(@"(?<=(\d)\d*)\1"));
regs.Add(new Regex(@"(?<=(\d)\d*?)\1"));
regs.Add(new Regex(@"(?<=(\d))\d*\1"));
regs.Add(new Regex(@"(?<=(\d))\d*?\1"));
foreach (string s in source)
{
foreach (Regex r in regs)
{
richTextBox2.Text += "源字符串: " + s.PadRight(8, ' ');
richTextBox2.Text += "正则表达式: " + r.ToString().PadRight(18, ' ');
richTextBox2.Text += "匹配结果: " + r.Match(s).Value + "\n------------------------\n";
}
richTextBox2.Text += "------------------------\n";
}
/*--------输出--------
源字符串: 878 正则表达式: (?<=(\d)\d*)\1 匹配结果: 8
------------------------
源字符串: 878 正则表达式: (?<=(\d)\d*?)\1 匹配结果:
------------------------
源字符串: 878 正则表达式: (?<=(\d))\d*\1 匹配结果: 78
------------------------
源字符串: 878 正则表达式: (?<=(\d))\d*?\1 匹配结果: 78
------------------------
------------------------
源字符串: 9878 正则表达式: (?<=(\d)\d*)\1 匹配结果:
------------------------
源字符串: 9878 正则表达式: (?<=(\d)\d*?)\1 匹配结果:
------------------------
源字符串: 9878 正则表达式: (?<=(\d))\d*\1 匹配结果: 78
------------------------
源字符串: 9878 正则表达式: (?<=(\d))\d*?\1 匹配结果: 78
------------------------
------------------------
*/
这个结果也许会出乎很多人的意料之外,刚开始接触这个问题时,我也一样感到迷惑,放了两天后,才灵机一触,想通了问题的关键所在,下面将展开讨论。
在此之前,可能还需要做两点说明:
1、 下面讨论的话题已经与本文开始提到的问题没有多大关联了,最初的问题主要是为了引出本文的话题,问题本身不在讨论范围之内,而本文也主要是纯理论的探讨。
2、 本文适合有一定正则基础的读者。如果您对上面几个正则的匹配结果和匹配过程感到费解,没关系,下面就将为您解惑;但是如果您对上面几个正则中元字符和语法代表的意义都不清楚的话,还是先从基础看起吧。
2 逆序环视匹配原理深入
正则表达式一:(?<=(\d)\d*)\1
正则表达式二:(?<=(\d)\d*?)\1
正则表达式三:(?<=(\d))\d*\1
正则表达式四:(?<=(\d))\d*?\1
上面的几个正则表达式,可以最终抽象为“(?<=SubExp1)SubExp2”这样的表达式,在做逆序环视原理分析时,根据“SubExp1”的特点,可以归纳为三类:
1、 逆序环视中的子表达式“SubExp1”长度固定,正则表达式三和四属于这一类,当然,这一类里是包括“?”这一量词的,但也仅限于这一个量词。
2、 逆序环视中的子表达式“SubExp1”长度不固定,其中包含忽略优先量词,如“*?”、“+?”、“{m,}?”等,也就是通常所说的非贪婪模式,正则表达式二属于这一类。
3、 逆序环视中的子表达式“SubExp1”长度不固定,其中包含匹配优先量词,“*”、“+”、“{m,}”等,也就是通常所说的贪婪模式,正则表达式一属于这一类。
下面针对这三类正则表达式进行匹配过程的分析。
2.1 固定长度子表达式匹配过程分析
2.1.1 源字符串一 + 正则表达式三匹配过程
源字符串一:878
正则表达式三:(?<=(\d))\d*\1
首先在位置0处开始尝试匹配,由“(?<=(\d))”取得控制权,长度固定,只有一位,由位置0处向左查找一位,失败,“(?<=(\d))”匹配失败,导致第一轮匹配尝试失败。
正则引擎传动装置向前传动,由位置1处尝试匹配,控制权交给“(?<=(\d))”,向左查找一位,接着将控制权交给“(\d)”,更进一步的将控制权交给“\d”。“\d”取得控制权后,向右尝试匹配,匹配“8”成功,此时“(?<=(\d))”匹配成功,匹配结果为位置1,捕获组1匹配到的内容就是“8”,控制权交给“\d*”。由于“\d*”为贪婪模式,会优先尝试匹配位置1后面的“7”和“8”,匹配成功,记录回溯状态,控制权交给“\1”。由于前面捕获组1捕获到的内容是“8”,所以“\1”要匹配到“8”才能匹配成功,而此时已到达字符串结尾处,匹配失败,“\d*”回溯,让出最后的字符“8”,再将控制权交给“\1”, 由“\1”匹配最后的“8”成功,此时整个表达式匹配成功。由于“(?<=(\d))”只匹配位置,不占有字符,所以整个表达式匹配到的结果为“78”,其中“\d*”匹配到的是“7”,“\1”匹配到的是“8”。
2.1.2 源字符串二 + 正则表达式三匹配过程
源字符串二:9878
正则表达式三:(?<=(\d))\d*\1
这一组合的匹配过程,与2.1.1节的匹配过程基本类似,只不过多了一轮匹配尝试而已,这里不再赘述。
2.1.3 源字符串一 + 正则表达式四匹配过程
源字符串一:878
正则表达式四:(?<=(\d))\d*?\1
首先在位置0处开始尝试匹配,由“(?<=(\d))”取得控制权,长度固定,只有一位,由位置0处向左查找一位,失败,“(?<=(\d))”匹配失败,导致第一轮匹配尝试失败。
正则引擎传动装置向前传动,由位置1处尝试匹配,控制权交给“(?<=(\d))”,向左查找一位,接着将控制权交给“(\d)”,更进一步的将控制权交给“\d”。“\d”取得控制权后,向右尝试匹配,匹配“8”成功,此时“(?<=(\d))”匹配成功,匹配结是果为位置1,捕获组1匹配到的内容就是“8”,控制权交给“\d*?”。由于“\d*?”为非贪婪模式,会优先尝试忽略匹配,记录回溯状态,控制权交给“\1”。由于前面捕获组1捕获到的内容是“8”,所以“\1”要匹配到“8”才能匹配成功,而此时位置1后面的字符是“7”,匹配失败,“\d*?”回溯,尝试匹配位置1后面的字符“7”,再将控制权交给“\1”, 由“\1”匹配最后的“8”成功,此时整个表达式匹配成功。由于“(?<=(\d))”只匹配位置,不占有字符,所以整个表达式匹配到的结果为“78”,其中“\d*?”匹配到的是“7”,“\1”匹配到的是最后的“8”。
这与2.1.1节组合的匹配过程基本一致,只不过就是“\d*”和“\d*?”匹配与回溯过程有所区别而已。
2.1.4 源字符串二 + 正则表达式四匹配过程
源字符串二:9878
正则表达式四:(?<=(\d))\d*?\1
这一组合的匹配过程,与2.1.3节的匹配过程基本类似,这里不再赘述。
2.2 非贪婪模式子表达式匹配过程分析
2.2.1 源字符串一 + 正则表达式二匹配过程
源字符串一:878
正则表达式二:(?<=(\d)\d*?)\1
首先在位置0处开始尝试匹配,由“(?<=(\d)\d*?)”取得控制权,长度不固定,至少一位,由位置0处向左查找一位,失败,“(?<=(\d)\d*?)”匹配失败,导致第一轮匹配尝试失败。
正则引擎传动装置向前传动,由位置1处尝试匹配,控制权交给“(?<=(\d)\d*?)”,向左查找一位,接着将控制权交给“(\d)”,更进一步的将控制权交给“\d”。“\d”取得控制权后,向右尝试匹配,匹配“8”成功,将控制权交给“\d*?”,由于“\d*?”为非贪婪模式,会优先尝试忽略匹配,即不匹配任何内容,并记录回溯状态,此时“(\d)\d*?”匹配成功,那么“(?<=(\d)\d*?)”也就匹配成功,匹配结果为位置1,由于此处的子表达式“(\d)\d*?”为非贪婪模式,取得一个成功匹配项后,即交出控制权,同时丢弃所有回溯状态。由于前面捕获组1捕获到的内容是“8”,所以“\1”要匹配到“8”才能匹配成功,而此时位置1后面的字符是“7”,此时已无可供回溯的状态,整个表达式在位置1处匹配失败。
正则引擎传动装置向前传动,由位置2处尝试匹配,控制权交给“(?<=(\d)\d*?)”,向左查找一位,接着将控制权交给“(\d)”,更进一步的将控制权交给“\d”。“\d”取得控制权后,向右尝试匹配,匹配“7”成功,将控制权交给“\d*?”,由于“\d*?”为非贪婪模式,会优先尝试忽略匹配,即不匹配任何内容,并记录回溯状态,此时“(\d)\d*?”匹配成功,那么“(?<=(\d)\d*?)”也就匹配成功,匹配结果为位置2,由于此处的子表达式“(\d)\d*?”为非贪婪模式,取得一个成功匹配项后,即交出控制权,同时丢弃所有回溯状态。由于前面捕获组1捕获到的内容是“7”,所以“\1”要匹配到“7”才能匹配成功,而此时位置2后面的字符是“7”,此时已无可供回溯的状态,整个表达式在位置2处匹配失败。
位置3处的匹配过程也同样道理,最后“\1”因无字符可匹配,导致整个表达式匹配失败。
此时已尝试了字符串所有位置,均匹配失败,所以整个表达式匹配失败,未取得任何有效匹配结果。
2.2.2 源字符串二 + 正则表达式二匹配过程
源字符串一:9878
正则表达式二:(?<=(\d)\d*?)\1
这一组合的匹配过程,与2.2.1节的匹配过程基本类似,这里不再赘述。
2.3 贪婪模式子表达式匹配过程分析
2.3.1 源字符串一 + 正则表达式一匹配过程
源字符串一:878
正则表达式二:(?<=(\d)\d*)\1
首先在位置0处开始尝试匹配,由“(?<=(\d)\d*)”取得控制权,长度不固定,至少一位,由位置0处向左查找一位,失败,“(?<=(\d)\d*)”匹配失败,导致第一轮匹配尝试失败。
正则引擎传动装置向前传动,由位置1处尝试匹配,控制权交给“(?<=(\d)\d*)”,向左查找一位,接着将控制权交给“(\d)”,更进一步的将控制权交给“\d”。“\d”取得控制权后,向右尝试匹配,匹配“8”成功,将控制权交给“\d*”,由于“\d*”为贪婪模式,会优先尝试匹配,并记录回溯状态,但此时已没有可用于匹配的字符,所以匹配失败,回溯,不匹配任何内容,丢弃回溯状态,此时“(\d)\d*”匹配成功,匹配内容为“8”,那么“(?<=(\d)\d*)”也就匹配成功,匹配结果是位置1,由于此处的子表达式为贪婪模式,“(\d)\d*”取得一个成功匹配项后,需要查找是否还有更长匹配,找到最长匹配后,才会交出控制权。再向左查找,已没有字符,“8”已是最长匹配,此时交出控制权,同时丢弃所有回溯状态。由于前面捕获组1捕获到的内容是“8”,所以“\1”要匹配到“8”才能匹配成功,而此时位置1后面的字符是“7”,此时已无可供回溯的状态,整个表达式在位置1处匹配失败。
正则引擎传动装置向前传动,由位置2处尝试匹配,控制权交给“(?<=(\d)\d*)”,向左查找一位,接着将控制权交给“(\d)”,更进一步的将控制权交给“\d”。“\d”取得控制权后,向右尝试匹配,匹配“7”成功,将控制权交给“\d*”,由于“\d*”为贪婪模式,会优先尝试匹配,并记录回溯状态,但此时已没有可用于匹配的字符,所以匹配失败,回溯,不匹配任何内容,丢弃回溯状态,此时“(\d)\d*”匹配成功,匹配内容为“7”,那么“(?<=(\d)\d*)”也就匹配成功,匹配结果是位置2,由于此处的子表达式为贪婪模式,“(\d)\d*”取得一个成功匹配项后,需要查找是否还有更长匹配,找到最长匹配后,才会交出控制权。再向左查找,由位置0处向右尝试匹配,“\d”取得控制权后,匹配位置0处的“8”成功,将控制权交给“\d*”,由于“\d*”为贪婪模式,会优先尝试匹配,并记录回溯状态,匹配位置1处的“7”成功,此时“(\d)\d*”匹配成功,那么“(\d)\d*”又找到了一个成功匹配项,匹配内容为“87”,其中捕获组1匹配到的是“8”。再向左查找,已没有字符,“87”已是最长匹配,此时交出控制权,同时丢弃所有回溯状态。由于前面捕获组1捕获到的内容是“8”,所以“\1”匹配位置2处的“8”匹配成功,此时整个有达式匹配成功。
演示例程中用的是Match,只取一次匹配项,事实上如果用的是Matches,正则表达式是需要尝试所有位置的,对于这一组合,同样道理,在位置3处,由于“\1”没有字符可供匹配,所以匹配一定是失败的。
至此,这一组合的匹配完成,有一个成功匹配项,匹配结果为“8”,匹配开始位置为位置2,也就是匹配到的内容为第二个“8”。
2.3.2 源字符串二 + 正则表达式一匹配过程
源字符串二:9878
正则表达式二:(?<=(\d)\d*)\1
首先在位置0处开始尝试匹配,由“(?<=(\d)\d*)”取得控制权,长度不固定,至少一位,由位置0处向左查找一位,失败,“(?<=(\d)\d*)”匹配失败,导致第一轮匹配尝试失败。
正则引擎传动装置向前传动,由位置1处尝试匹配,这一轮的匹配过程与2.3.1节的组合在位置1处的匹配过程类似,只不过“(\d)\d*”匹配到的是“9”,捕获组1匹配到的也是“9”,因此“\1”匹配失败,导致整个表达式在位置1处匹配失败。
正则引擎传动装置向前传动,由位置2处尝试匹配,这一轮的匹配过程与2.3.1节的组合在位置2处的匹配过程类似。首先“(\d)\d*”找到一个成功匹配项,匹配到的内容是“8”,捕捉组1匹配到的内容也是“8”,此时再向左尝试匹配,又找到一个成功匹配项,匹配到的内容是“98”,捕捉组1匹配到的内容也是“9”,再向左查找时,已无字符,所以“98”就是最长匹配项,“(?<=(\d)\d*)”匹配成功,匹配结果是位置2。由于此时捕获组1匹配的内容是“9”,所以“\1”在位置2处匹配失败,导致整个表达式在位置2处匹配失败。
正则引擎传动装置向前传动,由位置3处尝试匹配,这一轮的匹配过程与上一轮在位置2处的匹配过程类似。首先“(\d)\d*”找到一个成功匹配项“7”,继续向左尝试,又找到一个成功匹配项“87”,再向左尝试,又找到一个成功匹配项“987”,此时已为最长匹配,交出控制权,并丢弃所有回溯状态。此时捕获组1匹配的内容是“9” 所以“\1”在位置3处匹配失败,导致整个表达式在位置3处匹配失败。
位置4处最终由于“\1”没有字符可供匹配,所以匹配一定是失败的。
至此在源字符串所有位置的匹配尝试都已完成,整个表达式匹配失败,未找到成功匹配项。
2.4 小结
以上匹配过程分析,看似繁复,其实把握以下几点就可以了。
1、 逆序环视中子表达式为固定长度时,要么匹配成功,要么匹配失败,没什么好说的。
2、 逆序环视中子表达式为非贪婪模式时,只要找到一个匹配成功项,即交出控制权,并丢弃所有可供回溯的状态。
3、 逆序环视中子表达式为贪婪模式时,只有找到最长匹配成功项时,才会即交出控制权,并丢弃所有可供回溯的状态。
也就是说,对于正则表达式“(?<=SubExp1)SubExp2”,一旦“(?<=SubExp1)”交出控制权,那么它所匹配的位置就已固定,“SubExp1”所匹配的内容也已固定,并且没有可供回溯的状态了。
3 逆序环视匹配原理总结
再来总结一下正则表达式“(?<=SubExp1)SubExp2”的匹配过程吧。逆序环视的匹配原理图如下图所示。
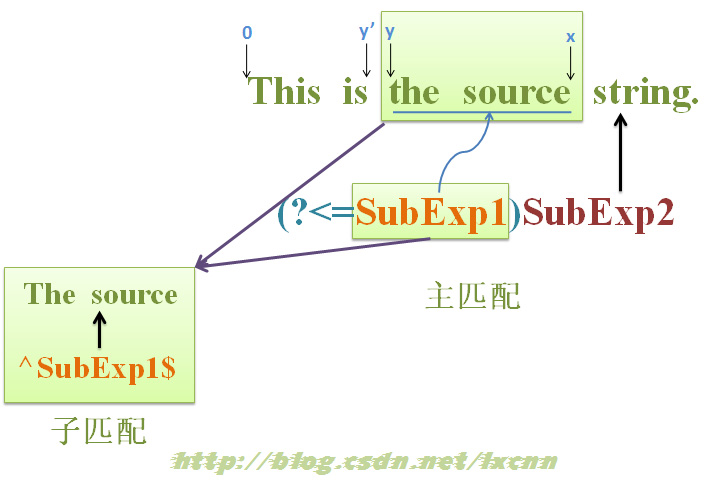
图3-1 逆序环视匹配原理图
正则表达式“(?<=SubExp1)SubExp2”的匹配过程,可分为主匹配流程和子匹配流程两个流程,主匹配流程如下图所示。
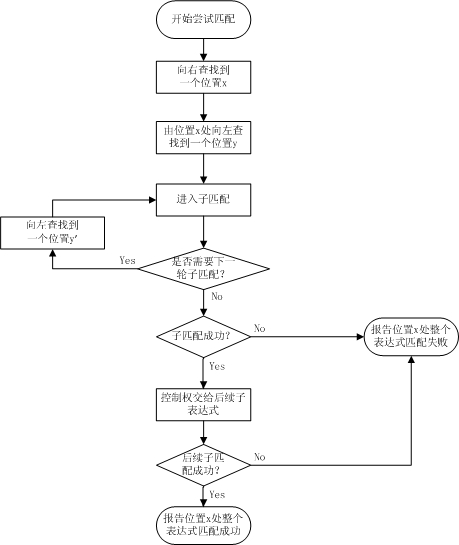
图3-2 主匹配流程图
主匹配流程:
1、 由位置0处向右尝试匹配,在找到满足“(?<=SubExp1)”最小长度要求的位置前,匹配一定是失败的,直到找到这样一个的位置x,x满足“(?<=SubExp1)”最小长度要求;
2、 从位置x处向左查找满足“SubExp1”最小长度要求的位置y;
3、 由“SubExp1”从位置y开始向右尝试匹配,此时进入一个独立的子匹配过程;
4、 如果“SubExp1”在位置y处子匹配还需要下一轮子匹配,则再向左查找一个y',也就是y-1重新进入独立的子匹配过程,如此循环,直到不再需要下一轮子匹配,子匹配成功则进入步骤5,最终匹配失败则报告整个表达式匹配失败;
5、 “(?<=SubExp1)”成功匹配后,控制权交给后面的子表达式“SubExp2”,继续尝试匹配,直到整个表达式匹配成功或失败,报告在位置x处整个表达式匹配成功或失败;
6、 如有必要,继续查找下一位置x',并开始新一轮尝试匹配。
子匹配流程如下图所示。
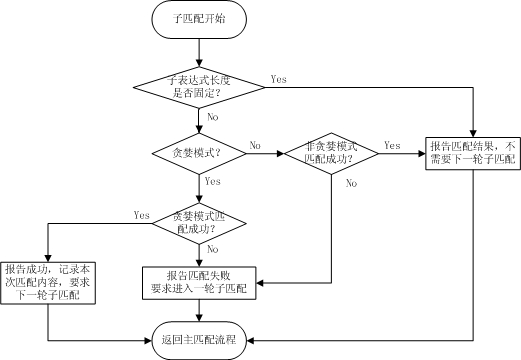
图3-3 子匹配流程图
子匹配过程:
1、 进入子匹配后,源字符串即已确定,也就是位置y和位置x之间的子字符串,而此时的正则表达式则变成了“^SubExp1$”,因为在这一轮子匹配当中,一旦匹配成功,则匹配开始位置一定是y,匹配结束位置一定是x;
2、 子表达式长度固定时,要么匹配成功,要么匹配失败,返回匹配结果,并且不需要下一轮子匹配;
3、 子表达式长度不固定时,区分是非贪婪模式还是贪婪模式;
4、 如果是非贪婪模式,匹配失败,报告失败,并且要求进行下一轮子匹配;匹配成功,丢弃所有回溯状态,报告成功,并且不再需要尝试下一轮子匹配;
5、 如果是贪婪模式,匹配失败,报告失败,并且要求进行下一轮子匹配;匹配成功,丢弃所有回溯状态,报告成功,记录本次匹配成功内容,并且要求尝试下一轮子匹配,直到取得最长匹配为止;
在特定的一轮匹配中,x的位置是固定的,而逆序环视中的子表达式“SubExp1”,在报告最终的匹配结果前,匹配开始的位置是不可预知的,需要经过一轮以上的子匹配才能确定,但匹配结束的位置一定是位置x。
当然,这只是针对特定的一轮匹配而言的,当这轮匹配失败,正则引擎传动装置会向前传动,使x=x+1,再进入下一轮匹配尝试,直到整个表达式报告匹配成功或失败为止。
至此逆序环视的匹配原理已基本上分析完了,当然,还有更复杂的,如“SubExp1”中既包含贪婪模式子表达式,又包含非贪婪模式子表达式,但无论怎样复杂,都是要遵循以上匹配原理的,所以只要理解了以上匹配原理,逆序环视也就没什么秘密可言了。
以上是“正则表达式匹配原理之逆序环视的示例分析”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



