线上IM消息的数据库,磁盘空间使用率已到达96%
没申请到扩容的新机器,无法做数据库迁移
保留的是全量聊天记录,一条都不许删
在这种场景下,为了减少空间容量,只能对表做碎片整理来释放空间, optimize table
当我们使用mysql进行delete数据,delete完以后,发现空间文件ibd并没有减少,这是因为碎片空间的存在,举个例子,一共公司有10号员工,10个座位,被开除了7个员工,但这些座位还是保留的,碎片整理就像,让剩下的3个员工都靠边坐,然后把剩下的7个作为给砸掉,这样就能释放出空间了
OPTIMIZE TABLE reorganizes the physical storage of table data and associated index data, to reduce storage space and improve I/O efficiency when accessing the table.
好处除了减少表数据与表索引的物理空间,还能降低访问表时的IO,这个比较理解,整理之前,取数据需要跨越很多碎片空间,这时需要时间的,整理后,想要的数据都放在一起了,直接拿就拿到了,效率提高
拿一张大表做碎片整理,整理之前是96G
[root@localhost myshard]# du -ch tbl_immsg_bigo_96.ibd |grep total
3.5G total当执行命令时
optimise table tbl_immsg_bigo_96;整理完后,剩下2.9G
myshard> optimize no_write_to_binlog table tbl_immsg_bigo_96;
+---------------------------+----------+----------+-------------------------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+---------------------------+----------+----------+-------------------------------------------------------------------+
| myshard.tbl_immsg_bigo_96 | optimize | note | Table does not support optimize, doing recreate + analyze instead |
| myshard.tbl_immsg_bigo_96 | optimize | status | OK |
+---------------------------+----------+----------+-------------------------------------------------------------------+
2 rows in set (3 min 21.66 sec)
[root@localhost myshard]# du -ch tbl_immsg_bigo_96.ibd |grep total
2.9G total整理期间会有很多慢查询的告警,在告一个waiting for table metadata lock的状态
ID: 121
USER: db_myshard_rw
HOST: 127.0.0.1:56326
DB: myshard
COMMAND: Execute
TIME: 1214
STATE: Waiting for table metadata lock
INFO: insert into myshard.tbl_immsg_bigo_0 (touid,fromuid,fromseqid,appid
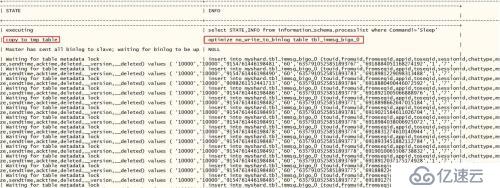
这是因为optimize table的本质,是alter table
mysql 5.5 的改表过程如下
1.创建一张新的临时表 tmp
2.把旧表锁住,禁止插入删除,只允许读写 (这就是为什么上面的insert语句都停留在waiting for table metadata lock)
3.把数据不断的从旧表,拷贝到新的临时表,(这就是上面报copy to tmp table)
4.等表拷贝完后,进行瞬间的rename操作
5.旧表删除掉
所以optimize最大的问题是锁表,锁表会导致insert,delete,update语句堵住,上面等待了1214秒,还在继续,所以第一个结论:在使用optimize table的时候,确保不要有任何dml语句,确保业务切走,否则可能会出事故
为什么要锁表呢?
alter过程里,数据不停从旧表拷贝到新表,如果这个时候旧表被delete了数据了,那旧表与新表的数据就不一致了,到最后rename 新表 to 旧表表名 时候,数据量就多了
如果在拷贝数据的过程中,对旧表数据的delete,同时对新表也做delete,那数据就一致了,对于update和insert也一样,这个功能可以通过 insert触发器,delete触发器,update触发器实现
pt-online-schema-change就利用3个触发器完成在线改表,也能完成在线碎片整理,命令使用
--alter="ENGINE=InnoDB"相当于optimize table的效果
具体命令如下,最好放在脚本里面实现,因为一次不止整理一个表,可以把整个数据库的表都碎片整理
pt-online-schema-change
-h地址
-P端口号
-u用户名
-p密码
--database=数据库
t=表名字
--charset=utf8
--max-lag=300
--check-interval=5
--alter="ENGINE=InnoDB"
--max-load="Threads_running:400"
--critical-load="Threads_running:400"
--nocheck-replication-filters
--alter-foreign-keys-method=auto
--execute使用pt-online-schema-change可以跳过锁表的坑
为了保持两张表的数据一致性,拷贝的那部分数据需要上锁,使用共享锁share_mode来锁行,可以通过show full processlist看到一次大概对10万行,每次拷贝1秒不到
INSERT LOW_PRIORITY IGNORE INTO `myshard`.`_tbl_immsg_bigo_128_new` (`sid`, `tm_timestamp`, `tm_lasttime`, `gid`, `group_name`, `default_flag`, `group_attr`, `group_owner`, `group_extension`, `is_del`, `app_id`, `mic_seat`, `invite_perm`, `invite_media_perm`, `pub_id_search`, `apply_verify`, `public_id`, `introduc`, `family_id`, `__version`, `__deleted`) SELECT `sid`, `tm_timestamp`, `tm_lasttime`, `gid`, `group_name`, `default_flag`, `group_attr`, `group_owner`, `group_extension`, `is_del`, `app_id`, `mic_seat`, `invite_perm`, `invite_media_perm`, `pub_id_search`, `apply_verify`, `public_id`, `introduc`, `family_id`, `__version`, `__deleted` FROM `myshard`.`tbl_immsg_bigo_128` FORCE INDEX(`PRIMARY`) WHERE ((`sid` >= '2112908055')) AND ((`sid` <= '2112916949')) LOCK IN SHARE MODE /*pt-online-schema-change 119079 copy nibble*/
本来使用碎片整理是因为磁盘使用率96%,但碎片整理时发现磁盘使用率变成99%,差点就爆了
Filesystem Size Used Avail Use% Mounted on /dev/sda2 58G 2.7G 53G 5% / tmpfs 24G 0 24G 0% /dev/shm /dev/sda1 485M 32M 428M 7% /boot /dev/sda5 1.6T 452G 1.1T 31% /data /dev/sdb1 1.3T 1.2T 25G 99% /data1
这是因为在把旧表拷贝到临时表的时,会把表数据复制一份数据,10G的表,可能复制出来是7G,这个过程磁盘会快速消耗,不小心就会把磁盘撑满造成数据丢失了
为了避免这个坑,应该把整个数据库的表,按照体积从小到大排序,并且把索引文件,表结构去掉,为了方便显示出体积,这里加了一个l参数,实际上是不加的,只获取表名字,然后重定向一个文件里,碎片整理就按照这个顺序
ls -lSr --ignore="*.frm"
-rw-rw---- 1 mysql mysql 4096 Jul 25 12:33 tables_priv.MYI
-rw-rw---- 1 mysql mysql 4096 Jul 25 12:33 procs_priv.MYI
-rw-rw---- 1 mysql mysql 4096 Jul 25 12:33 columns_priv.MYI
-rw-rw---- 1 mysql mysql 5120 Jul 25 12:33 proxies_priv.MYI
-rw-rw---- 1 mysql mysql 5120 Jul 25 12:43 db.MYI
-rw-rw---- 1 mysql mysql 8928 Jul 25 12:33 help_relation.MYD
-rw-rw---- 1 mysql mysql 16384 Jul 25 12:33 help_keyword.MYI
-rw-rw---- 1 mysql mysql 18432 Jul 25 12:33 help_relation.MYI
-rw-rw---- 1 mysql mysql 20480 Jul 25 12:33 help_topic.MYI
-rw-rw---- 1 mysql mysql 22078 Jul 25 12:33 help_category.MYD
-rw-rw---- 1 mysql mysql 89241 Jul 25 12:33 help_keyword.MYD
-rw-rw---- 1 mysql mysql 419392 Jul 25 12:33 help_topic.MYD可以写一个脚本,统计每个表整理的时间,整理前后的体积比较,效果如下
正在对表tbl_immsg_bigo_128进行碎片整理...第9张,还剩93张
+----------------------------+----------+----------+-------------------------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+----------------------------+----------+----------+-------------------------------------------------------------------+
| myshard.tbl_immsg_bigo_128 | optimize | note | Table does not support optimize, doing recreate + analyze instead |
| myshard.tbl_immsg_bigo_128 | optimize | status | OK |
+----------------------------+----------+----------+-------------------------------------------------------------------+
表:tbl_immsg_bigo_128, 整理前:3373M, 整理后:2729M, 节省空间:-644M,耗时:143秒
----------------------------------------------------------------------------------------------
正在对表tbl_immsg_bigo_132进行碎片整理...第10张,还剩92张
+----------------------------+----------+----------+-------------------------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+----------------------------+----------+----------+-------------------------------------------------------------------+
| myshard.tbl_immsg_bigo_132 | optimize | note | Table does not support optimize, doing recreate + analyze instead |
| myshard.tbl_immsg_bigo_132 | optimize | status | OK |
+----------------------------+----------+----------+-------------------------------------------------------------------+
表:tbl_immsg_bigo_132, 整理前:3541M, 整理后:2889M, 节省空间:-652M,耗时:153秒全部表整理完以后,96%的空间,碎片整理完后变成85%,腾出130G的空间
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



