新的一周,老张(superZS)再次与大家见面,我们又要面临快速的生活节奏而令人厌恶的工作!现在大多数人选择放松自己的方式就是玩游戏,最为突出的可能就要属手游"王者荣耀"。
据说这款游戏上到70旬老者,下至小学生都玩,老张我也玩。段位低得可怜(PS:最近刚玩哈),刚刚白银。
当时也想让别人带带我,说你只要给多少钱,就能快速带你从倔强青铜到最强王者,但最后我在装逼和省钱的抉择上,我选择了省钱。我心想就玩一个游戏,无非你就是比我玩的时间长,有技巧,有经验嘛,但凡我多花点时间,绝对比你玩的好。
话虽这么说,老张我也不喜欢把时间浪费在游戏上,但我喜欢抽时间写博文,给大家多分享知识。因为我认为技术重在交流,沟通,只有互相多学习,才能进步得更快!既然玩个游戏都可以分段位,那么我们所工作于技术这个领域更是层级分明。
虽然我不能教大家怎么在游戏中提升自己,但我可以给大家分享让自己在数据库领域里面级别提升。做一个人人敬仰的大神,一个最强的王者!
独家新课程上线>>MySQL体系结构深入剖析及实战DBA视频课程
MySQL 数据库知识脉络,大致可以分为四大模块:
● MySQL 体系结构;
● MySQL 备份恢复;
● MySQL 高可用集群;
● MySQL 优化。
从四大模块中,抽离7个部分给大家做分析
第一部分:倔强青铜篇
刚接触 MySQL 数据库的小白首先要了解,MySQL 常用操作命令以及 MySQL 各个版本的特点。从官方 5.1 到 MySQL 5.7,每个版本之间的跨度经历了哪些功能和性能上面的提升。
新特性参考博文>> http://sumongodb.blog.51cto.com/4979448/1949800
当然在这个阶段,我们也要学会如何安装 MySQL 数据库和一些常用命令的使用。
常用命令总结:
create database name; 创建数据库 use databasename; 选择数据库 drop database name; 直接删除数据库,不提醒 show tables; 显示表 describe tablename; 表的详细描述 select 中加上distinct去除重复字段 显示当前mysql版本和当前日期 select version(),current_date; 修改mysql中root的密码: shell>mysql -u root -p mysql> update user set password=password(“root123″) where user=’root’; mysql> flush privileges 刷新权限 mysql>use dbname; 打开数据库 mysql>show databases; 显示所有数据库 mysql>show tables; 显示数据库mysql中所有的表 mysql>desc user; 显示表mysql数据库中user表的列信息) grant 创建一个可以从任何地方连接到服务器的一个超管账户,必须分配一个密码 mysql> grant all privileges on *.* to 'user_name'@'localhost' identified by 'password' ; 格式:grant select on 数据库.* to 用户名@登录主机 identified by “密码” 删除授权: mysql> revoke all privileges on *.* from root@”%”; mysql> delete from user where user=”root” and host=”%”; mysql> flush privileges; 重命名表: mysql > alter table t1 rename t2; 备份: mysqldump -hhostname -uusername -ppassword databasename > backup.sql; 恢复: mysql -hhostname -uusername -ppassword databasename< backup.sql;
在这里举两个典型案例,MySQL 5.6 和 MySQL 5.7 在初始化数据时候的安装差异。
MySQL 5.6:初始化数据时需要进到家目录的 script 目录下
执行:
/usr/local/mysql/scripts/mysql_install_db --basedir=/usr/local/mysql/ --datadir=/data/mysql --defaults-file=/etc/my.cnf --user=mysql
此时数据库密码为空。
MySQL 5.7:初始化数据时需要进到家目录的 bin 目录下
执行:
/usr/local/mysql/bin/mysqld --user=mysql --datadir=/data/mysql --basedir=/usr/local/mysql/ --initialize
已然已经废弃了使用 mysql_install_db 这个命令进行初始化数据的操作了。
注:--initialize 会自动生成密码在 error log 里面。如果加 --initialize-insecure 密码为空
第二部分:秩序白银篇
大概了解完 MySQL 的安装,我们来介绍下 MySQL 的体系结构。先看下官方版本的图:
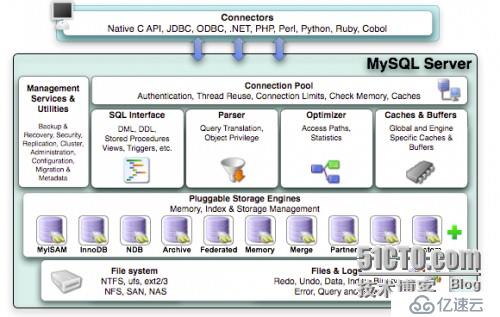
从图中我们可以看出:MySQL 体系结构分两部分(mysql server 层 + mysql 存储引擎层)
通过一条 sql 语句进入数据库的过程细分,又可以由8个小部分组成如下图:

1-6 都是经历 mysql-server 层部分,7 是我们数据库的存储引擎层部分。因此抛出了我们要学习各个存储引擎的区别。
这里只介绍两种最长使用的 Innodb 和 Myisam 区别
1. 事务的支持不同(innodb支持事务,myisam不支持事务)
2. 锁粒度(innodb行锁应用,myisam表锁)
3. 存储空间(innodb既缓存索引文件又缓存数据文件,myisam只能缓存索引文件)
4. 存储结构
(myisam:数据文件的扩展名为.MYD myData ,索引文件的扩展名是.MYI myIndex)
(innodb:所有的表都保存在同一个数据文件里面 即为.Ibd)
5. 统计记录行数
(myisam:保存有表的总行数,select count(*) from table;会直接取出出该值)
(innodb:没有保存表的总行数,select count(*) from table;就会遍历整个表,消耗相当大)
第三部分:荣耀黄金篇
想学好数据库,就要先学习体系结构。体系结构就好比房子的地基,如果地基不稳,是盖不了高楼的。由于在 mysql server 层各个版本之间差异不大,所以我主要研究存储引擎层部分。我们来看下 Innodb 的体系结构图:
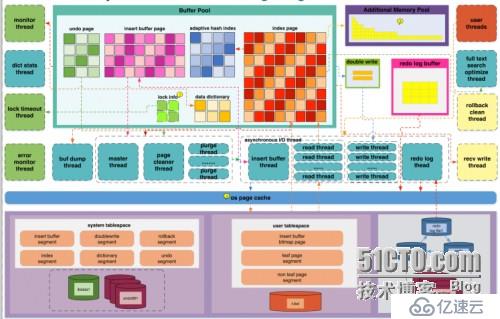
我们要学会把这体系结构分成主要的三大部分:内存组成 、线程工作、磁盘存储
在内存组成里面需要学习:数据库内存模块由 data_buffer,index_buffer,insert buffer,redo log buffer,double writer buffer 主要内存组成。
针对 Innodb 存储引擎的三大特性有:两次写,自适应哈希索引,插入缓冲;
1. double write(两次写)作用:可以保证页损坏之后,有副本直接可以进行恢复。
2. adaptive hash index(自适应哈希索引)作用:Innodb 存储引擎会监控对表上索引的查找,如果观察到建立哈希索引可以带来速度上的提升,则建立哈希索引。读写速度上也有所提高。
3. insert buffer (插入缓冲)作用:针对普通索引的插入把随机 IO 变成顺序 IO,并合并插入磁盘
——主要内存模块-->磁盘的刷新机制:
a. binlog cache--->binlog 文件
通过参数 sync_binlog 控制
这个参数是对于 MySQL 系统来说是至关重要的,他不仅影响到 Binlog 对 MySQL 所带来的性能损耗,而且还影响到 MySQL 中数据的完整性。对于“sync_binlog”参数的各种设置的说明如下:
● sync_binlog=0,当事务提交之后,MySQL 不做 fsync 之类的磁盘同步指令刷新 binlog_cache 中的信息到磁盘,而让 Filesystem 自行决定什么时候来做同步,或者 cache 满了之后才同步到磁盘。
● sync_binlog=n,当每进行 n 次事务提交之后,MySQL 将进行一次 fsync 之类的磁盘同步指令来将 binlog_cache 中的数据强制写入磁盘。
在 MySQL 中系统默认的设置是 sync_binlog=0,也就是不做任何强制性的磁盘刷新指令,这时候的性能是最好的,但是风险也是最大的。因为一旦系统 Crash,在 binlog_cache 中的所有 binlog 信息都会被丢失。
而当设置为“1”的时候,是最安全但是性能损耗最大的设置。因为当设置为 1 的时候,即使系统 Crash,也最多丢失 binlog_cache 中未完成的一个事务,对实际数据没有任何实质性影响。
从以往经验和相关测试来看,对于高并发事务的系统来说,“sync_binlog”设置为 0 和设置为 1 的系统写入性能差距可能高达5倍甚至更多。
b. redo log buffer--->redo log
通过参数 innodb_flush_log_at_trx_commit 控制
有三个参数值:
0:log buffer 将每秒一次地写入 log file 中,并且 log file 的 flush (刷到磁盘) 操作同时进行。该模式下在事务提交的时候,不会主动触发写入磁盘的操作。
1:每次事务提交时 mysql 都会把 log buffer 的数据写入 log file,并且 flush (刷到磁盘) 中去,该模式为系统默认。
2:每次事务提交时 mysql 都会把 log buffer 的数据写入 log file,但是 flush (刷到磁盘) 操作并不会同时进行。该模式下,MySQL 会每秒执行一次 flush (刷到磁盘) 操作
c. 脏页 data_buffer---->数据文件
1. 通过参数 innodb_max_dirty_pages_pct 控制:它的含义代表脏页刷新占 buffer_pool 的比例;个人建议调整为 25-50%;
2. 日志切换会产生检查点 checkpoint,可以诱发对脏页的刷新
——线程工作:
Innodb 四大 IO 线程:write thread,read thread,insert buffer thread,redo log thread
master thread 是数据库的主线程,优先级别最高,里面包含 1s 和 10s 对数据库的操作。
page cleaner thread:帮助刷新脏页的线程,5.7 版本可以增加多个。
purge thread :删除无用 undo 页。默认1个,最大可以调整到 32。
主要的数据文件也是我们需要学习:
参数文件:MySQL 5.6 版本 my.cnf 和 MySQL 5.7 版本的 my.cnf
这里给大家两个模板:老张根据生产环境上测试而出的参数。其中根据真实内存去适当调整 innodb_buffer_pool 大小就可以了。(建议物理内存的50-80%)
[client] port = 3306 socket = /tmp/mysql.sock #default-character-set=utf8 [mysql] #default-character-set=utf8 [mysqld] port = 3306 socket = /tmp/mysql.sock basedir = /usr/local/mysql datadir = /data/mysql open_files_limit = 3072 back_log = 103 max_connections = 512 max_connect_errors = 100000 table_open_cache = 512 external-locking = FALSE max_allowed_packet = 128M sort_buffer_size = 2M join_buffer_size = 2M thread_cache_size = 51 query_cache_size = 32M tmp_table_size = 96M max_heap_table_size = 96M slow_query_log = 1 slow_query_log_file = /data/mysql/slow.log log-error = /data/mysql/error.log long_query_time = 0.05 server-id = 1323306 log-bin = /data/mysql/mysql-bin sync_binlog = 1 binlog_cache_size = 4M max_binlog_cache_size = 128M max_binlog_size = 1024M expire_logs_days = 7 key_buffer_size = 32M read_buffer_size = 1M read_rnd_buffer_size = 16M bulk_insert_buffer_size = 64M character-set-server=utf8 default-storage-engine=InnoDB binlog_format=row #gtid_mode=on #log_slave_updates=1 #enforce_gtid_consistency=1 interactive_timeout=100 wait_timeout=100 transaction_isolation = REPEATABLE-READ innodb_additional_mem_pool_size = 16M innodb_buffer_pool_size = 1434M innodb_data_file_path = ibdata1:1024M:autoextend innodb_flush_log_at_trx_commit = 1 innodb_log_buffer_size = 16M innodb_log_file_size = 256M innodb_log_files_in_group = 2 innodb_max_dirty_pages_pct = 50 innodb_file_per_table = 1 innodb_locks_unsafe_for_binlog = 0 [mysqldump] quick max_allowed_packet = 32M
MySQL 5.7 版本的参数文件:
[client] port = 3306 socket = /data/mysql/mysql.sock [mysql] prompt="\u@db \R:\m:\s [\d]> " no-auto-rehash [mysqld] user = mysql port = 3306 basedir = /usr/local/mysql datadir = /data/mysql/ socket = /data/mysql/mysql.sock character-set-server = utf8mb4 skip_name_resolve = 1 open_files_limit = 65535 back_log = 1024 max_connections = 500 max_connect_errors = 1000000 table_open_cache = 1024 table_definition_cache = 1024 table_open_cache_instances = 64 thread_stack = 512K external-locking = FALSE max_allowed_packet = 32M sort_buffer_size = 4M join_buffer_size = 4M thread_cache_size = 768 query_cache_size = 0 query_cache_type = 0 interactive_timeout = 600 wait_timeout = 600 tmp_table_size = 32M max_heap_table_size = 32M slow_query_log = 1 slow_query_log_file = /data/mysql/slow.log log-error = /data/mysql/error.log long_query_time = 0.1 server-id = 3306101 log-bin = /data/mysql/mysql-binlog sync_binlog = 1 binlog_cache_size = 4M max_binlog_cache_size = 1G max_binlog_size = 1G expire_logs_days = 7 gtid_mode = on enforce_gtid_consistency = 1 log_slave_updates binlog_format = row relay_log_recovery = 1 relay-log-purge = 1 key_buffer_size = 32M read_buffer_size = 8M read_rnd_buffer_size = 4M bulk_insert_buffer_size = 64M lock_wait_timeout = 3600 explicit_defaults_for_timestamp = 1 innodb_thread_concurrency = 0 innodb_sync_spin_loops = 100 innodb_spin_wait_delay = 30 transaction_isolation = REPEATABLE-READ innodb_buffer_pool_size = 1024M innodb_buffer_pool_instances = 8 innodb_buffer_pool_load_at_startup = 1 innodb_buffer_pool_dump_at_shutdown = 1 innodb_data_file_path = ibdata1:1G:autoextend innodb_flush_log_at_trx_commit = 1 innodb_log_buffer_size = 32M innodb_log_file_size = 2G innodb_log_files_in_group = 2 innodb_max_undo_log_size = 4G innodb_io_capacity = 4000 innodb_io_capacity_max = 8000 innodb_flush_neighbors = 0 innodb_write_io_threads = 8 innodb_read_io_threads = 8 innodb_purge_threads = 4 innodb_page_cleaners = 4 innodb_open_files = 65535 innodb_max_dirty_pages_pct = 50 innodb_flush_method = O_DIRECT innodb_lru_scan_depth = 4000 innodb_checksum_algorithm = crc32 innodb_lock_wait_timeout = 10 innodb_rollback_on_timeout = 1 innodb_print_all_deadlocks = 1 innodb_file_per_table = 1 innodb_online_alter_log_max_size = 4G internal_tmp_disk_storage_engine = InnoDB innodb_stats_on_metadata = 0 innodb_status_file = 1 innodb_status_output = 0 innodb_status_output_locks = 0 performance_schema = 1 performance_schema_instrument = '%=on' [mysqldump] quick max_allowed_packet = 32M
——日志文件:
1. 错误日志 error log:对 mysql 启动,运行,关闭过程进行了记录。
2. 全量日志 general log:查询日志记录了所有对 mysql 数据库请求的信息,不论这些请求是否得到了正确的执行。
3. 二进制日志 binlog:记录了对数据库执行更改的所有操作。但是并不包括 select 和 show 这类操作。
4. 中继日志 relay log:主从同步,从库需要把主库传递过来的日志,记录到自己的 relay log 里面。
5. 慢查询日志 slow log:运行时间超过某值的所有 sql 语句都记录到慢查询日志文件中。
——对数据库的表设计也要学习清楚
数据类型的选择,主要参考官方文档:
https://downloads.mysql.com/docs/licenses/mysqld-5.7-com-en.pdf
——数据碎片的整理
产生碎片的原因:
1. 主要是因为对大表进行删除操作;
2. 其次随机方式插入新数据,可能导致辅助索引产生大量的碎片;
整理碎片的方法:
1. 备份数据表,导入导出,删除旧表
2. 执行 alter table table_name engine=innodb;
——收集统计信息
保证统计信息的准确性,才能确保我们的 sql 执行计划准确。收集方法:
1. 重启 mysql 服务
2. 遍历 tables 表
——学习分区表
分区表的种类:
1. range
2. list
3. hash
4. key
——学习对索引的认识
大致分为:
1. 如何查看数据库中索引:show index from table_name;
2. 学会查看数据库索引的选择性:select count(distinct c1)/count(*) from table_name; 选择性越高,越适合创建索引
3. 创建索引的过程中,学会查看执行计划。内功心法:先看 type 值,再看 key,再看 rows,最后看 extra;
mysql> use test; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> explain select * from sbtest; +----+-------------+--------+------+---------------+------+---------+------+-------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+------+---------------+------+---------+------+-------+-------+ | 1 | SIMPLE | sbtest | ALL | NULL | NULL | NULL | NULL | 98712 | NULL | +----+-------------+--------+------+---------------+------+---------+------+-------+-------+
4. 了解创建索引的好处
a. 提高数据检索效率
b. 提高聚合函数效率
c. 提高排序效率
d. 个别时候可以避免回表
e. 减少多表关联时扫描行数
f. 主键、唯一索引可以作为约束
——对事务的学习
先要知道事务的四大特性(ACID):
a. 原子性(Atomicity)
事务的原子性是指事务中包含的所有操作要么都做,要么都不做,保证数据库是一致的
b. 一致性(Consistency)
一致性是指数据库在事务操作前和事务处理后,其中的数据必须都满足业务规则约束.
c. 隔离性(Isolation)
隔离性是数据库允许多个并发事务同时对数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致.
d. 持久性(Durability)
事务处理结束后,对数据的修改就是永久的
熟悉 mysql 数据库四种事务隔离级别:
1. read uncommitted(RU)读未提交:
一个事务中,可以读取到其他事务未提交的变更
2. read committed(RC)读已提交:
一个事务中,可以读取到其他事务已经提交的变更
3. repetable read,(RR)可重复读:
一个事务中,直到事务结束前,都可以反复读取到事务刚开始看到的数据,不会发生变化
4. serializable(串行读):
即便每次读都需要获得表级共享锁,每次写都加表级排它锁,两个会话间读写会相互阻塞。
个人建议:对于交易类系统的网站,大家尽量使用事务级别比较高的RR;对于一些门户类网站大家使用RC就可以了。
Innodb 的锁,默认三种锁算法:
1. record;
2. Gap lock;
3. next-key lock
默认锁算法是 next-key lock 间隙锁保证不会出现幻读现象。
数据库字符集
先学会查看数据库的字符集:
[root@node3 ~]# mysql -uroot -proot123 mysql> show variables like '%char%'; +--------------------------+----------------------------------+ | Variable_name | Value | +--------------------------+----------------------------------+ | character_set_client | utf8 | | character_set_connection | utf8 | | character_set_database | utf8 | | character_set_filesystem | binary | | character_set_results | utf8 | | character_set_server | utf8 | | character_set_system | utf8 | | character_sets_dir | /usr/local/mysql/share/charsets/ | +--------------------------+----------------------------------+ 8 rows in set (0.00 sec)
如果想保证不会出现中文乱码的情况发生,必须满足以下三点:
1. 连接终端必须UTF8
2. 操作系统必须UTF8
3. 数据库必须UTF8
三者统一就不会出现中文乱码的问题
——数据库权限问题的管理
1. 权限申请流程要设置规范,合理.
2. 测试和正式环境都要严格控制数据库的写权限,禁止分配 create,alter 这样的权限给开发人员。并且读权限和外业务服务分离.
3. 领导需要权限时,问清目的,发邮件说明。尽量都由DBA全权管理
4. 特权账号 all privileges 必须由DBA人员控制
5. 单库单用户,禁止给我一个用户账号管理多个库。
6. 只读账号 select,可以后期配合主从架构中read_only 一起使用
7. 禁止 root 用户作为远程连接用户使用
第四部分:尊贵铂金篇
DBA 人员,如果不能保证数据的完整性,一切操作都是徒劳无功。所以备份的重要性可想而知。虽然备份不能带来业务上的提升,还会增加我们的成本。但是没有数据的完整性,无法保证我们线上业务的正常运行。是数据损坏时最后的一个救命稻草。
备份按方法分:冷备和热备
冷备:数据库关掉,影响业务。系统级别的文件 copy(PS:现在这种基本被废弃了)
热备:数据库在线备份,不影响现有业务的进行。
在热备里面又分为:
1. 逻辑备份
a. mysqldump
b. mydumper
c. mysqlpump(mysql 5.7才出现)
2. 裸文件备份
物理底层去 copy 文件,工具是 percona-xtrabackup
按内容又可以分为:全量备份、增量备份
生产中最常用的两种方法:
1. mysqldump
2. xtrabackup
mysqldump 参数详解:
--single-transaction 用于保证innodb备份数据一致性,配合RR隔离级别使用;当发起事务,读取一个快照版本,直到备份结束时,都不会读取到本事务开始之后提交的数据;(很重要) -q, --quick 加 SQL_NO_CACHE 标示符来确保不会读取缓存里的数据-l --lock-tables 发起 READ LOCAL LOCK锁,该锁不会阻止读,也不会阻止新的数据插入 --master-data 两个值 1和2,如果值等于1,就会添加一个CHANGE MASTER语句(后期配置搭建主从架构) 如果值等于2,就会在CHANGE MASTER语句前添加注释(后期配置搭建主从架构) -c, --complete-insert; 导出完整sql语句 -d,--no-data; 不导出数据,只导表结构 -t,--no-create-info; 只导数据,不导表结构 -w, --where=name ; 按条件导出想要的数据
备份数据库:
备份单个数据库或单个数据库中的指定表: mysqldump [OPTIONS] database [tb1] [tb2]… 备份多个数据库: mysqldump [OPTIONS] –databases [OPTIONS] DB1 [DB2 DB3...] 备份所有数据库: mysqldump [OPTIONS] –all-databases [OPTIONS] 利用mysql命令恢复数据: mysql -uroot -proot23 db_name < table_name.sql xtrabackup备份原理分析: 对于Innodb,它是基于Innodb的crash recovery功能进行备份。
数据库崩溃恢复原理介绍:Innodb 维护了一个 redo log,它记录着 Innodb 所有数据的真实修改信息,当数据库重启过程中,redo log 会应用所有已经提交的事务进行前滚,并把所有未提交的事务进行回滚,来保证宕机那一时刻的数据完整性。
XtraBackup 在备份的时候并不锁定表,而是一页一页地复制 InnoDB 的数据,与此同时,XtraBackup 还有另外一个线程监视着 transactions log,一旦 log 发生变化,就把变化过的 log pages 复制走。在全部数据文件复制完成之后,停止复制 logfile。
常用命令:
首先需要创建备份目录:/opt/data/ innobackupex --no-timestamp --defaults-file=/etc/my.cnf --user root --socket=/tmp/mysql.sock --password root123 /opt/data/all-20170719-bak 注--no-timestamp 该参数的含义:不需要系统创建时间目录,自己可以命名;
增备原理分析:
在完整备份和增量备份文件中都有一个文件 xtrabackup_checkpoints 会记录备份完成时检查点的LSN。在进行新的增量备份时,XtraBackup 会比较表空间中每页的 LSN 是否大于上次备份完成的 LSN,如果是,则备份该页,并记录当前检查点的 LSN。
7月20日的增备信息
[root@node3 all-20170720-incr]# cat xtrabackup_checkpoints backup_type = incremental from_lsn = 267719862 to_lsn = 267720940 last_lsn = 267720940 compact = 0
7月21日的增备信息
[root@node3 all-20170721-incr2]# cat xtrabackup_checkpoints backup_type = incremental from_lsn = 267720940 to_lsn = 267721260 last_lsn = 267721260 compact = 0
可以看出 7月20日 的结束 lsn 号(to_lsn)是 7月21日 的开始 lsn 号(from_lsn)。
增备常用命令:
7月20日的增量文件
./innobackupex --no-timestamp --user root --socket=/tmp/mysql.sock --password root123 --defaults-file=/etc/my.cnf --incremental --incremental-basedir=/opt/data/all-20170719-bak /data/xtrabackup/all-20170720-incr
注#--incremental-basedir:用来标识当前的增备从哪里开始
7月21日的增量文件
./innobackupex --no-timestamp --user root --socket=/tmp/mysql.sock --password root123 --defaults-file=/etc/my.cnf --incremental --incremental-basedir=/data/xtrabackup/all-20170720-incr /data/xtrabackup/all-20170721-incr2
完整备份集=全备+增备1+增备2
恢复操作:
innobackupex --user root --socket=/tmp/mysql.sock --password root123 --defaults-file=/etc/my.cnf --apply-log --redo-only +全备 innobackupex --user root --socket=/tmp/mysql.sock --password root123 --defaults-file=/etc/my.cnf --apply-log --redo-only 全备 --incremental-dir=增备1 innobackupex --user root --socket=/tmp/mysql.sock --password root123 --defaults-file=/etc/my.cnf --apply-log --redo-only 全备 --incremental-dir=增备2 innobackupex --user root --socket=/tmp/mysql.sock --password root123 --defaults-file=/etc/my.cnf --apply-log +全备
注# --redo-only代表只进行前滚操作
# --apply-log应用日志,保证数据的完整性
第五部分:永恒钻石篇
给大家介绍下企业中最常使用的主流 MySQL 高可用架构;
从两方面介绍
1. 基于主从复制
a. 双主M-M keepalived
b. MHA
2. 基于 Galera 协议;
M-M keepalived 双主架构:
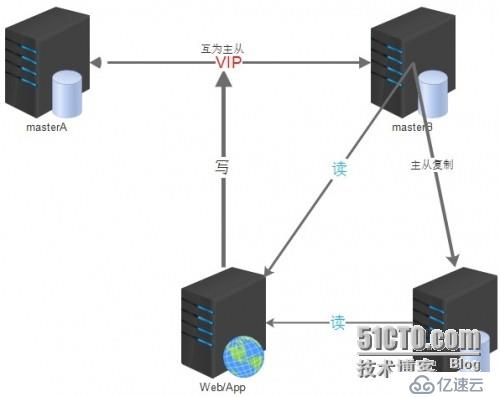
一般中小型公司都使用这种架构,搭建比较方便简单;可以采用主从或者主主模式,在 master 节点发生故障后,利用 keepalived 高可用机制实现快速切换到 slave 节点。原来的从库变成新的主库。
但针对这个架构,个人建议以下几点:
1. 一定要完善好切换脚本,keepalived 的切换机制要合理,避免切换不成功的现象发生。
2. 从库的配置尽快要与主库一致,不能太次;避免主库宕机发生切换,新的主库(原来的从库)影响线上业务进行。
3. 对于延迟的问题,在这套架构中,也不能避免。可以使用 mysql 5.7 中增强半同步完成。也可以改变架构使用 PXC,完成时时同步功能,基本上没有延迟;
4. keepalived 无法解决脑裂的问题,因此在进行服务异常判断时,可以修改我们的判断脚本,通过对第三方节点补充检测来决定是否进行切换,可降低脑裂问题产生的风险。
5. 采用 keepalived 这个架构,在设置两节点状态时,都要设置成不抢占模式,都是 backup 状态,通过优先级,来决定谁是主库。避免脑裂,冲突现象发生。
6. 安装好 mysql 需要的一些依赖包;建议配置好 yum 源,用 yum 安装 keepalived 即可。
MHA 架构:
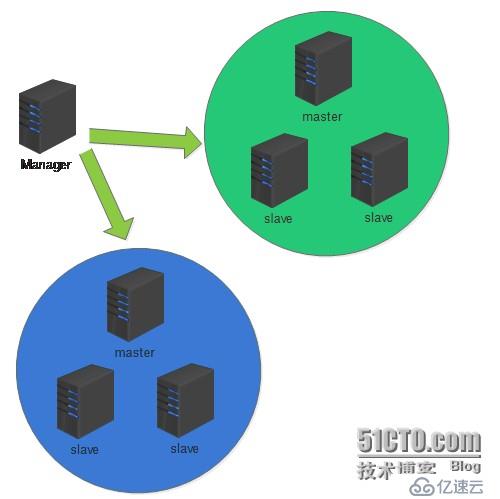
MySQL MHA 架构:可以说是企业最流行,用的最多的架构了。一些同学也经常问我相关的问题。
既然 MHA 这么火,那么它有什么优点呢?
1. 故障切换时,可以自行判断哪个从库与主库的数据最接近,就切换到上面,可以减少数据的丢失,保证数据的一致性
2. 支持 binlog server,可提高 binlog 传送效率,进一步减少数据丢失风险。
3. 可以配置 mysql 5.7 的增强半同步,来保证数据的时时同步
当然也会有一些比较棘手的缺点:
1. 自动切换的脚本太简单了,而且比较老化,建议后期逐渐完善。
2. 搭建 MHA 架构,需要开启 linux 系统互信协议,所以对于系统安全性来说,是个不小的考验。
PXC 架构:
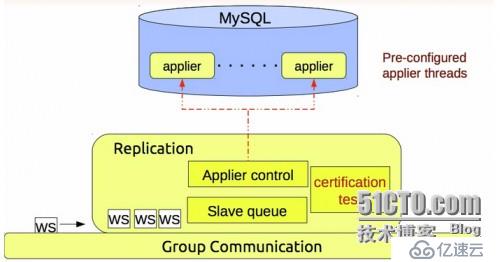
可以实现多个节点间的数据同步复制以及读写,并且可保障数据库的服务高可用及数据一致性。
PXC 基本就属于最完美的一套架构设计理念:
1. 主从同步,基本上无延迟;
2. 完全兼容MySQL
3. 新增节点进入到集群,部署起来很简单。
4. 服务高可用性可以保证,并且数据一致性更加严格;
第六部分:最强王者篇
进入到最后一个段位,在这里知识的高楼基本已经建成,我们需要做的就是一些高级优化操作了。
可以从四个部分来考虑优化的问题:程序设计角度、系统维度、数据库方面、硬件方向
参考老张我的博文《数据库优化之降龙十八掌》:
http://sumongodb.blog.51cto.com/4979448/1949024
今儿老张把 MySQL 由浅到深地向各位老铁们,介绍了一下。真的是希望大家可以抽出时间认真去阅读下,我写每篇文章都很用心,作为老师主要就是把知识和经验传递给那些正在处于迷茫中,或者把大部分时间都浪费在玩游戏身上的同学们。
希望这些知识对大家有帮助,大家有什么见解,我们可以一起讨论,共同进步。让我们的生活更加充实,让我们对技术更加热爱!(superZS老张的王者荣耀完结)
后期会出 MySQL 高可用架构三部曲系列,希望大家到时关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





