一、故障描述
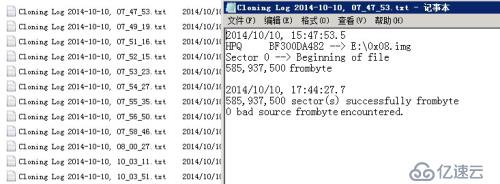
整个EVA存储结构是由一台EVA4400控制器,三台EVA4400扩展柜和28块FC 300G硬盘构成的。由于两块磁盘掉线导致存储某些LUN不可用,某些LUN丢失。由于EVA4400是因为某些磁盘掉线,从而导致整个存储不可用。因此接收到磁盘以后北亚工程师先对所有磁盘做物理检测,检测完后发现没有物理故障。接着使用坏道检测工具检测磁盘坏道,发现也没有坏道。磁盘坏道检测日志如下:
图一:
二、备份数据
考虑到数据的安全性以及可还原性,在做数据恢复之前需要对所有源数据做备份,以防万一操作不当导致数据无法再次恢复。使用winhex将所有磁盘都镜像成文件,源磁盘的内容数量多,在做数据备份的时候要花费很长时间。备份完部分数据如下:
图二:
三、故障分析及恢复过程
1、分析故障原因
由于前两个步骤并没有检测到磁盘有物理故障或者是坏道,由此推断可能是由于某些磁盘读写不稳定导致故障发生。因为EVA控制器检查磁盘的策略很严格,一旦某些磁盘性能不稳定,EVA控制器就认为是坏盘,就将认为是坏盘的磁盘踢出磁盘组。而一旦某个LUN的同一个条带中掉线的盘到达极限,那么这个LUN将不可用。即如果EVA中所有的LUN都包含这些掉线的盘,所有LUN都会受影响。掉线两块盘导致整个存储的LUN都不可用的情况就很正常了。而目前的情况是现存8个LUN,损坏7个LUN,丢失6个LUN。需要恢复所有LUN的数据。
2、分析LUN的结构
HP-EVA的LUN都是以RAID条目的形式存储数据的,EVA将每个磁盘的不同块组成一个RAID条目,RAID条目的类型可以有很多种。我们需要分析出组成LUN的RAID条目类型,以及这个RAID条目是由哪些盘的哪些块组成。这些信息都存放在LUN_MAP中,每个LUN都有一份LUN_MAP。EVA将LUN_MAP分别存放在不同的磁盘中,使用一个索引来指定其位置。因此去每个磁盘中找这个指向LUN_MAP的索引就可以找到现存LUN的信息了。
3、分析丢失的LUN
虽然磁盘中记录了指向LUN_MAP的索引,但是它只记录现存的LUN,丢失的LUN是不会记录索引的。由于EVA中删除一个LUN只会清除这个LUN的索引,而不会清除这个LUN的LUN_MAP。这时需要扫描所有磁盘找到所有符合LUN_MAP的数据块,然后排除掉现有的LUN_MAP,剩下的LUN_MAP也不一定全是删除的,也有一些是以前旧的,但此时是无法在LUN_MAP中筛选了,只能通过程序将所有LUN_MAP的数据都恢复出来,人工的去核对哪些LUN是删除的。
4、分析掉线磁盘
在前面的故障分析中说了,虽然磁盘没有明显的物理故障,也没有磁盘坏道。但还是会因为性能的原因从EVA磁盘组中脱离。而这些脱离的磁盘中都存放的是一些旧的数据,因此在生成数据的时候需要将这些磁盘都排除掉。但是如何判断哪些磁盘是掉线的呢?由于LUN的RAID结构大多都是RAID5,只需要将一个LUN的RAID条目通过RAID5的校验算法算出校验值,再和原有的校验值做比较就可以判断这个条目中是否有掉线盘。而将一个LUN的所有LUN_MAP都校验一遍就可以知道这个LUN中哪些RAID条目中有掉线盘。而这些RAID条目中都存在的那个盘就一定是掉线盘。排除掉线盘,然后根据LUN_MAP恢复所有LUN的数据即可。
5、编写数据恢复程序
上述的故障分析以及解决思路最终都需要使用编程来实现。编写扫描LUN_MAP的程序Scan_Map.exe,扫描全部LUN_MAP,结合人工分析得出最精确的LUN_MAP。编写检测RAID条目的程序Chk_Raid.exe,检测所有LUN中掉线的磁盘,结合人工分析排除掉线的磁盘。编写LUN数据恢复程序Lun_Recovery.exe,结合LUN_MAP恢复所有LUN数据。
6、恢复所有LUN数据
根据编写好的程序去实现不同的功能,最后使用Lun_Recovery.exe结合LUN_MAP恢复所有LUN的数据。然后人工核对每个LUN,确认是否和甲方工程师描述的一致。部分LUN的数据恢复如下:
图三:
四、数据验证
根据甲方工程师描述所有LUN的数据可以分成两大部份,一部份是Vmware的虚拟机,一部分是HP-UX上的裸设备,裸设备里存放的是Oracle的dbf数据库。由于我们恢复的是LUN,无法看到里面的文件,因此需要将这些LUN同过人工的核对哪些LUN是存放Vmware的数据,哪些是HP-UX的裸设备。然后将LUN挂载到不同的验证环境中验证恢复的数据是否完整。
1、部署Vmware虚拟机的验证环境
在一台dell的服务器上安装了ESXI5.5虚拟主机环境,然后通过iSCSI的方式将恢复的LUN挂载到虚拟主机上。但是在VMware vSphere Client 上扫描vmfs卷,没有发现。后来发现客户的虚拟主机是EXSI3.5的版本。可能因为版本的原因无法直接扫描到vmfs卷,于是换一种验证方式。将所有符合vmware虚拟机的LUN里面的虚拟机文件都生成出来,然后通过NFS共享的方式挂载到虚拟主机上,然后将虚拟机一个一个的添加到清单。恢复的部分虚拟机文件如下:
图四:

2、验证vmfs虚拟机
通过NFS将所有虚拟机都添加到虚拟主机以后,将所有虚拟机都加电开机,发现都能启动系统。由于没有开机密码无法确认虚拟机里面的文件是否完整。后来甲方安排工程师通过远程到我们的服务器,将所有虚拟机都开机进入系统,验证虚拟机里面的数据都没问题。虚拟机的所有数据都恢复成功。部分虚拟机开机如下:
图五:

3、部署Oracle数据库的验证环境
为了裸设备恢复测试和后期的数据验证工作,需要先搭建好oracle 环境。
根据甲方工程师提供的环境信息为HP小机Itanium架构,我公司HP小机为RX2660(Itanium 2), 是同架构的兼容版本。于是计划在此机器上安装 oracle 单实例软件。
操作系统:HP-UX B.11.31
数据库:Oracle 10.2.0.1.0 Enterprise Edition - 64bit for HPUX
以下是安装环境的简单步骤介绍:
(1) 环境检测
# uname -all
HP-UX byhpux1 B.11.31 U ia64 1447541358 unlimited-user license
本机为IA64架构,操作系统为 HP-UX ,版本为 B.11.31。
然后检查各部分存储空间信息,保证空间足够。
(2) 检测安装依赖包
根据安装说明“b19068.pdf”,检查 oracle10g 所需的补丁包。
检测:
# swlist-l bundle |grep "GOLD"
# swlist-l patch |grep PHNE_31097
如果没有检测到的,需要到官方网站下载并安装。 安装补丁包:
swinstall -s /patchCD/GOLDQPK11i -x autoreboot=true -x patch_match_target=true
(3) 创建用户及组
#groupadd dba
#useradd -g dba -d /home/oracle oracle
#passwd oracle
(4) 创建目录并修改权限
创建目录:
#mkdir –p/opt/oracle/product/10.2/oracledb
#chown -R oracle:dba/opt/oracle/frombyte.com
修改权限:
#chown oracle:dba/usr/oracle_inst/database/
#chmod 755/usr/oracle_inst/database/
(5) 设置环境变量
vi /home/oracle/.profile
(6)安装oracle
Oracle的安装要求起图形界面,所以要先测试图像界面能够正常启动。
#exoprt DISPLAY=192.168.0.1.0:0
$./runInstaller
图像界面起来之后的安装就比较简单了,这里只安装软件,不安装实例。
(7)测试数据库连接
#su - oracle
$sqlplus / as syssdba
4、验证Oracle数据库
(1)挂载裸设备
由于有部分LUN是裸设备,而我们恢复的LUN都是以文件的形式存在。因此需要将文件形式的LUN挂载到HP-UX上。在HP-UX服务器上安装iSCSI Initiator,安装步骤如下:
检测软件包是否完整
#swlist -d @ /tmp/B.11.31.03d_iSCSI-00_B.11.31.03d_HP-UX_B.11.31_IA_PA.depot
安装软件包
#swinstall -x autoreboot=true -s /tmp/B.11.31.03d_iSCSI-00_B.11.31.03d_HP-UX_B.11.31_IA_PA.depot iSCSI-00
将iSCSI的可执行文件添加到PATH
#PATH=$PATH:/opt/iscsi/bin/frombyte.com
检测iSCSI是否安装成功
#iscsiutil -l
配置iSCSI的启动器名称
#iscsituil /dev/iscsi -i -N iqn.2014-10-15:LUN
配置挂载目标iSCSI设备
#iscsiutil -a -I 10.10.1.9
删除目标iscsi设备
#iscsiutil -d -I 10.10.1.9
验证目标iSCSI是否挂载成功
#iscsiutil -pD
发现目标target设备
#/usr/sbin/ioscan -H 255
为目标创建设备文件
#/usr/sbin/insf -H 255
(2)导入外部VG信息
创建VG节点
#mkdir /dev/vgscope/frombyte.com
创建VG设备文件名
#mknod /dev/vgscope/group c 64 0x030000
查看PV是否正常
#pvdisplay -l /dev/dsk/c2t0d0/frombyte.com
将PV导入VG中
#vgimport -v /dev/vgscope /dev/dsk/c2t0d0
激活VG信息
#vgchange -a y vgscope
查看VG信息
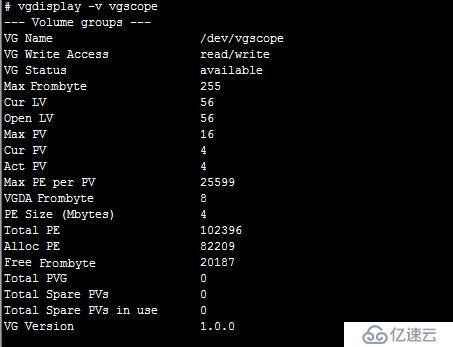
#vgdisplay -v vgscope
图六:
(3)修改LV名称
由于是在新的环境上重建的VG,然后再将PV导入到新建的VG中。因此LV的名称全部都改变了,需要手动的去将LV的名称都改成和以前一下的。
图七:
因为原来数据库实例是有2个,并且是使用的裸设备存储。所以在创建数据库实例时,要按按照原来配置和命名。
文件系统层面,在同时协助下,挂载了所有LV,并修改权限。
图八:
安装数据库实例,根据原始配置,在客户DBA协助下,安装并识别到所有裸设备文件。
然后调整配置参数,检测数据库存储状态,为启动数据库做准备。
首先切换到实例 scope(最重要)。,启动数据库。
SQL>startup mount;
SQL>select file#,error from v$recover_file; --查损坏的文件.
没有损坏的文件。
SQL>ALTER DATABASE OPEN;
启动没有报错,但是缓慢,之后查询了用户,随机查询了一个用户的两张表,数据结果集返回正常。然后连接突然中断,重新连接,查看状态为数据库关闭。再启动数据库,还是启动不了,会强制关闭。
经过初步检测和常规恢复库状态,不能修复此问题。
验证 NJYY 数据库
将环境变量切换到另一个数据库NJYY,open数据库时报错内存不足错误,不能开启数据库。经初步检测检测,数据文件没有损坏。
SQL>startup mount;
SQL>select file#,error from v$recover_file;
SQL>ALTER DATABASE OPEN;
error 4030 detected in background process
5、修复Oracle数据库
故障修复
对于scope数据库,根据上面的操作和故障现象,初步判断是undo表空间或者日志方面有问题。对数据文件做完整性和一致性检测,结果只有一个undo01.dbf文件损坏。确定是undo表空间损坏。通过命令删除掉损坏的undo表空间,又在原来位置重建。
检测其他部分文件,没有发现问题。重新启动数据库,正常启动,做查询数据,正常,做了完整性检测,正常。
接着做imp数据库全库导出,经过3个多小时正常导出全库数据库。
对于 NJYY数据库,检测到是内存空间设置不对,经过命令调整,数据库恢复正常,能正常启动,正常使用。
最后做imp数据库全库导出,经过4个多小时正常导出全库数据库。
具体验证
在完成初步验证之后,甲方要求其DBA和业务人员通过远程做数据库进一步具体验证。配合做了验证环境和各个数据库的验证。
最终验证数据库为完全恢复,没有问题。
在验证数据之后,做数据迁移。考虑到数据库的容量和恢复时间。选择用expdp来做全库数据的导出。因为expdp的效率比exp的高些。
编写好导出脚本,并在测试环境下测试没有问题后,先对scope数据库进行导出。导出开始后24分钟时,开始报错:
ORA-39171: Job is experiencing a resumable wait.
ORA-01654: unable to extend index SYSTEM.SYS_MTABLE_00003A964_IND_1 by 8 in tablespace SYSTEM
经过查找原因,得出是因为system表空间已满造成的。用expdp导出时会向system表空间里的SYSTEM.SYS_MTABLE_00003A964_IND_1表里加入导出记录数据.当导出大量数据时,此表的数据量就会增大,当达到system表空间的总容量时,就会报错。这里分析,表空间一般是会自动增加容量的,那样就不应该报错。最后查询出,system表空间是放在裸设备上的,容量为1G,且不可以增大。所以,就不能使用expdp工具做导出。 只能使用exp工具导出,虽然会慢一点,但是不会有system表空间不足的问题。
最后通过exp对scope做全库导出,经过6个多小时成功备份完成。备份文件达 172G。
对NJYY数据库,做imp导出,经过7个多小时正常导出全库数据库,备份文件达140G.接着对数据库备份文件做了本地备份,作为安全冷备份。
五、移交数据
1、移交vmware虚拟机文件和Oracle dump文件
验证所有数据没有问题后,将vmware虚拟机文件和Oracle dump文件拷贝至一块2TB的希捷硬盘中。然后再将恢复出来的LUN数据拷贝至两块3TB的单盘中。来到甲方现场后先将vmware虚拟机文件和Oracle dump文件交给甲方后,甲方开始验证dump文件和vmware虚拟机文件。
2、将LUN数据镜像到甲方的EVA4400存储服务器上
由于甲方要求将所有LUN数据恢复到原环境中,因此需要重新配置HP-EVA4400,重新创建和以前一样大小的LUN。然后通过winhex工具将恢复的LUN数据全部镜像到EVA新建的LUN中。由于甲方的HP-EVA4400的控制器存在一些问题导致调试了很久才重置HP-EVA4400。镜像完所有LUN数据后,甲方安排Oracle数据库工程师验证恢复的Oracle是否正常。检测后发现有两个dbf文件丢失导致Oracle服务启动失败,分析故障原因后发现,因为这两个丢失的dbf在EVA故障之前是以文件的方式存在,后来在恢复的时候,将其恢复到LV里面去了。而甲方工程师在恢复LV的时候并没有重建vg而是按照以前的vg_map恢复的所有LV。因此才会出现这个问题,解决办法,重新创建两个LV,然后从底层LUN中将这两个文件取出,将其dd到新创建的LV中。再次启动Oracle服务,启动正常,问题解决。
由于故障发生后保存现场环境良好,没有做相关危险的操作,对后期的数据恢复有很大的帮助。整个数据恢复过程中虽然遇到好多技术瓶颈,但也都一一解决。最终在预期的时间内完成整个数据恢复,恢复的数据甲方也相当满意。
日后数据安全建议
1、安排员工经常巡视机房,发现有报警信息及时处理。
2、管理人员操作存储要谨慎,避免误操作导致数据丢失。
3、现场发现EVA控制器部分模块不太稳定,应当及时更换。
4、由于EVA存储故障是由磁盘不稳定引起的,而这部分磁盘应该是同一批次的磁盘。因此,这些磁盘的性能也快到极限,如果有条件建议换掉这批磁盘。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





