C++дёӯе ҶдёҺж Ҳзҡ„еҢәеҲ«жңүе“Әдәӣ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңC++дёӯе ҶдёҺж Ҳзҡ„еҢәеҲ«жңүе“ӘдәӣвҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁC++дёӯе ҶдёҺж Ҳзҡ„еҢәеҲ«жңүе“Әдәӣй—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқC++дёӯе ҶдёҺж Ҳзҡ„еҢәеҲ«жңүе“ӘдәӣвҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
1.зЁӢеәҸеҶ…еӯҳеҲҶеҢәдёӯзҡ„е ҶдёҺж Ҳ
1.1 ж Ҳз®Җд»Ӣ
ж Ҳз”ұж“ҚдҪңзі»з»ҹиҮӘеҠЁеҲҶй…ҚйҮҠж”ҫ пјҢз”ЁдәҺеӯҳж”ҫеҮҪж•°зҡ„еҸӮж•°еҖјгҖҒеұҖйғЁеҸҳйҮҸзӯүпјҢе…¶ж“ҚдҪңж–№ејҸзұ»дјјдәҺж•°жҚ®з»“жһ„дёӯзҡ„ж ҲгҖӮеҸӮиҖғеҰӮдёӢд»Јз Ғпјҡ
int main() {
int b; //ж Ҳ
char s[] = "abc"; //ж Ҳ
char *p2; //ж Ҳ
}е…¶дёӯеҮҪж•°дёӯе®ҡд№үзҡ„еұҖйғЁеҸҳйҮҸжҢүз…§е…ҲеҗҺе®ҡд№үзҡ„йЎәеәҸдҫқж¬ЎеҺӢе…Ҙж ҲдёӯпјҢд№ҹе°ұжҳҜиҜҙзӣёйӮ»еҸҳйҮҸзҡ„ең°еқҖд№Ӣй—ҙдёҚдјҡеӯҳеңЁе…¶е®ғеҸҳйҮҸгҖӮж Ҳзҡ„еҶ…еӯҳең°еқҖз”ҹй•ҝж–№еҗ‘дёҺе ҶзӣёеҸҚпјҢз”ұй«ҳеҲ°еә•пјҢжүҖд»ҘеҗҺе®ҡд№үзҡ„еҸҳйҮҸең°еқҖдҪҺдәҺе…Ҳе®ҡд№үзҡ„еҸҳйҮҸпјҢжҜ”еҰӮдёҠйқўд»Јз ҒдёӯеҸҳйҮҸ s зҡ„ең°еқҖе°ҸдәҺеҸҳйҮҸ b зҡ„ең°еқҖпјҢp2 ең°еқҖе°ҸдәҺ s зҡ„ең°еқҖгҖӮж ҲдёӯеӯҳеӮЁзҡ„ж•°жҚ®зҡ„з”ҹе‘Ҫе‘ЁжңҹйҡҸзқҖеҮҪж•°зҡ„жү§иЎҢе®ҢжҲҗиҖҢз»“жқҹгҖӮ
1.2 е Ҷз®Җд»Ӣ
е Ҷз”ұејҖеҸ‘дәәе‘ҳеҲҶй…Қе’ҢйҮҠж”ҫпјҢ иӢҘејҖеҸ‘дәәе‘ҳдёҚйҮҠж”ҫпјҢзЁӢеәҸз»“жқҹж—¶з”ұ OS еӣһ收пјҢеҲҶй…Қж–№ејҸзұ»дјјдәҺй“ҫиЎЁгҖӮеҸӮиҖғеҰӮдёӢд»Јз Ғпјҡ
int main() {
// C дёӯз”Ё malloc() еҮҪж•°з”іиҜ·
char* p1 = (char *)malloc(10);
cout<<(int*)p1<<endl; //иҫ“еҮәпјҡ00000000003BA0C0
// з”Ё free() еҮҪж•°йҮҠж”ҫ
free(p1);
// C++ дёӯз”Ё new иҝҗз®—з¬Ұз”іиҜ·
char* p2 = new char[10];
cout << (int*)p2 << endl; //иҫ“еҮәпјҡ00000000003BA0C0
// з”Ё delete иҝҗз®—з¬ҰйҮҠж”ҫ
delete[] p2;
}е…¶дёӯ p1 жүҖжҢҮзҡ„ 10 еӯ—иҠӮзҡ„еҶ…еӯҳз©әй—ҙдёҺ p2 жүҖжҢҮзҡ„ 10 еӯ—иҠӮеҶ…еӯҳз©әй—ҙйғҪжҳҜеӯҳеңЁдәҺе ҶгҖӮе Ҷзҡ„еҶ…еӯҳең°еқҖз”ҹй•ҝж–№еҗ‘дёҺж ҲзӣёеҸҚпјҢз”ұдҪҺеҲ°й«ҳпјҢдҪҶйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢеҗҺз”іиҜ·зҡ„еҶ…еӯҳз©әй—ҙ并дёҚдёҖе®ҡеңЁе…Ҳз”іиҜ·зҡ„еҶ…еӯҳз©әй—ҙзҡ„еҗҺйқўпјҢеҚі p2 жҢҮеҗ‘зҡ„ең°еқҖ并дёҚдёҖе®ҡеӨ§дәҺ p1 жүҖжҢҮеҗ‘зҡ„еҶ…еӯҳең°еқҖпјҢеҺҹеӣ жҳҜе…Ҳз”іиҜ·зҡ„еҶ…еӯҳз©әй—ҙдёҖж—Ұиў«йҮҠж”ҫпјҢеҗҺз”іиҜ·зҡ„еҶ…еӯҳз©әй—ҙеҲҷдјҡеҲ©з”Ёе…ҲеүҚиў«йҮҠж”ҫзҡ„еҶ…еӯҳпјҢд»ҺиҖҢеҜјиҮҙе…ҲеҗҺеҲҶй…Қзҡ„еҶ…еӯҳз©әй—ҙеңЁең°еқҖдёҠдёҚеӯҳеңЁе…ҲеҗҺе…ізі»гҖӮе ҶдёӯеӯҳеӮЁзҡ„ж•°жҚ®иӢҘжңӘйҮҠж”ҫпјҢеҲҷе…¶з”ҹе‘Ҫе‘ЁжңҹзӯүеҗҢдәҺзЁӢеәҸзҡ„з”ҹе‘Ҫе‘ЁжңҹгҖӮ
е…ідәҺе ҶдёҠеҶ…еӯҳз©әй—ҙзҡ„еҲҶй…ҚиҝҮзЁӢпјҢйҰ–е…Ҳеә”иҜҘзҹҘйҒ“ж“ҚдҪңзі»з»ҹжңүдёҖдёӘи®°еҪ•з©әй—ІеҶ…еӯҳең°еқҖзҡ„й“ҫиЎЁпјҢеҪ“зі»з»ҹ收еҲ°зЁӢеәҸзҡ„з”іиҜ·ж—¶пјҢдјҡйҒҚеҺҶиҜҘй“ҫиЎЁпјҢеҜ»жүҫ第дёҖдёӘз©әй—ҙеӨ§дәҺжүҖз”іиҜ·з©әй—ҙзҡ„е ҶиҠӮзӮ№пјҢ然еҗҺе°ҶиҜҘиҠӮзӮ№д»Һз©әй—ІиҠӮзӮ№й“ҫиЎЁдёӯеҲ йҷӨпјҢ并е°ҶиҜҘиҠӮзӮ№зҡ„з©әй—ҙеҲҶй…Қз»ҷзЁӢеәҸгҖӮеҸҰеӨ–пјҢеҜ№дәҺеӨ§еӨҡж•°зі»з»ҹпјҢдјҡеңЁиҝҷеқ—еҶ…еӯҳз©әй—ҙдёӯзҡ„йҰ–ең°еқҖеӨ„и®°еҪ•жң¬ж¬ЎеҲҶй…Қзҡ„еӨ§е°ҸпјҢиҝҷж ·пјҢд»Јз Ғдёӯзҡ„deleteиҜӯеҸҘжүҚиғҪжӯЈзЎ®ең°йҮҠж”ҫжң¬еҶ…еӯҳз©әй—ҙгҖӮз”ұдәҺжүҫеҲ°зҡ„е ҶиҠӮзӮ№зҡ„еӨ§е°ҸдёҚдёҖе®ҡжӯЈеҘҪзӯүдәҺз”іиҜ·зҡ„еӨ§е°ҸпјҢзі»з»ҹдјҡиҮӘеҠЁең°е°ҶеӨҡдҪҷзҡ„йӮЈйғЁеҲҶйҮҚж–°ж”ҫе…Ҙз©әй—Ій“ҫиЎЁгҖӮ
1.3 е ҶдёҺж ҲеҢәеҲ«
е ҶдёҺж Ҳе®һйҷ…дёҠжҳҜж“ҚдҪңзі»з»ҹеҜ№иҝӣзЁӢеҚ з”Ёзҡ„еҶ…еӯҳз©әй—ҙзҡ„дёӨз§Қз®ЎзҗҶж–№ејҸпјҢдё»иҰҒжңүеҰӮдёӢеҮ з§ҚеҢәеҲ«пјҡ
пјҲ1пјүз®ЎзҗҶж–№ејҸдёҚеҗҢгҖӮж Ҳз”ұж“ҚдҪңзі»з»ҹиҮӘеҠЁеҲҶй…ҚйҮҠж”ҫпјҢж— йңҖжҲ‘们жүӢеҠЁжҺ§еҲ¶пјӣе Ҷзҡ„з”іиҜ·е’ҢйҮҠж”ҫе·ҘдҪңз”ұзЁӢеәҸе‘ҳжҺ§еҲ¶пјҢе®№жҳ“дә§з”ҹеҶ…еӯҳжі„жјҸпјӣ
пјҲ2пјүз©әй—ҙеӨ§е°ҸдёҚеҗҢгҖӮжҜҸдёӘиҝӣзЁӢжӢҘжңүзҡ„ж Ҳзҡ„еӨ§е°ҸиҰҒиҝңиҝңе°ҸдәҺе Ҷзҡ„еӨ§е°ҸгҖӮзҗҶи®әдёҠпјҢзЁӢеәҸе‘ҳеҸҜз”іиҜ·зҡ„е ҶеӨ§е°ҸдёәиҷҡжӢҹеҶ…еӯҳзҡ„еӨ§е°ҸпјҢиҝӣзЁӢж Ҳзҡ„еӨ§е°Ҹ 64bits зҡ„ Windows й»ҳи®Ө 1MBпјҢ64bits зҡ„ Linux й»ҳи®Ө 10MBпјӣ
пјҲ3пјүз”ҹй•ҝж–№еҗ‘дёҚеҗҢгҖӮе Ҷзҡ„з”ҹй•ҝж–№еҗ‘еҗ‘дёҠпјҢеҶ…еӯҳең°еқҖз”ұдҪҺеҲ°й«ҳпјӣж Ҳзҡ„з”ҹй•ҝж–№еҗ‘еҗ‘дёӢпјҢеҶ…еӯҳең°еқҖз”ұй«ҳеҲ°дҪҺгҖӮ
пјҲ4пјүеҲҶй…Қж–№ејҸдёҚеҗҢгҖӮе ҶйғҪжҳҜеҠЁжҖҒеҲҶй…Қзҡ„пјҢжІЎжңүйқҷжҖҒеҲҶй…Қзҡ„е ҶгҖӮж Ҳжңү2з§ҚеҲҶй…Қж–№ејҸпјҡйқҷжҖҒеҲҶй…Қе’ҢеҠЁжҖҒеҲҶй…ҚгҖӮйқҷжҖҒеҲҶй…ҚжҳҜз”ұж“ҚдҪңзі»з»ҹе®ҢжҲҗзҡ„пјҢжҜ”еҰӮеұҖйғЁеҸҳйҮҸзҡ„еҲҶй…ҚгҖӮеҠЁжҖҒеҲҶй…Қз”ұallocaеҮҪж•°иҝӣиЎҢеҲҶй…ҚпјҢдҪҶжҳҜж Ҳзҡ„еҠЁжҖҒеҲҶй…Қе’Ңе ҶжҳҜдёҚеҗҢзҡ„пјҢд»–зҡ„еҠЁжҖҒеҲҶй…ҚжҳҜз”ұж“ҚдҪңзі»з»ҹиҝӣиЎҢйҮҠж”ҫпјҢж— йңҖжҲ‘们жүӢе·Ҙе®һзҺ°гҖӮ
пјҲ5пјүеҲҶй…Қж•ҲзҺҮдёҚеҗҢгҖӮж Ҳз”ұж“ҚдҪңзі»з»ҹиҮӘеҠЁеҲҶй…ҚпјҢдјҡеңЁзЎ¬д»¶еұӮзә§еҜ№ж ҲжҸҗдҫӣж”ҜжҢҒпјҡеҲҶй…Қдё“й—Ёзҡ„еҜ„еӯҳеҷЁеӯҳж”ҫж Ҳзҡ„ең°еқҖпјҢеҺӢж ҲеҮәж ҲйғҪжңүдё“й—Ёзҡ„жҢҮд»Өжү§иЎҢпјҢиҝҷе°ұеҶіе®ҡдәҶж Ҳзҡ„ж•ҲзҺҮжҜ”иҫғй«ҳгҖӮе ҶеҲҷжҳҜз”ұC/C++жҸҗдҫӣзҡ„еә“еҮҪж•°жҲ–иҝҗз®—з¬ҰжқҘе®ҢжҲҗз”іиҜ·дёҺз®ЎзҗҶпјҢе®һзҺ°жңәеҲ¶иҫғдёәеӨҚжқӮпјҢйў‘з№Ғзҡ„еҶ…еӯҳз”іиҜ·е®№жҳ“дә§з”ҹеҶ…еӯҳзўҺзүҮгҖӮжҳҫ然пјҢе Ҷзҡ„ж•ҲзҺҮжҜ”ж ҲиҰҒдҪҺеҫ—еӨҡгҖӮ
пјҲ6пјүеӯҳж”ҫеҶ…е®№дёҚеҗҢгҖӮж Ҳеӯҳж”ҫзҡ„еҶ…е®№пјҢеҮҪж•°иҝ”еӣһең°еқҖгҖҒзӣёе…іеҸӮж•°гҖҒеұҖйғЁеҸҳйҮҸе’ҢеҜ„еӯҳеҷЁеҶ…е®№зӯүгҖӮеҪ“дё»еҮҪж•°и°ғз”ЁеҸҰеӨ–дёҖдёӘеҮҪж•°зҡ„ж—¶еҖҷпјҢиҰҒеҜ№еҪ“еүҚеҮҪж•°жү§иЎҢж–ӯзӮ№иҝӣиЎҢдҝқеӯҳпјҢйңҖиҰҒдҪҝз”Ёж ҲжқҘе®һзҺ°пјҢйҰ–е…Ҳе…Ҙж Ҳзҡ„жҳҜдё»еҮҪж•°дёӢдёҖжқЎиҜӯеҸҘзҡ„ең°еқҖпјҢеҚіжү©еұ•жҢҮй’ҲеҜ„еӯҳеҷЁзҡ„еҶ…е®№пјҲEIPпјүпјҢ然еҗҺжҳҜеҪ“еүҚж Ҳеё§зҡ„еә•йғЁең°еқҖпјҢеҚіжү©еұ•еҹәеқҖжҢҮй’ҲеҜ„еӯҳеҷЁеҶ…е®№пјҲEBPпјүпјҢеҶҚ然еҗҺжҳҜиў«и°ғеҮҪж•°зҡ„е®һеҸӮзӯүпјҢдёҖиҲ¬жғ…еҶөдёӢжҳҜжҢүз…§д»ҺеҸіеҗ‘е·Ұзҡ„йЎәеәҸе…Ҙж ҲпјҢд№ӢеҗҺжҳҜиў«и°ғеҮҪж•°зҡ„еұҖйғЁеҸҳйҮҸпјҢжіЁж„ҸйқҷжҖҒеҸҳйҮҸжҳҜеӯҳж”ҫеңЁж•°жҚ®ж®өжҲ–иҖ…BSSж®өпјҢжҳҜдёҚе…Ҙж Ҳзҡ„гҖӮеҮәж Ҳзҡ„йЎәеәҸжӯЈеҘҪзӣёеҸҚпјҢжңҖз»Ҳж ҲйЎ¶жҢҮеҗ‘дё»еҮҪж•°дёӢдёҖжқЎиҜӯеҸҘзҡ„ең°еқҖпјҢдё»зЁӢеәҸеҸҲд»ҺиҜҘең°еқҖејҖе§Ӣжү§иЎҢгҖӮе ҶпјҢдёҖиҲ¬жғ…еҶөе ҶйЎ¶дҪҝз”ЁдёҖдёӘеӯ—иҠӮзҡ„з©әй—ҙжқҘеӯҳж”ҫе Ҷзҡ„еӨ§е°ҸпјҢиҖҢе Ҷдёӯе…·дҪ“еӯҳж”ҫеҶ…е®№жҳҜз”ұзЁӢеәҸе‘ҳжқҘеЎ«е……зҡ„гҖӮ
д»Һд»ҘдёҠеҸҜд»ҘзңӢеҲ°пјҢе Ҷе’Ңж ҲзӣёжҜ”пјҢз”ұдәҺеӨ§йҮҸmalloc()/free()жҲ–new/deleteзҡ„дҪҝз”ЁпјҢе®№жҳ“йҖ жҲҗеӨ§йҮҸзҡ„еҶ…еӯҳзўҺзүҮпјҢ并且еҸҜиғҪеј•еҸ‘з”ЁжҲ·жҖҒе’Ңж ёеҝғжҖҒзҡ„еҲҮжҚўпјҢж•ҲзҺҮиҫғдҪҺгҖӮж ҲзӣёжҜ”дәҺе ҶпјҢеңЁзЁӢеәҸдёӯеә”з”Ёиҫғдёәе№ҝжіӣпјҢжңҖеёёи§Ғзҡ„жҳҜеҮҪж•°зҡ„и°ғз”ЁиҝҮзЁӢз”ұж ҲжқҘе®һзҺ°пјҢеҮҪж•°иҝ”еӣһең°еқҖгҖҒEBPгҖҒе®һеҸӮе’ҢеұҖйғЁеҸҳйҮҸйғҪйҮҮз”Ёж Ҳзҡ„ж–№ејҸеӯҳж”ҫгҖӮиҷҪ然ж Ҳжңүдј—еӨҡзҡ„еҘҪеӨ„пјҢдҪҶжҳҜз”ұдәҺе’Ңе ҶзӣёжҜ”дёҚжҳҜйӮЈд№ҲзҒөжҙ»пјҢжңүж—¶еҖҷеҲҶй…ҚеӨ§йҮҸзҡ„еҶ…еӯҳз©әй—ҙпјҢдё»иҰҒиҝҳжҳҜз”Ёе ҶгҖӮ
ж— и®әжҳҜе ҶиҝҳжҳҜж ҲпјҢеңЁеҶ…еӯҳдҪҝз”Ёж—¶йғҪиҰҒйҳІжӯўйқһжі•и¶Ҡз•ҢпјҢи¶Ҡз•ҢеҜјиҮҙзҡ„йқһжі•еҶ…еӯҳи®ҝй—®еҸҜиғҪдјҡ摧жҜҒзЁӢеәҸзҡ„е ҶгҖҒж Ҳж•°жҚ®пјҢиҪ»еҲҷеҜјиҮҙзЁӢеәҸиҝҗиЎҢеӨ„дәҺдёҚзЎ®е®ҡзҠ¶жҖҒпјҢиҺ·еҸ–дёҚеҲ°йў„жңҹз»“жһңпјҢйҮҚеҲҷеҜјиҮҙзЁӢеәҸејӮеёёеҙ©жәғпјҢиҝҷдәӣйғҪжҳҜжҲ‘们编зЁӢж—¶дёҺеҶ…еӯҳжү“дәӨйҒ“ж—¶еә”иҜҘжіЁж„Ҹзҡ„й—®йўҳгҖӮ
2.ж•°жҚ®з»“жһ„дёӯзҡ„е ҶдёҺж Ҳ
ж•°жҚ®з»“жһ„дёӯпјҢе ҶдёҺж ҲжҳҜдёӨдёӘеёёи§Ғзҡ„ж•°жҚ®з»“жһ„пјҢзҗҶи§ЈдәҢиҖ…зҡ„е®ҡд№үгҖҒз”Ёжі•дёҺеҢәеҲ«пјҢиғҪеӨҹеҲ©з”Ёе ҶдёҺж Ҳи§ЈеҶіеҫҲеӨҡе®һйҷ…й—®йўҳгҖӮ
2.1 ж Ҳз®Җд»Ӣ
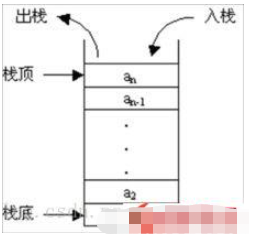
ж ҲжҳҜдёҖз§Қиҝҗз®—еҸ—йҷҗзҡ„зәҝжҖ§иЎЁпјҢе…¶йҷҗеҲ¶жҳҜжҢҮеҸӘд»…е…Ғи®ёеңЁиЎЁзҡ„дёҖз«ҜиҝӣиЎҢжҸ’е…Ҙе’ҢеҲ йҷӨж“ҚдҪңпјҢиҝҷдёҖз«Ҝиў«з§°дёәж ҲйЎ¶пјҲTopпјүпјҢзӣёеҜ№ең°пјҢжҠҠеҸҰдёҖз«Ҝз§°дёәж Ҳеә•пјҲBottomпјүгҖӮжҠҠж–°е…ғзҙ ж”ҫеҲ°ж ҲйЎ¶е…ғзҙ зҡ„дёҠйқўпјҢдҪҝд№ӢжҲҗдёәж–°зҡ„ж ҲйЎ¶е…ғзҙ з§°дҪңиҝӣж ҲгҖҒе…Ҙж ҲжҲ–еҺӢж ҲпјҲPushпјүпјӣжҠҠж ҲйЎ¶е…ғзҙ еҲ йҷӨпјҢдҪҝе…¶зӣёйӮ»зҡ„е…ғзҙ жҲҗдёәж–°зҡ„ж ҲйЎ¶е…ғзҙ з§°дҪңеҮәж ҲжҲ–йҖҖж ҲпјҲPopпјүгҖӮиҝҷз§ҚеҸ—йҷҗзҡ„иҝҗз®—дҪҝж ҲжӢҘжңүвҖңе…ҲиҝӣеҗҺеҮәвҖқзҡ„зү№жҖ§пјҲFirst In Last OutпјүпјҢз®Җз§°FILOгҖӮ
ж ҲеҲҶйЎәеәҸж Ҳе’Ңй“ҫејҸж ҲдёӨз§ҚгҖӮж ҲжҳҜдёҖз§ҚзәҝжҖ§з»“жһ„пјҢжүҖд»ҘеҸҜд»ҘдҪҝз”Ёж•°з»„жҲ–й“ҫиЎЁпјҲеҚ•еҗ‘й“ҫиЎЁгҖҒеҸҢеҗ‘й“ҫиЎЁжҲ–еҫӘзҺҜй“ҫиЎЁпјүдҪңдёәеә•еұӮж•°жҚ®з»“жһ„гҖӮдҪҝз”Ёж•°з»„е®һзҺ°зҡ„ж ҲеҸ«еҒҡйЎәеәҸж ҲпјҢдҪҝз”Ёй“ҫиЎЁе®һзҺ°зҡ„ж ҲеҸ«еҒҡй“ҫејҸж ҲпјҢдәҢиҖ…зҡ„еҢәеҲ«жҳҜйЎәеәҸж Ҳдёӯзҡ„е…ғзҙ ең°еқҖиҝһз»ӯпјҢй“ҫејҸж Ҳдёӯзҡ„е…ғзҙ ең°еқҖдёҚиҝһз»ӯгҖӮ
ж Ҳзҡ„з»“жһ„еҰӮдёӢеӣҫжүҖзӨәпјҡ
ж Ҳзҡ„еҹәжң¬ж“ҚдҪңеҢ…жӢ¬еҲқе§ӢеҢ–гҖҒеҲӨж–ӯж ҲжҳҜеҗҰдёәз©әгҖҒе…Ҙж ҲгҖҒеҮәж Ҳд»ҘеҸҠиҺ·еҸ–ж ҲйЎ¶е…ғзҙ зӯүгҖӮдёӢйқўд»ҘйЎәеәҸж ҲдёәдҫӢпјҢдҪҝз”Ё C++ з»ҷеҮәдёҖдёӘз®ҖеҚ•зҡ„е®һзҺ°гҖӮ
#include<stdio.h>
#include<malloc.h>
#define DataType int
#define MAXSIZE 1024
struct SeqStack {
DataType data[MAXSIZE];
int top;
};
//ж ҲеҲқе§ӢеҢ–,жҲҗеҠҹиҝ”еӣһж ҲеҜ№иұЎжҢҮй’ҲпјҢеӨұиҙҘиҝ”еӣһз©әжҢҮй’ҲNULL
SeqStack* initSeqStack() {
SeqStack* s=(SeqStack*)malloc(sizeof(SeqStack));
if(!s) {
printf("з©әй—ҙдёҚи¶і\n");
return NULL;
} else {
s->top = -1;
return s;
}
}
//еҲӨж–ӯж ҲжҳҜеҗҰдёәз©ә
bool isEmptySeqStack(SeqStack* s) {
if (s->top == -1)
return true;
else
return false;
}
//е…Ҙж ҲпјҢиҝ”еӣһ-1еӨұиҙҘпјҢ0жҲҗеҠҹ
int pushSeqStack(SeqStack* s, DataType x) {
if(s->top == MAXSIZE-1)
{
return -1;//ж Ҳж»ЎдёҚиғҪе…Ҙж Ҳ
} else {
s->top++;
s->data[s->top] = x;
return 0;
}
}
//еҮәж ҲпјҢиҝ”еӣһ-1еӨұиҙҘпјҢ0жҲҗеҠҹ
int popSeqStack(SeqStack* s, DataType* x) {
if(isEmptySeqStack(s)) {
return -1;//ж Ҳз©әдёҚиғҪеҮәж Ҳ
} else {
*x = s->data[s->top];
s->top--;
return 0;
}
}
//еҸ–ж ҲйЎ¶е…ғзҙ пјҢиҝ”еӣһ-1еӨұиҙҘпјҢ0жҲҗеҠҹ
int topSeqStack(SeqStack* s,DataType* x) {
if (isEmptySeqStack(s))
return -1; //ж Ҳз©ә
else {
*x=s->data[s->top];
return 0;
}
}
//жү“еҚ°ж Ҳдёӯе…ғзҙ
int printSeqStack(SeqStack* s) {
int i;
printf("еҪ“еүҚж Ҳдёӯзҡ„е…ғзҙ :\n");
for (i = s->top; i >= 0; i--)
printf("%4d",s->data[i]);
printf("\n");
return 0;
}
//test
int main() {
SeqStack* seqStack=initSeqStack();
if(seqStack) {
//е°Ҷ4гҖҒ5гҖҒ7еҲҶеҲ«е…Ҙж Ҳ
pushSeqStack(seqStack,4);
pushSeqStack(seqStack,5);
pushSeqStack(seqStack,7);
//жү“еҚ°ж ҲеҶ…жүҖжңүе…ғзҙ
printSeqStack(seqStack);
//иҺ·еҸ–ж ҲйЎ¶е…ғзҙ
DataType x=0;
int ret=topSeqStack(seqStack,&x);
if(0==ret) {
printf("top element is %d\n",x);
}
//е°Ҷж ҲйЎ¶е…ғзҙ еҮәж Ҳ
ret=popSeqStack(seqStack,&x);
if(0==ret) {
printf("pop top element is %d\n",x);
}
}
return 0;
}иҝҗиЎҢдёҠйқўзҡ„зЁӢеәҸпјҢиҫ“еҮәз»“жһңпјҡ
еҪ“еүҚж Ҳдёӯзҡ„е…ғзҙ : 7 5 4 top element is 7 pop top element is 7
2.2 е Ҷз®Җд»Ӣ
2.2.1 е Ҷзҡ„жҖ§иҙЁ
е ҶжҳҜдёҖз§Қеёёз”Ёзҡ„ж ‘еҪўз»“жһ„пјҢжҳҜдёҖз§Қзү№ж®Ҡзҡ„е®Ңе…ЁдәҢеҸүж ‘пјҢеҪ“дё”д»…еҪ“ж»Ўи¶іжүҖжңүиҠӮзӮ№зҡ„еҖјжҖ»жҳҜдёҚеӨ§дәҺжҲ–дёҚе°ҸдәҺе…¶зҲ¶иҠӮзӮ№зҡ„еҖјзҡ„е®Ңе…ЁдәҢеҸүж ‘иў«з§°д№Ӣдёәе ҶгҖӮе Ҷзҡ„иҝҷдёҖзү№жҖ§з§°д№Ӣдёәе ҶеәҸжҖ§гҖӮеӣ жӯӨпјҢеңЁдёҖдёӘе ҶдёӯпјҢж №иҠӮзӮ№жҳҜжңҖеӨ§пјҲжҲ–жңҖе°ҸпјүиҠӮзӮ№гҖӮеҰӮжһңж №иҠӮзӮ№жңҖе°ҸпјҢз§°д№Ӣдёәе°ҸйЎ¶е ҶпјҲжҲ–е°Ҹж №е ҶпјүпјҢеҰӮжһңж №иҠӮзӮ№жңҖеӨ§пјҢз§°д№ӢдёәеӨ§йЎ¶е ҶпјҲжҲ–еӨ§ж №е ҶпјүгҖӮе Ҷзҡ„е·ҰеҸіеӯ©еӯҗжІЎжңүеӨ§е°Ҹзҡ„йЎәеәҸгҖӮ
дёӢйқўжҳҜдёҖдёӘе°ҸйЎ¶е ҶзӨәдҫӢпјҡ

е Ҷзҡ„еӯҳеӮЁдёҖиҲ¬йғҪз”Ёж•°з»„жқҘеӯҳеӮЁе ҶпјҢiиҠӮзӮ№зҡ„зҲ¶иҠӮзӮ№дёӢж Үе°ұдёә ( i вҖ“ 1 ) / 2 (i вҖ“ 1) / 2 (iвҖ“1)/2гҖӮе®ғзҡ„е·ҰеҸіеӯҗиҠӮзӮ№дёӢж ҮеҲҶеҲ«дёә 2 вҲ— i + 1 2 * i + 1 2вҲ—i+1 е’Ң 2 вҲ— i + 2 2 * i + 2 2вҲ—i+2гҖӮеҰӮ第0дёӘиҠӮзӮ№е·ҰеҸіеӯҗиҠӮзӮ№дёӢж ҮеҲҶеҲ«дёә1е’Ң2гҖӮ

2.2.2 е Ҷзҡ„еҹәжң¬ж“ҚдҪң
пјҲ1пјүе»әз«Ӣ
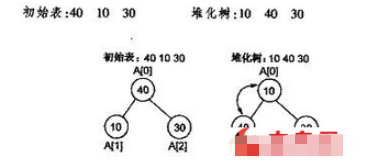
д»ҘжңҖе°Ҹе ҶдёәдҫӢпјҢеҰӮжһңд»Ҙж•°з»„еӯҳеӮЁе…ғзҙ ж—¶пјҢдёҖдёӘж•°з»„е…·жңүеҜ№еә”зҡ„ж ‘иЎЁзӨәеҪўејҸпјҢдҪҶж ‘е№¶дёҚж»Ўи¶іе Ҷзҡ„жқЎд»¶пјҢйңҖиҰҒйҮҚж–°жҺ’еҲ—е…ғзҙ пјҢеҸҜд»Ҙе»әз«ӢвҖңе ҶеҢ–вҖқзҡ„ж ‘гҖӮ
пјҲ2пјүжҸ’е…Ҙ
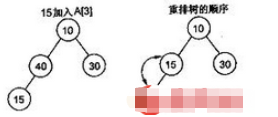
е°ҶдёҖдёӘж–°е…ғзҙ жҸ’е…ҘеҲ°иЎЁе°ҫпјҢеҚіж•°з»„жң«е°ҫж—¶пјҢеҰӮжһңж–°жһ„жҲҗзҡ„дәҢеҸүж ‘дёҚж»Ўи¶іе Ҷзҡ„жҖ§иҙЁпјҢйңҖиҰҒйҮҚж–°жҺ’еҲ—е…ғзҙ пјҢдёӢеӣҫжј”зӨәдәҶжҸ’е…Ҙ15ж—¶пјҢе Ҷзҡ„и°ғж•ҙгҖӮ
пјҲ3пјүеҲ йҷӨгҖӮ
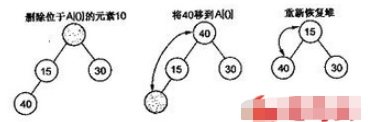
е ҶжҺ’еәҸдёӯпјҢеҲ йҷӨдёҖдёӘе…ғзҙ жҖ»жҳҜеҸ‘з”ҹеңЁе ҶйЎ¶пјҢеӣ дёәе ҶйЎ¶зҡ„е…ғзҙ жҳҜжңҖе°Ҹзҡ„пјҲе°ҸйЎ¶е ҶдёӯпјүгҖӮиЎЁдёӯжңҖеҗҺдёҖдёӘе…ғзҙ з”ЁжқҘеЎ«иЎҘз©әзјәдҪҚзҪ®пјҢз»“жһңж ‘иў«жӣҙж–°д»Ҙж»Ўи¶іе ҶжқЎд»¶гҖӮ
2.2.3 е Ҷж“ҚдҪңе®һзҺ°
пјҲ1пјүжҸ’е…Ҙд»Јз Ғе®һзҺ°
жҜҸж¬ЎжҸ’е…ҘйғҪжҳҜе°Ҷж–°ж•°жҚ®ж”ҫеңЁж•°з»„жңҖеҗҺгҖӮеҸҜд»ҘеҸ‘зҺ°д»ҺиҝҷдёӘж–°ж•°жҚ®зҡ„зҲ¶иҠӮзӮ№еҲ°ж №иҠӮзӮ№еҝ…然дёәдёҖдёӘжңүеәҸзҡ„ж•°еҲ—пјҢзҺ°еңЁзҡ„д»»еҠЎжҳҜе°ҶиҝҷдёӘж–°ж•°жҚ®жҸ’е…ҘеҲ°иҝҷдёӘжңүеәҸж•°жҚ®дёӯпјҢиҝҷе°ұзұ»дјјдәҺзӣҙжҺҘжҸ’е…ҘжҺ’еәҸдёӯе°ҶдёҖдёӘж•°жҚ®е№¶е…ҘеҲ°жңүеәҸеҢәй—ҙдёӯпјҢиҝҷжҳҜиҠӮзӮ№вҖңдёҠжө®вҖқи°ғж•ҙгҖӮдёҚйҡҫеҶҷеҮәжҸ’е…ҘдёҖдёӘж–°ж•°жҚ®ж—¶е Ҷзҡ„и°ғж•ҙд»Јз Ғпјҡ
// ж–°еҠ е…ҘiиҠӮзӮ№,е…¶зҲ¶иҠӮзӮ№дёә(i-1)/2
// еҸӮж•°пјҡaпјҡж•°з»„пјҢiпјҡж–°жҸ’е…Ҙе…ғзҙ еңЁж•°з»„дёӯзҡ„дёӢж Ү
void minHeapFixUp(int a[], int i) {
int j, temp;
temp = a[i];
j = (i-1)/2; //зҲ¶иҠӮзӮ№
while (j >= 0 && i != 0) {
if (a[j] <= temp)//еҰӮжһңзҲ¶иҠӮзӮ№дёҚеӨ§дәҺж–°жҸ’е…Ҙзҡ„е…ғзҙ пјҢеҒңжӯўеҜ»жүҫ
break;
a[i]=a[j]; //жҠҠиҫғеӨ§зҡ„еӯҗиҠӮзӮ№еҫҖдёӢ移еҠЁ,жӣҝжҚўе®ғзҡ„еӯҗиҠӮзӮ№
i = j;
j = (i-1)/2;
}
a[i] = temp;
}еӣ жӯӨпјҢжҸ’е…Ҙж•°жҚ®еҲ°жңҖе°Ҹе Ҷж—¶пјҡ
// еңЁжңҖе°Ҹе ҶдёӯеҠ е…Ҙж–°зҡ„ж•°жҚ®data
// aпјҡж•°з»„пјҢindexпјҡжҸ’е…Ҙзҡ„дёӢж ҮпјҢ
void minHeapAddNumber(int a[], int index, int data) {
a[index] = data;
minHeapFixUp(a, index);
}пјҲ2пјүеҲ йҷӨд»Јз Ғе®һзҺ°
жҢүз…§е ҶеҲ йҷӨзҡ„иҜҙжҳҺпјҢе ҶдёӯжҜҸж¬ЎйғҪеҸӘиғҪеҲ йҷӨ第0дёӘж•°жҚ®гҖӮдёәдәҶдҫҝдәҺйҮҚе»әе ҶпјҢе®һйҷ…зҡ„ж“ҚдҪңжҳҜе°Ҷж•°з»„жңҖеҗҺдёҖдёӘж•°жҚ®дёҺж №иҠӮзӮ№дәӨжҚўпјҢ然еҗҺеҶҚд»Һж №иҠӮзӮ№ејҖе§ӢиҝӣиЎҢдёҖж¬Ўд»ҺдёҠеҗ‘дёӢзҡ„и°ғж•ҙгҖӮ
и°ғж•ҙж—¶е…ҲеңЁе·ҰеҸіе„ҝеӯҗиҠӮзӮ№дёӯжүҫжңҖе°Ҹзҡ„пјҢеҰӮжһңзҲ¶иҠӮзӮ№дёҚеӨ§дәҺиҝҷдёӘжңҖе°Ҹзҡ„еӯҗиҠӮзӮ№иҜҙжҳҺдёҚйңҖиҰҒи°ғж•ҙдәҶпјҢеҸҚд№Ӣе°ҶжңҖе°Ҹзҡ„еӯҗиҠӮзӮ№жҚўеҲ°зҲ¶иҠӮзӮ№зҡ„дҪҚзҪ®гҖӮжӯӨж—¶зҲ¶иҠӮзӮ№е®һйҷ…дёҠ并дёҚйңҖиҰҒжҚўеҲ°жңҖе°ҸеӯҗиҠӮзӮ№зҡ„дҪҚзҪ®пјҢеӣ дёәиҝҷдёҚжҳҜзҲ¶иҠӮзӮ№зҡ„жңҖз»ҲдҪҚзҪ®гҖӮдҪҶйҖ»иҫ‘дёҠзҲ¶иҠӮзӮ№жӣҝжҚўдәҶжңҖе°Ҹзҡ„еӯҗиҠӮзӮ№пјҢ然еҗҺеҶҚиҖғиҷ‘зҲ¶иҠӮзӮ№еҜ№еҗҺйқўзҡ„иҠӮзӮ№зҡ„еҪұе“ҚгҖӮе Ҷе…ғзҙ зҡ„еҲ йҷӨеҜјиҮҙзҡ„е Ҷи°ғж•ҙпјҢе…¶ж•ҙдёӘиҝҮзЁӢе°ұжҳҜе°Ҷж №иҠӮзӮ№иҝӣиЎҢвҖңдёӢжІүвҖқеӨ„зҗҶгҖӮдёӢйқўз»ҷеҮәд»Јз Ғпјҡ
// aдёәж•°з»„пјҢlenдёәиҠӮзӮ№жҖ»ж•°пјӣд»ҺindexиҠӮзӮ№ејҖе§Ӣи°ғж•ҙпјҢindexд»Һ0ејҖе§Ӣи®Ўз®—indexе…¶еӯҗиҠӮзӮ№дёә 2*index+1, 2*index+2пјӣlen/2-1дёәжңҖеҗҺдёҖдёӘйқһеҸ¶еӯҗиҠӮзӮ№
void minHeapFixDown(int a[],int len,int index) {
if(index>(len/2-1))//indexдёәеҸ¶еӯҗиҠӮзӮ№дёҚз”Ёи°ғж•ҙ
return;
int tmp=a[index];
lastIndex=index;
while(index<=len/2-1) //еҪ“дёӢжІүеҲ°еҸ¶еӯҗиҠӮзӮ№ж—¶пјҢе°ұдёҚз”Ёи°ғж•ҙдәҶ
{
// еҰӮжһңе·ҰеӯҗиҠӮзӮ№е°ҸдәҺеҫ…и°ғж•ҙиҠӮзӮ№
if(a[2*index+1]<tmp) {
lastIndex = 2*index+1;
}
//еҰӮжһңеӯҳеңЁеҸіеӯҗиҠӮзӮ№дё”е°ҸдәҺе·ҰеӯҗиҠӮзӮ№е’Ңеҫ…и°ғж•ҙиҠӮзӮ№
if(2*index+2<len && a[2*index+2]<a[2*index+1]&& a[2*index+2]<tmp) {
lastIndex=2*index+2;
}
//еҰӮжһңе·ҰеҸіеӯҗиҠӮзӮ№жңүдёҖдёӘе°ҸдәҺеҫ…и°ғж•ҙиҠӮзӮ№пјҢйҖүжӢ©жңҖе°ҸеӯҗиҠӮзӮ№иҝӣиЎҢдёҠжө®
if(lastIndex!=index) {
a[index]=a[lastIndex];
index=lastIndex;
} else break; //еҗҰеҲҷеҫ…и°ғж•ҙиҠӮзӮ№дёҚз”ЁдёӢжІүи°ғж•ҙ
}
a[lastIndex]=tmp; //е°Ҷеҫ…и°ғж•ҙиҠӮзӮ№ж”ҫеҲ°жңҖеҗҺзҡ„дҪҚзҪ®
}ж №жҚ®е ҶеҲ йҷӨзҡ„дёӢжІүжҖқжғіпјҢеҸҜд»ҘжңүдёҚеҗҢзүҲжң¬зҡ„д»Јз Ғе®һзҺ°пјҢд»ҘдёҠжҳҜе’ҢеӯҷеҮӣеҗҢеӯҰдёҖиө·и®Ёи®әеҮәзҡ„дёҖдёӘзүҲжң¬пјҢеңЁиҝҷйҮҢж„ҹи°ўд»–зҡ„еҸӮдёҺпјҢиҜ»иҖ…еҸҜеҸҰиЎҢз»ҷеҮәгҖӮдёӘдәәдҪ“дјҡпјҢиҝҷйҮҢе»әи®®еӨ§е®¶ж №жҚ®еҜ№е Ҷи°ғж•ҙиҝҮзЁӢзҡ„зҗҶи§ЈпјҢеҶҷеҮәиҮӘе·ұзҡ„д»Јз ҒпјҢеҲҮеӢҝзңӢзӨәдҫӢд»Јз ҒеҺ»зҗҶи§Јз®—жі•пјҢиҖҢжҳҜзҗҶи§Јз®—жі•жҖқжғіеҶҷеҮәд»Јз ҒпјҢеҗҰеҲҷеҫҲеҝ«е°ұдјҡеҝҳи®°гҖӮ
пјҲ3пјүе»әе Ҷ
жңүдәҶе Ҷзҡ„жҸ’е…Ҙе’ҢеҲ йҷӨеҗҺпјҢеҶҚиҖғиҷ‘дёӢеҰӮдҪ•еҜ№дёҖдёӘж•°жҚ®иҝӣиЎҢе ҶеҢ–ж“ҚдҪңгҖӮиҰҒдёҖдёӘдёҖдёӘзҡ„д»Һж•°з»„дёӯеҸ–еҮәж•°жҚ®жқҘе»әз«Ӣе Ҷеҗ§пјҢдёҚз”ЁпјҒе…ҲзңӢдёҖдёӘж•°з»„пјҢеҰӮдёӢеӣҫпјҡ

еҫҲжҳҺжҳҫпјҢеҜ№еҸ¶еӯҗиҠӮзӮ№жқҘиҜҙпјҢеҸҜд»Ҙи®Өдёәе®ғе·Із»ҸжҳҜдёҖдёӘеҗҲжі•зҡ„е ҶдәҶеҚі20пјҢ60пјҢ 65пјҢ 4пјҢ 49йғҪеҲҶеҲ«жҳҜдёҖдёӘеҗҲжі•зҡ„е ҶгҖӮеҸӘиҰҒд»ҺA[4]=50ејҖе§Ӣеҗ‘дёӢи°ғж•ҙе°ұеҸҜд»ҘдәҶгҖӮ然еҗҺеҶҚеҸ–A[3]=30пјҢA[2] = 17пјҢA[1] = 12пјҢA[0] = 9еҲҶеҲ«дҪңдёҖж¬Ўеҗ‘дёӢи°ғж•ҙж“ҚдҪңе°ұеҸҜд»ҘдәҶгҖӮдёӢеӣҫеұ•зӨәдәҶиҝҷдәӣжӯҘйӘӨпјҡ

еҶҷеҮәе ҶеҢ–ж•°з»„зҡ„д»Јз Ғпјҡ
// е»әз«ӢжңҖе°Ҹе Ҷ
// a:ж•°з»„пјҢnпјҡж•°з»„й•ҝеәҰ
void makeMinHeap(int a[], int n) {
for (int i = n/2-1; i >= 0; i--)
minHeapFixDown(a, i, n);
}2.2.4 е Ҷзҡ„е…·дҪ“еә”з”ЁвҖ”вҖ”е ҶжҺ’еәҸ
е ҶжҺ’еәҸпјҲHeapsortпјүжҳҜе Ҷзҡ„дёҖдёӘз»Ҹе…ёеә”з”ЁпјҢжңүдәҶдёҠйқўеҜ№е Ҷзҡ„дәҶи§ЈпјҢдёҚйҡҫе®һзҺ°е ҶжҺ’еәҸгҖӮз”ұдәҺе Ҷд№ҹжҳҜз”Ёж•°з»„жқҘеӯҳеӮЁзҡ„пјҢж•…еҜ№ж•°з»„иҝӣиЎҢе ҶеҢ–еҗҺпјҢ第дёҖж¬Ўе°ҶA[0]дёҺA[n - 1]дәӨжҚўпјҢеҶҚеҜ№A[0вҖҰn-2]йҮҚж–°жҒўеӨҚе ҶгҖӮ第дәҢж¬Ўе°ҶA[0]дёҺA[n вҖ“ 2]дәӨжҚўпјҢеҶҚеҜ№A[0вҖҰn - 3]йҮҚж–°жҒўеӨҚе ҶпјҢйҮҚеӨҚиҝҷж ·зҡ„ж“ҚдҪңзӣҙеҲ°A[0]дёҺA[1]дәӨжҚўгҖӮз”ұдәҺжҜҸж¬ЎйғҪжҳҜе°ҶжңҖе°Ҹзҡ„ж•°жҚ®е№¶е…ҘеҲ°еҗҺйқўзҡ„жңүеәҸеҢәй—ҙпјҢж•…ж“ҚдҪңе®ҢжҲҗеҗҺж•ҙдёӘж•°з»„е°ұжңүеәҸдәҶгҖӮжңүзӮ№зұ»дјјдәҺзӣҙжҺҘйҖүжӢ©жҺ’еәҸгҖӮ
еӣ жӯӨпјҢе®ҢжҲҗе ҶжҺ’еәҸ并没жңүз”ЁеҲ°еүҚйқўиҜҙжҳҺзҡ„жҸ’е…Ҙж“ҚдҪңпјҢеҸӘз”ЁеҲ°дәҶе»әе Ҷе’ҢиҠӮзӮ№еҗ‘дёӢи°ғж•ҙзҡ„ж“ҚдҪңпјҢе ҶжҺ’еәҸзҡ„ж“ҚдҪңеҰӮдёӢпјҡ
// array:еҫ…жҺ’еәҸж•°з»„пјҢlenпјҡж•°з»„й•ҝеәҰ
void heapSort(int array[],int len) {
// е»әе Ҷ
makeMinHeap(array,len);
// жңҖеҗҺдёҖдёӘеҸ¶еӯҗиҠӮзӮ№е’Ңж №иҠӮзӮ№дәӨжҚўпјҢ并иҝӣиЎҢе Ҷи°ғж•ҙпјҢдәӨжҚўж¬Ўж•°дёәlen-1ж¬Ў
for(int i=len-1;i>0;--i) {
//жңҖеҗҺдёҖдёӘеҸ¶еӯҗиҠӮзӮ№дәӨжҚў
array[i]=array[i]+array[0];
array[0]=array[i]-array[0];
array[i]=array[i]-array[0];
// е Ҷи°ғж•ҙ
minHeapFixDown(array, 0, len-i-1);
}
}пјҲ1пјүзЁіе®ҡжҖ§гҖӮе ҶжҺ’еәҸжҳҜдёҚзЁіе®ҡжҺ’еәҸгҖӮ
пјҲ2пјүе ҶжҺ’еәҸжҖ§иғҪеҲҶжһҗгҖӮз”ұдәҺжҜҸж¬ЎйҮҚж–°жҒўеӨҚе Ҷзҡ„ж—¶й—ҙеӨҚжқӮеәҰдёәO(logN)пјҢе…ұN-1ж¬Ўе Ҷи°ғж•ҙж“ҚдҪңпјҢеҶҚеҠ дёҠеүҚйқўе»әз«Ӣе Ҷж—¶N/2ж¬Ўеҗ‘дёӢи°ғж•ҙпјҢжҜҸж¬Ўи°ғж•ҙж—¶й—ҙеӨҚжқӮеәҰд№ҹдёәO(logN)гҖӮдёӨж¬Ўж“ҚдҪңж—¶й—ҙеӨҚжқӮеәҰзӣёеҠ иҝҳжҳҜO(NlogN)пјҢж•…е ҶжҺ’еәҸзҡ„ж—¶й—ҙеӨҚжқӮеәҰдёәO(NlogN)гҖӮ
жңҖеқҸжғ…еҶөпјҡеҰӮжһңеҫ…жҺ’еәҸж•°з»„жҳҜжңүеәҸзҡ„пјҢд»Қ然йңҖиҰҒO(NlogN)еӨҚжқӮеәҰзҡ„жҜ”иҫғж“ҚдҪңпјҢеҸӘжҳҜе°‘дәҶ移еҠЁзҡ„ж“ҚдҪңпјӣ
жңҖеҘҪжғ…еҶөпјҡеҰӮжһңеҫ…жҺ’еәҸж•°з»„жҳҜйҖҶеәҸзҡ„пјҢдёҚд»…йңҖиҰҒO(NlogN)еӨҚжқӮеәҰзҡ„жҜ”иҫғж“ҚдҪңпјҢиҖҢдё”йңҖиҰҒO(NlogN)еӨҚжқӮеәҰзҡ„дәӨжҚўж“ҚдҪңпјҢжҖ»зҡ„ж—¶й—ҙеӨҚжқӮеәҰиҝҳжҳҜO(NlogN)гҖӮ
еӣ жӯӨпјҢе ҶжҺ’еәҸе’Ңеҝ«йҖҹжҺ’еәҸеңЁж•ҲзҺҮдёҠжҳҜе·®дёҚеӨҡзҡ„пјҢдҪҶжҳҜе ҶжҺ’еәҸдёҖиҲ¬дјҳдәҺеҝ«йҖҹжҺ’еәҸзҡ„йҮҚиҰҒдёҖзӮ№жҳҜж•°жҚ®зҡ„еҲқе§ӢеҲҶеёғжғ…еҶөеҜ№е ҶжҺ’еәҸзҡ„ж•ҲзҺҮжІЎжңүеӨ§зҡ„еҪұе“ҚгҖӮ
еҲ°жӯӨпјҢе…ідәҺвҖңC++дёӯе ҶдёҺж Ҳзҡ„еҢәеҲ«жңүе“ӘдәӣвҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ





