在日常开发或维护中经常会遇到大表的情况,所谓的大表是指存储了百万级乃至千万级条记录的表。这样的表过于庞大,导致数据库在查询和插入的时候耗时太长,性能低下,如果涉及联合查询的情况,性能会更加糟糕。分表和表分区的目的就是减少数据库的负担,提高数据库的效率,通常点来讲就是提高表的增删改查效率。
一、什么是分表:
分表是将一个大表按照一定的规则分解成多张具有独立存储空间的实体表,我们可以称为子表,每个表都对应三个文件,MYD数据文件,.MYI索引文件,.frm表结构文件。这些子表可以分布在同一块磁盘上,也可以在不同的机器上。
1、根据分表技术对海量数据的优化方式目前有2种方法:
1、垂直分割:把一个数据量很大的表,根据某个字段的属性或使用频繁程度分类拆分为多个表,或者把一个业务系统的库分到不同的实例上。
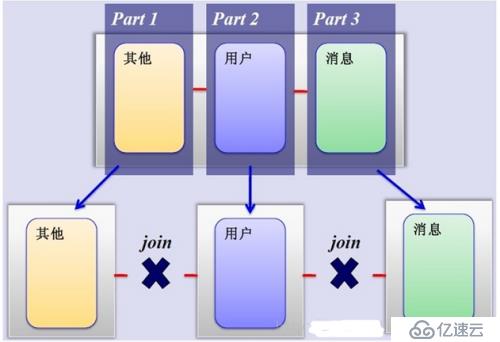
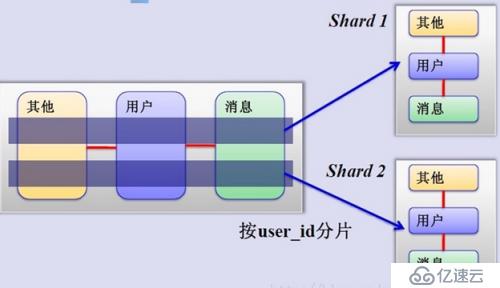
2、水平分割:根据一列或者多列的值把数据行放到多个独立的表里,水平分表方式可以通过多个低配置主机整合起来,实现高性能。
3、两者的优缺点:
水平优点:拆分规则抽象好,JION操作基本可以数据库做,不存在单表大数据、高并发的性能瓶颈,应用端改造较少,提高系统的稳定性和负载能力
缺点:分片事务一致性难以解决,在MyCAT2.0之前MySQL5.7之前,还是数据弱XA。数据多次扩展难度维护量大,夸库JOIN性能差
垂直优点:拆分后业务清晰,拆分规则明确,系统之间整合或者拓展容易,数据库维护简单
缺点:部分业务无法使用JOIN,只能通过接口方式解决,提供系统能够复杂度,受每种业务不同的限制存在性能瓶颈,不容易数据扩展跟性能提高。
事务处理复杂,垂直切分后按照业务的分类将表分散到不同的库,会导致有些业务表过于庞大,存在单库读写与存储瓶颈。
二、什么是分区
分区就是把一张表的数据分成N多个区域,分区后,表面上还是一张表,但数据散列到多个位置根据数据量的大小,结合实际业务
1、分区方式有:
a、range分区:主要用于时间列分区、值范围,行数据基于一个给定连续分区的列值放入分区。如销售类的表,可以根据年来分区存放销售记录
b、list分区:面向离散的值,分区要指定的值,当插入指定的数据到指定分区表去,如指定某些值在特定分区里。
c、key分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
d、hash分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL 中有效的、产生非负整数值的任何表达式。
三、分区实例:
创建redundant格式
如果表中存在主键或是唯一索引时,分区列必须是唯一索引的一个组成部分
唯一索引
create table t11(
col1 int not null,
col2 date not null,
col3 int not null,
col4 int not null,
unique key (col1,col2))
partition by hash(col1)
partitions 4;
哈希
create table t121(
col1 int not null,
col2 date not null,
col3 int not null,
col4 int not null,
unique key (col1,col2))
partition by hash(year(col2))
partitions 4;
主键
create table t31(
col1 int not null,
col2 date not null,
col3 int not null,
col4 int not null,
primary key (col1,col2))
partition by hash(col1)
partitions 8;
主键和索引同时存在:
create table t41(
col1 int not null,
col2 date not null,
col3 int not null,
col4 int not null,
unique key(col4),
primary key (col1))
partition by hash(col1)
partitions 5;
唯一索引可以允许是null值,分区列只要是唯一索引的一个组成部分,不需要整个唯一索引列都是分区列
create table t223332(
col1 int null,
col2 date null,
col3 int null,
col4 int null)
partition by hash(col3)
partitions 4;
没有主键或唯一索引,可以指定任何一个列为分区列
create table t223332(
col1 int null,
col2 date null,
col3 int null,
col4 int null,
key(col4))
partition by hash(col3)
partitions 4;
rang 分区:主要用于时间列分区,如销售类的表,可以根据年来分区存放销售记录
定义:行数据基于一个给定连续分区的列值放入分区,
id 是主键
create table t3(
id int)engine=innodb
partition by range(id)(
partition p0 values less than (10),
partition p1 values less than (20)
);
查看数据文件
t3.frm t.par
insert into t select 9;
insert into t select 10;
insert into t select 15;
查看分区状态
use information_schema
select * from PARITIONS where table_schema=''test and table_name='t3'\G;
partition_method代表分区类型
当不满足分区条件的时候报错
table has no partition for value 40
alter table t add partition(partition p2 values less than maxalue);
主要用于时间列分区,如销售类的表,可以根据年来分区存放销售记录(year(date))取年的时间
create table sales(
money int not null,date datetime)engine=innodb
partition by range (year(date))(
partition p2008 values less than (2009),
partition p2009 values less than (2010),
partition p2010 values less than (2011)
);
insert into sales select 100,'2008-01-01';
insert into sales select 100.'2008-02-01';
insert into sales select 100.'2008-01-02';
insert into sales select 100,'2009-03-01';
insert into sales select 100,'2010-01-01';
list 分区:面向离散的值,分区要指定的值,当插入指定的数据到指定分区表去,
create table t_list (a int,b int)engine=innodb
partition by list(b)(partition p0 values in(1,3,5,7,9),
partition p1 values in (0,2,4,6,8));
insert into t4 select 1, 3;
insert into t4 select 1, 5;
insert into t4 select 1, 8;
insert into t4 select 1, 6;
table has no partition for values10
值得注意的是,LIST分区没有类似如“VALUES LESS THAN MAXVALUE”这样的包含其他值在内的定义。将要匹配的任何值都必须在值列表中找到。
LIST分区除了能和RANGE分区结合起来生成一个复合的子分区,与HASH和KEY分区结合起来生成复合的子分区也是可能的。
注意:innodb myisam区别
在用insert插入多行数据的过程中遇到分区为定义的值,myisam、innodb存储引擎的处理完全不同,
myisam 一条不成功,之前的成功值,会进入表中
innodb只要一条不成功,所有都不成功
create table t(a int,b int)engine=myisam partition by list(b)(partition p0 values in (1,3,5,7,9),partition p1 values in (0,2,4,6,8));
insert into t values (1,2),(2,4),(6,19),(5,3);
insert into t values (1,2),(2,4),(6,19),(5,3);
ERROR 1526 (HY000): Table has no partition for value 19
select * from t;
+------+------+
| a | b |
+------+------+
| 1 | 2 |
| 2 | 4 |
+------+------+
2 rows in set (0.00 sec)
create table tt(a int,b int)engine=innodb partition by list(b)(partition p0 values in (1,3,5,7,9),partition p1 values in (0,2,4,6,8));
insert into tt values (1,2),(2,4),(6,19),(5,3);
insert into tt values (1,2),(2,4),(6,19),(5,3);
ERROR 1526 (HY000): Table has no partition for value 19
select * from tt;
Empty set (0.00 sec)
hash 分区:根据用户的表达式的返回值来进行分区,返回值不能是负数
要在create table 语句上添加一个partition by hash(expr)句子,其中expr是一个返回一个整数的表达式,它可以仅仅是数字段类型为mysql整型的列名字
后面在添加一个partitions num子句,num是一个非负数
create table t_hash(a int,b date)engine=innodb
partition by hash(YEAR(b))
partitions 4;
insert into t_hash select 1,'2010-04-01';
create table tt_hash(a int,b date)engine=innodb
partition by hash (a)
partitions 4;
#######################################
columns分区
区别于其他分区,分区条件必须是整型,如果不是整型也应该需要通过函数将其转化为整型 columns分时是rang list分区的进化
支持整型类型
日期类型date datetime其余的日期类型不予支持
字符串类型 char varcha binary varbinary ,blok和text类型的不予支持
create table tt_column_range(a int,b int)engine=innodb partition by range columns(a,b)(
partition p0 values less than (0,10),
partition p1 values less than (10,20),
partition p2 values less than (20,30),
partition p3 values less than (30,40),
partition p4 values less than (40,50)
);
子分区:MYSQL数据库允许在rang和list的分区上再进行hask或者key子分区,
create table ts(a int,b date)engine=innodb
partition by range(year(b))
subpartition by hash(to_days(b))
subpartitions 3(
partition p0 values less than (2013),
partition p0 values less than (2014),
partition p1 values less than (2015)
partition p2 values less than maxvalue);
create table ts(a int,b date
partition by range(year(b))
subpartition by hash(to_days(b))(
partition p0 values less than(2014)(
subpartition s0,
subpartition s1)
partition p1 values less than (2015)(
subpartition s2,
subpartition s3
)
partition p2 values less than maxvalue(
subpartition s4
subpartition s5
)
)
每个子分区必须包含分区的名字。
子分区的名字唯一的。
分区中null值
create table t3(
id int)engine=innodb
partition by range(id)(
partition p0 values less than (10),
partition p1 values less than (20);
);
null值 放最左边的。总结:了解基础的分表的原则、方法,实际还需要根据业务结合,达到业务架构最优。
如有不妥,欢迎指正!
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



