今天就跟大家聊聊有关MySql数据库中无法使用索引进行范围查找如何解决,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
对建立好的复合索引进行排序,并取记录中非索引字段,发现索引不生效,例如,有如下表,DDL语句为:
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` enum('M','F') NOT NULL,
`hire_date` date NOT NULL,
`age` int(11) NOT NULL,
PRIMARY KEY (`emp_no`),
KEY `unique_birth_name` (`first_name`,`last_name`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;复合索引为unique_birth_name (first_name,last_name) 。使用以下语句:
EXPLAIN SELECT gender FROM employees ORDER BY first_name, last_name

根据上图:type:all 及 Extra:Using filesort 可得,索引没有生效。
继续进行试验,对查询语句进一步改写,加上一个范围查找:
EXPLAIN SELECT gender FROM employees WHERE first_name > 'Leah' ORDER BY first_name, last_name
执行计划显示如下图:

这里发现结果和第一次sql分析无异。继续试验。
改写sql语句:
EXPLAIN SELECT gender FROM employees WHERE first_name > 'Tzvetan' ORDER BY first_name, last_name

此时,令人惊讶的是,索引生效了。
此时,我们做一个大胆的猜测:
第一次进行sql分析时,因为第一次order by 后,得到的还是全表数据,如果根据复合索引中携带的主键查找每一个gender进行拼接,自然很费资源和时间,mysql不会做如此蠢的事。不如直接进行全表扫描,把扫描到的每条数据和order by得到的临时数据进行拼接,从而得到需要的数据。
为了验证上述想法的正确性,我们对三次sql进行分析。
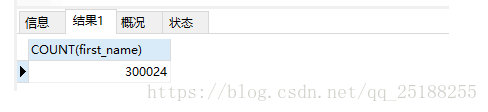
第一次sql根据复合索引得到的数据量为:300024,为全表数据
SELECT COUNT(first_name) FROM employees ORDER BY first_name, last_name
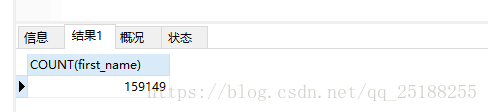
第二次改写的sql根据复合索引得到的数据量为:159149 , 为全表数据量的1/2。
SELECT COUNT(first_name) FROM employees WHERE first_name > 'Leah' ORDER BY first_name, last_name
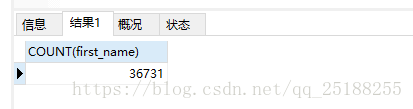
第三次改写的sql根据复合索引得到的数据量为:36731, 为全表数据量的1/10。
SELECT COUNT(first_name) FROM employees WHERE first_name > 'Tzvetan' ORDER BY first_name, last_name
通过对比发现,第二次改写的sql根据复合索引得到的数据量是全表数据量的1/2。此时还没有达到mysql使用索引进行二次查找的量级。第三次改写的sql根据复合索引得到的数据量是全表数据量的1/10,达到了mysql使用索引进行二次查找的量级,于是从执行计划上可以看到,第三次改写sql是走了索引的。
mysql 是否根据首次索引条件查询出的主键进行二次查找,也是要看查询出来的数据量级,如果数据量接近全表数据量的话,就会进行全表扫描,否则根据第一次查询出来的主键进行二次查询。
看完上述内容,你们对MySql数据库中无法使用索引进行范围查找如何解决有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





