怎么在SpringBoot中使用Tess4j实现一个OCR识别工具?很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
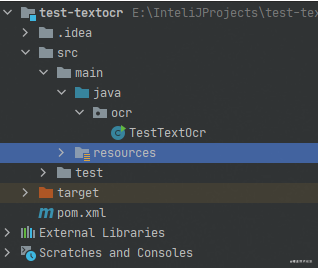
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>test-textocr</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<!-- https://mvnrepository.com/artifact/net.sourceforge.tess4j/tess4j -->
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>4.5.3</version>
</dependency>
</dependencies>
</project>package ocr;
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
/**
* ocr测试.
*
* @author huc_逆天
* @since 2021/1/12 17:42
*/
public class TestTextOcr {
public static void main(String[] args) throws IOException {
// 创建实例
ITesseract instance = new Tesseract();
// 设置识别语言
instance.setLanguage("chi_sim");
// 设置识别引擎
instance.setOcrEngineMode(1);
// 读取文件
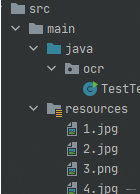
BufferedImage image = ImageIO.read(TestTextOcr.class.getResourceAsStream("/2.jpg"));
try {
// 识别
String result = instance.doOCR(image);
System.out.println(result);
} catch (TesseractException e) {
System.err.println(e.getMessage());
}
}
}
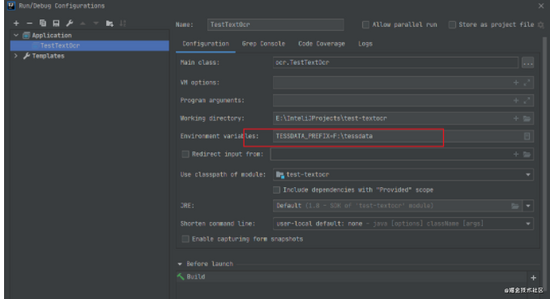
TESSDATA_PREFIX=F:\tessdata ,变量名,固定,值为官网下载文件 https://github.com/tesseract-ocr/tessdata
结果如下:
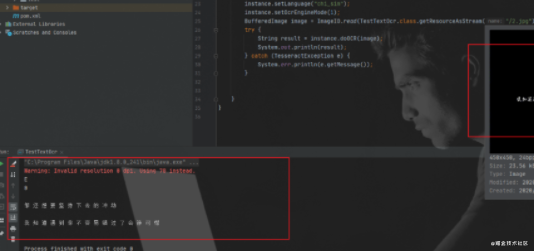
可能识别模式,不是很合适,切换下
instance.setOcrEngineMode(0);
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



