这篇文章给大家介绍Pyspider爬虫框架怎么在Python中使用,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
一个国人编写的强大的网络爬虫系统并带有强大的WebUI。采用Python语言编写,分布式架构,支持多种数据库后端,强大的WebUI支持脚本编辑器,任务监视器,项目管理器以及结果查看器。
用Python编写脚本
功能强大的WebUI,包含脚本编辑器,任务监视器,项目管理器和结果查看器
MySQL,MongoDB,Redis,SQLite,Elasticsearch ; PostgreSQL与SQLAlchemy作为数据库后端
RabbitMQ,Beanstalk,Redis和Kombu作为消息队列
任务优先级,重试,定期,按年龄重新抓取等...
分布式架构,抓取JavaScript页面,Python 2和3等...
1>中文文档:http://www.pyspider.cn/
2>英文文档:http://docs.pyspider.org/
打开cmd命令行工具,执行命令
pip install pyspider

出现下图则安装成功

安装pyspider后,打开cmd命令工具,执行命令来启动服务器
pyspider
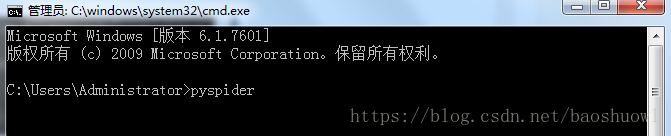
出现下图则启动服务成功,默认地址端口为127.0.0.1:5000
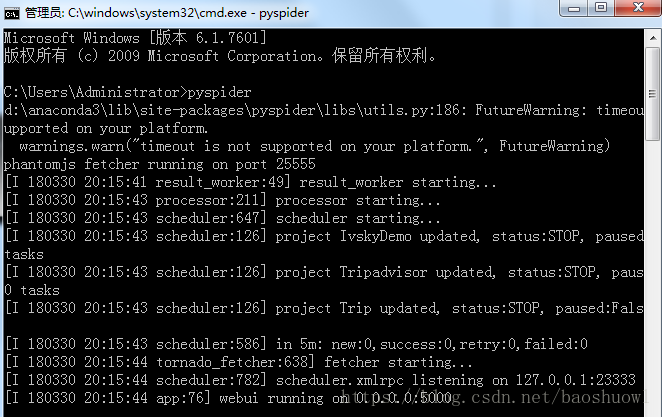
输入地址127.0.0.1:5000,打开WebUI界面
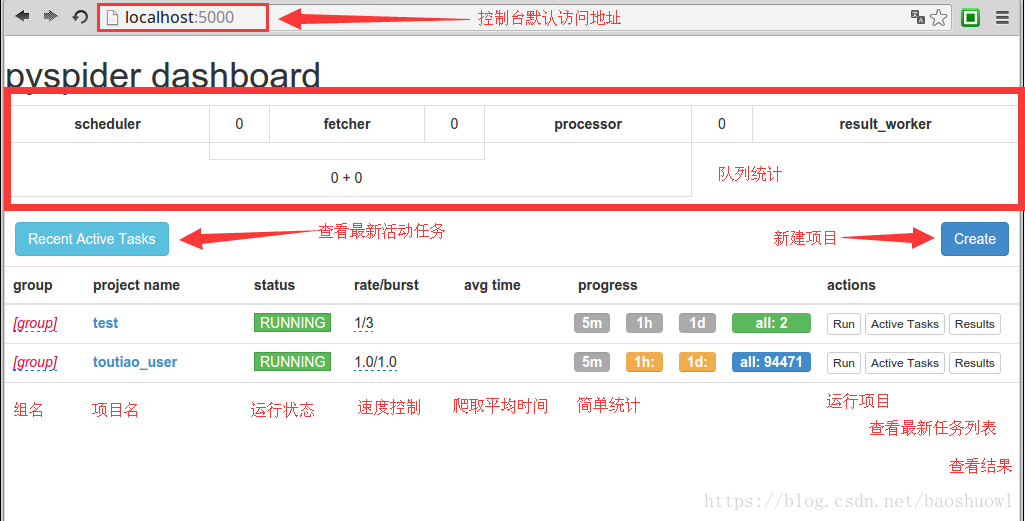
队列统计是为了方便查看爬虫状态,优化爬虫爬取速度新增的状态统计.每个组件之间的数字就是对应不同队列的排队数量.通常来是0或是个位数.如果达到了几十甚至一百说明下游组件出现了瓶颈或错误,需要分析处理.
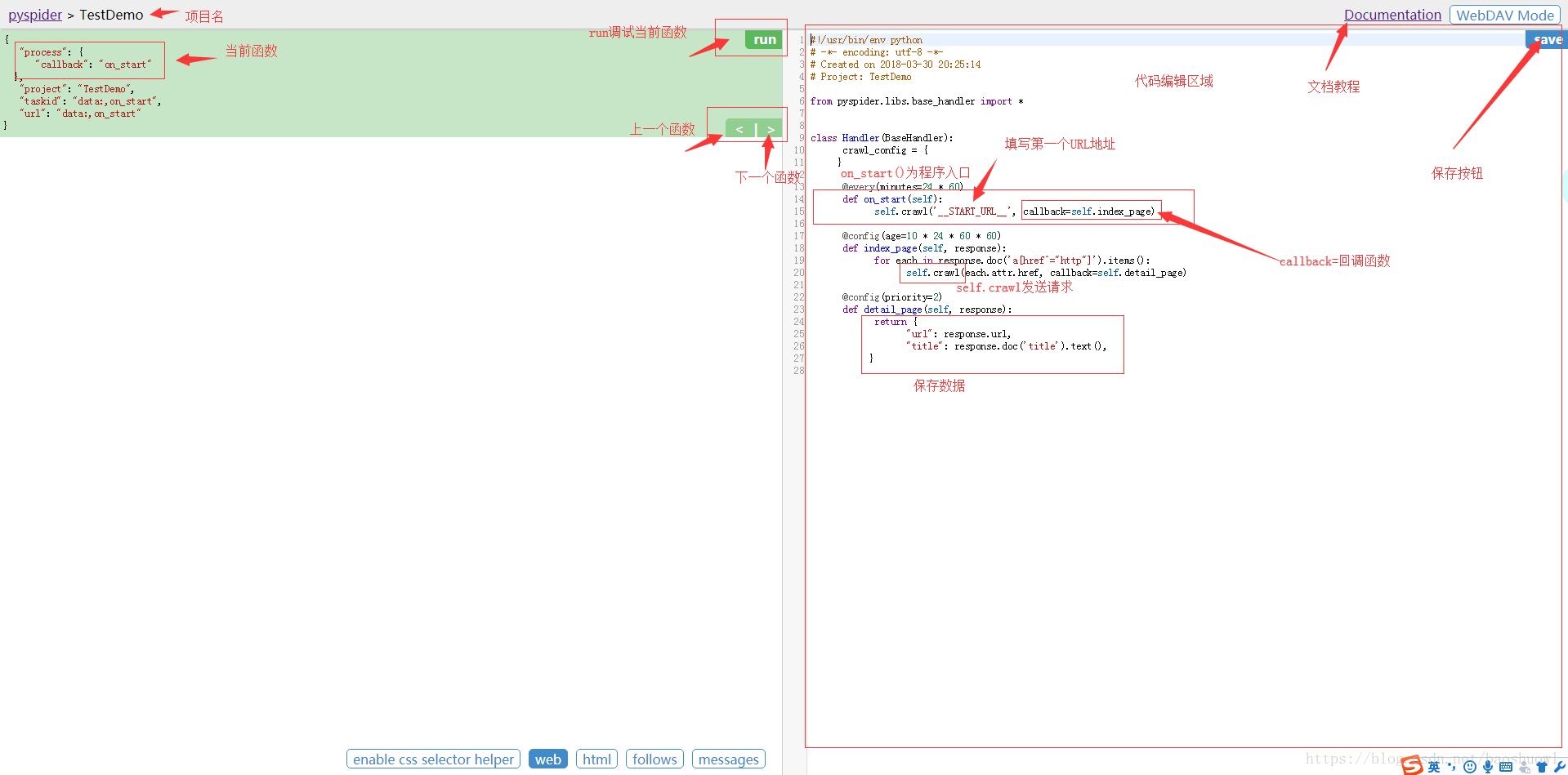
新建项目:pyspider与scrapy最大的区别就在这,pyspider新建项目调试项目完全在web下进行,而scrapy是在命令行下开发并运行测试.
组名:项目新建后一般来说是不能修改项目名的,如果需要特殊标记可修改组名.直接在组名上点鼠标左键进行修改.注意:组名改为delete后如果状态为stop状态,24小时后项目会被系统删除.
运行状态:这一栏显示的是当前项目的运行状态.每个项目的运行状态都是单独设置的.直接在每个项目的运行状态上点鼠标左键进行修改.运行分为五个状态:TODO,STOP,CHECKING,DEBUG,RUNNING.各状态说明:TODO是新建项目后的默认状态,不会运行项目.STOP状态是停止状态,也不会运行.CHECHING是修改项目代码后自动变的状态.DEBUG是调试模式,遇到错误信息会停止继续运行,RUNNING是运行状态,遇到错误会自动尝试,如果还是错误会跳过错误的任务继续运行.
速度控制:很多朋友安装好用说爬的慢,多数情况是速度被限制了.这个功能就是速度设置项.rate是每秒爬取页面数,burst是并发数.如1/3是三个并发,每秒爬取一个页面.
简单统计:这个功能只是简单的做的运行状态统计,5m是五分钟内任务执行情况,1h是一小时内运行任务统计,1d是一天内运行统计,all是所有的任务统计.
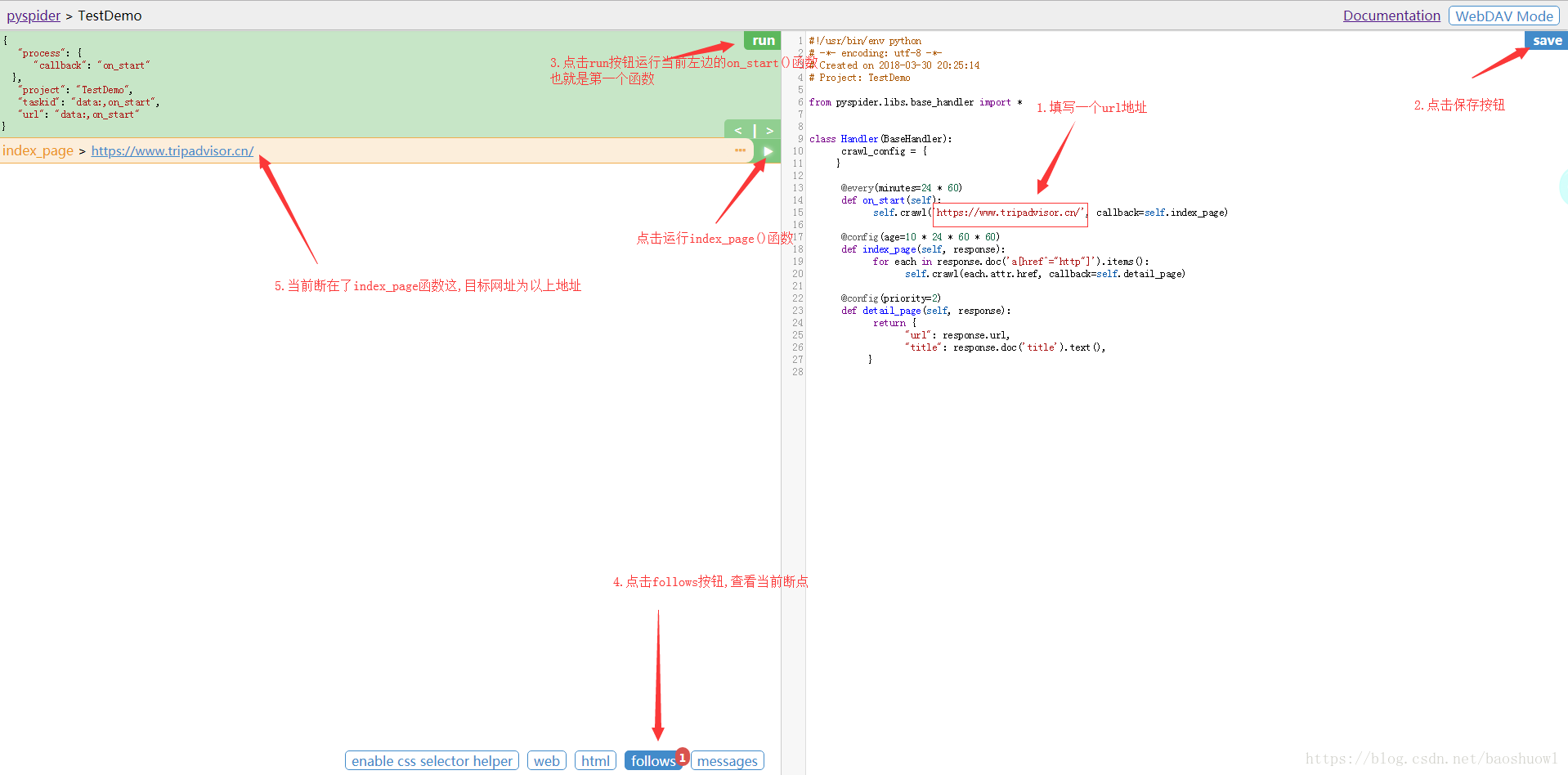
运行:run按钮是项目初次运行需要点的按钮,这个功能会运行项目的on_start方法来生成入口任务.
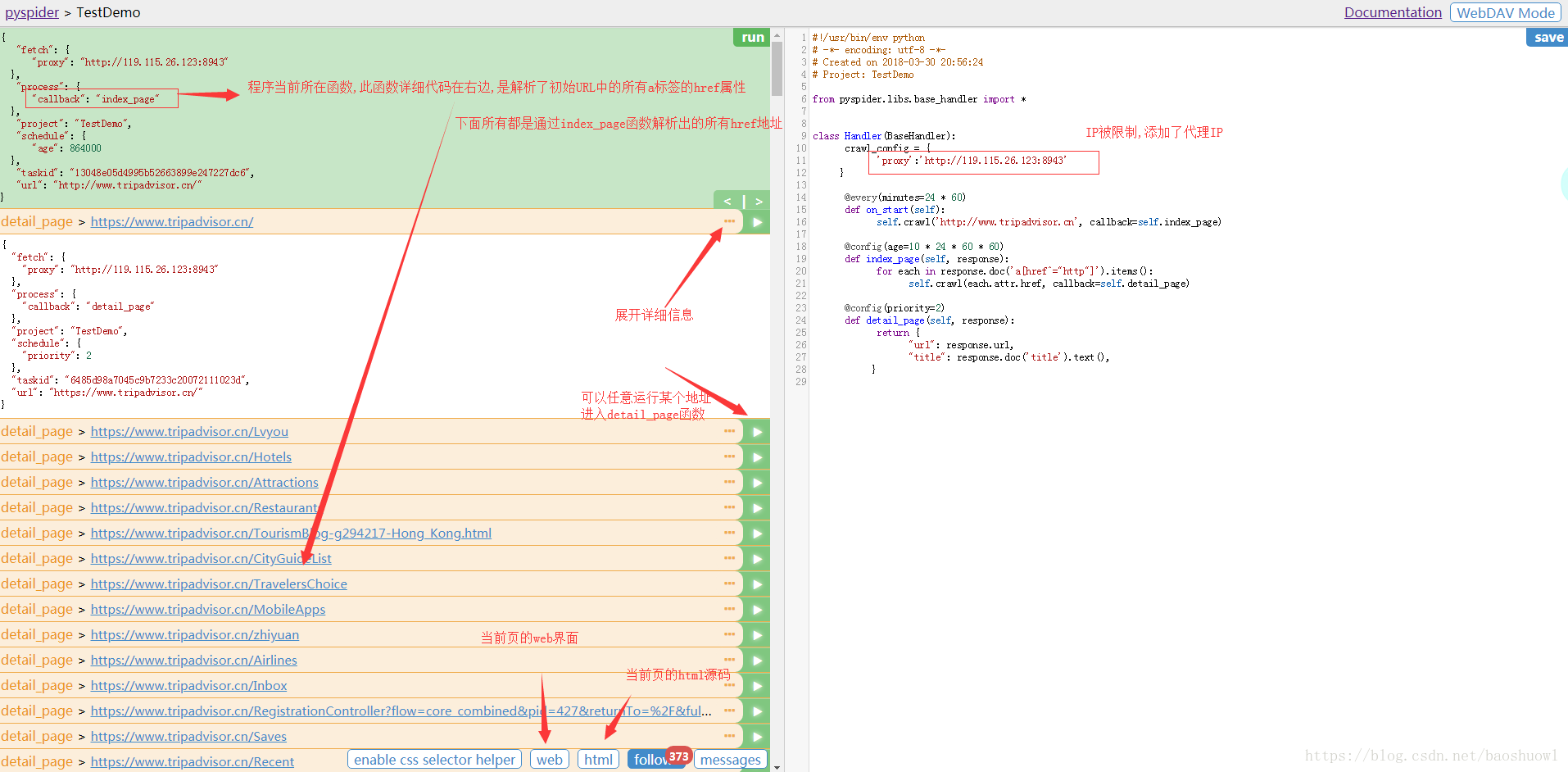
任务列表:显示最新任务列表,方便查看状态,查看错误等
结果查看:查看项目爬取的结果.
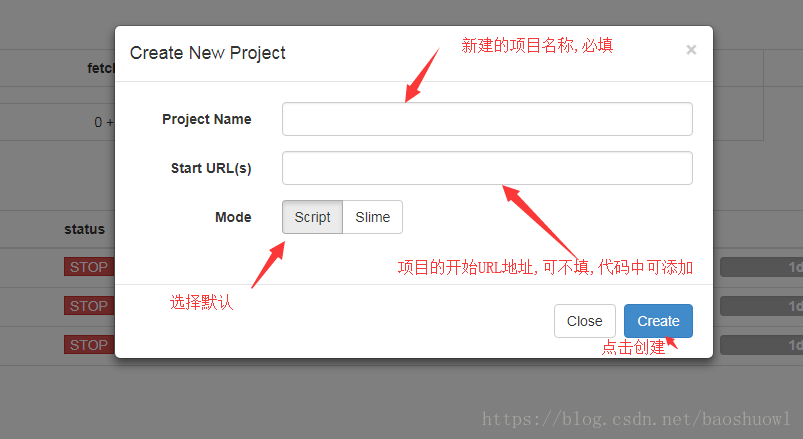
点击上图中的新建项目按钮
关于Pyspider爬虫框架怎么在Python中使用就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





