10 Hive体系架构
10.1 概念
用户接口:用户访问Hive的入口
元数据:Hive的用户信息与表的MetaData
解释器:分析翻译HQL的组件
编译器:编译HQL的组件
优化器:优化HQL的组件
10.2 Hive架构与基本组成
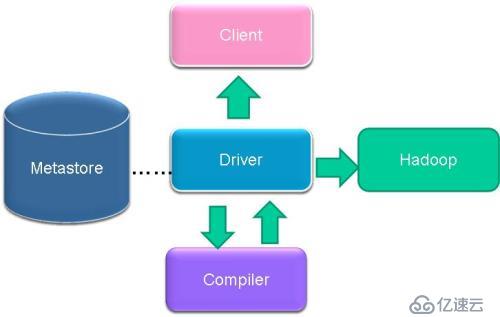
1、架构图
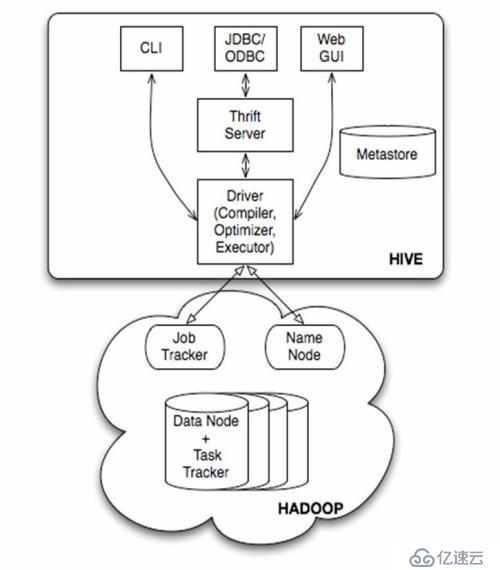
2、基本组成
用户接口,包括 CLI,JDBC/ODBC,WebUI
元数据存储,通常是存储在关系数据库如 mysql, derby 中
解释器、编译器、优化器、执行器
Hadoop:用HDFS 进行存储,利用 MapReduce 进行计算
3、各组件的基本功能
用户接口主要有三个:CLI,JDBC/ODBC和 WebUI
CLI,即Shell命令行
JDBC/ODBC 是Hive 的JAVA,与使用传统数据库JDBC的方式类似
WebGUI是通过浏览器访问 Hive
Hive 将元数据存储在数据库中,目前只支持 mysql、derby,下一版本会支持更多的数据库。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等
解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行
Hive 的数据存储在HDFS 中,大部分的查询由 MapReduce 完成(包含* 的查询,比如 select * from table 不会生成 MapRedcue 任务)
4、Metastore
Metastore是系统目录(catalog)用于保存Hive中所存储的表的元数据(metadata)信息
Metastore是Hive被用作传统数据库解决方案(如oracle和db2)时区别其它类似系统的一个特征
Metastore包含如下的部分:
Database 是表(table)的名字空间。默认的数据库(database)名为‘default’
Table 表(table)的原数据包含信息有:列(list of columns)和它们的类型(types),拥有者(owner),存储空间(storage)和SerDei信息
Partition 每个分区(partition)都有自己的列(columns),SerDe和存储空间(storage)。这一特征将被用来支持Hive中的模式演变(schema evolution)
5、Compiler
Driver调用编译器(compiler)处理HiveQL字串,这些字串可能是一条DDL、DML或查询语句
编译器将字符串转化为策略(plan)
策略仅由元数据操作和HDFS操作组成,元数据操作只包含DDL语句,HDFS操作只包含LOAD语句
对插入和查询而言,策略由map-reduce任务中的具有方向的非循环图(directedacyclic graph,DAG)组成
10.3 Hive运行模式
Hive的运行模式即任务的执行环境
分为本地与集群两种
我们可以通过mapred.job.tracker 来指明
设置方式:hive > SET mapred.job.tracker=local
10.4 数据类型
1、原始数据类型
Integers:TINYINT - 1 byte、SMALLINT - 2 byte、INT - 4 byte、BIGINT - 8 byte
Boolean type:BOOLEAN - TRUE/FALSE
Floating point numbers:FLOAT –单精度、DOUBLE – 双精度
String type:STRING - sequence of charactersin a specified character set
2、复杂数据类型
Structs: 例子 {c INT; d INT}
Maps (key-value tuples):. 例子'group' ->gid M['group']
Arrays (indexable lists): 例子[‘1', ‘2', ‘3']
TIMESTAMP 0.8版本新加属性
10.5 Hive的元数据存储
1、存储方式与模式
Hive将元数据存储在数据库中
连接到数据库模式有三种
单用户模式
多用户模式
远程服务器模式
2、单用户模式
此模式连接到一个 In-memory 的数据库 Derby ,一般用于 Unit Test
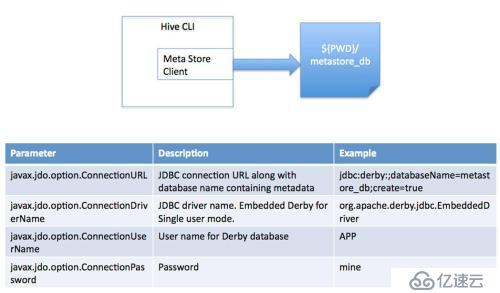
3、多用户模式
通过网络连接到一个数据库中,是最经常使用到的模式
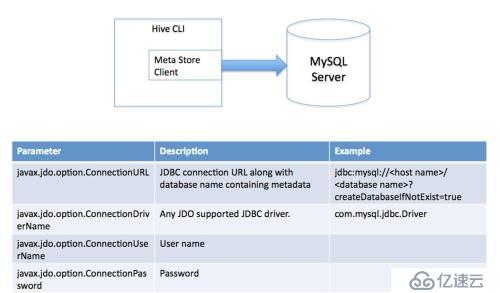
4、远程服务器模式
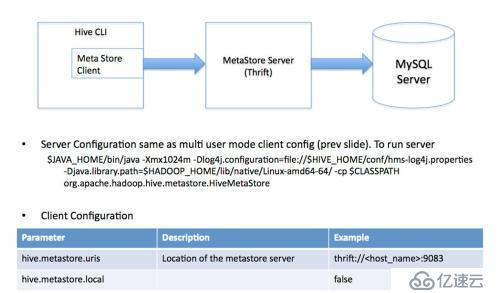 用于非 Java 客户端访问元数据库,在服务器端启动MetaStoreServer,客户端利用 Thrift 协议通过MetaStoreServer 访问元数据库。
用于非 Java 客户端访问元数据库,在服务器端启动MetaStoreServer,客户端利用 Thrift 协议通过MetaStoreServer 访问元数据库。
10.6 Hive的数据存储
1、Hive数据存储的基本概念
Hive的数据存储是建立在Hadoop HDFS之上的
Hive没有专门的数据存储格式
存储结构主要包括:数据库、文件、表、视图
Hive默认可以直接加载文本文件,还支持sequence file 、RCFile
创建表时,我们直接告诉Hive数据的列分隔符与行分隔符,Hive即可解析数据
2、Hive的数据模型-数据库
类似传统数据库的DataBase
在第三方数据库里实际是一张表
简单示例:命令行hive > create database test_database;
3、内部表
与数据库中的 Table 在概念上是类似
每一个 Table 在 Hive 中都有一个相应的目录存储数据
例如,一个表 test,它在 HDFS 中的路径为:/warehouse /test
warehouse是在 hive-site.xml 中由
${hive.metastore.warehouse.dir}指定的数据仓库的目录
所有的 Table 数据(不包括 External Table)都保存在这个目录中。
删除表时,元数据与数据都会被删除
4、内部表简单示例
创建数据文件test_inner_table.txt
创建表
create table test_inner_table (key string)加载数据
LOAD DATA LOCAL INPATH ‘filepath’ INTO TABLE test_inner_table查看数据
select * from test_inner_table
select count(*) from test_inner_table删除表
drop table test_inner_table5、分区表
Partition 对应于数据库中的 Partition 列的密集索引
在 Hive 中,表中的一个 Partition 对应于表下的一个目录,所有的 Partition 的数据都存储在对应的目录中
例如:test表中包含 date 和position 两个 Partition,则对应于 date= 20120801, position = zh 的 HDFS 子目录为:/ warehouse /test/date=20120801/ position =zh
对应于 = 20100801, position = US 的HDFS 子目录为;/ warehouse/xiaojun/date=20120801/ position =US
6、分区表简单示例
创建数据文件test_partition_table.txt
创建表
create table test_partition_table (key string) partitioned by (dtstring)加载数据
LOAD DATA INPATH ‘filepath’ INTO TABLE test_partition_tablepartition (dt=‘2006’)查看数据
select * from test_partition_table
select count(*) from test_partition_table删除表
drop table test_partition_table7、外部表
指向已经在 HDFS 中存在的数据,可以创建 Partition
它和 内部表 在元数据的组织上是相同的,而实际数据的存储则有较大的差异
内部表 的创建过程和数据加载过程(这两个过程可以在同一个语句中完成),在加载数据的过程中,实际数据会被移动到数据仓库目录中;之后对数据对访问将会直接在数据仓库目录中完成。删除表时,表中的数据和元数据将会被同时删除
外部表 只有一个过程,加载数据和创建表同时完成,并不会移动到数据仓库目录中,只是与外部数据建立一个链接。当删除一个外部表 时,仅删除该链接
8、外部表简单示例
创建数据文件test_external_table.txt
创建表
create external table test_external_table (key string)加载数据
LOAD DATA INPATH ‘filepath’ INTO TABLE test_inner_table查看数据
select * from test_external_table
select count(*) from test_external_table删除表
drop table test_external_table9、Bucket Table(桶表)
可以将表的列通过Hash算法进一步分解成不同的文件存储
例如:将age列分散成20个文件,首先要对AGE进行Hash计算,对应为0的写入/warehouse/test/date=20120801/postion=zh/part-00000,对应为1的写入/warehouse/test/date=20120801/postion=zh/part-00001
如果想应用很多的Map任务这样是不错的选择
10、Bucket Table简单示例
创建数据文件test_bucket_table.txt
创建表
create table test_bucket_table (key string)
clustered by (key)into 20 buckets加载数据
LOAD DATA INPATH ‘filepath’ INTO TABLE test_bucket_table查看数据
select * from test_bucket_table
set hive.enforce.bucketing = true;11、Hive的数据模型-视图
视图与传统数据库的视图类似
视图是只读的
视图基于的基本表,如果改变,指增加不会影响视图的呈现;如果删除,会出现问题
如果不指定视图的列,会根据select语句后的生成
示例
create view test_view as select * from test10.7 Hive的数据存储
配置步骤:
hive-site.xml 添加
<property>
<name>hive.hwi.war.file</name>
<value>lib/hive-hwi-0.8.1.war</value>
</property>启动Hive的UI sh $HIVE_HOME/bin/hive --service hwi
11 Hive原理
11.1 Hive原理
1、什么要学习Hive的原理
一条Hive HQL将转换为多少道MR作业
怎么样加快Hive的执行速度
编写Hive HQL的时候我们可以做什么
Hive 怎么将HQL转换为MR作业
Hive会采用什么样的优化方式
3、Hive执行流程
编译器将一个Hive QL转换操作符
操作符是Hive的最小的处理单元
每个操作符代表HDFS的一个操作或者一道MapReduce作业
4、Operator
Operator都是hive定义的一个处理过程
Operator都定义有:
protected List <Operator<? extends Serializable >> childOperators;
protected List <Operator<? extends Serializable >> parentOperators;
protected boolean done; // 初始化值为false
所有的操作构成了 Operator图,hive正是基于这些图关系来处理诸如limit, group by, join等操作。

5、Hive执行流程
操作符 | 描述 |
TableScanOperator | 扫描hive表数据 |
ReduceSinkOperator | 创建将发送到Reducer端的<Key,Value>对 |
JoinOperator | Join两份数据 |
SelectOperator | 选择输出列 |
FileSinkOperator | 建立结果数据,输出至文件 |
FilterOperator | 过滤输入数据 |
GroupByOperator | GroupBy语句 |
MapJoinOperator | /*+mapjoin(t) */ |
LimitOperator | Limit语句 |
UnionOperator | Union语句 |
Hive通过ExecMapper和ExecReducer执行MapReduce任务
在执行MapReduce时有两种模式
本地模式
分布式模式
6、ANTLR词法语法分析工具
ANTLR—Another Tool for Language Recognition
ANTLR 是开源的
为包括Java,C++,C#在内的语言提供了一个通过语法描述来自动构造自定义语言的识别器(recognizer),编译器(parser)和解释器(translator)的框架
Hibernate就是使用了该分析工具
11.2 一条HQL引发的思考
1、案例HQL
select key from test_limit limit 1
Stage-1
TableScan Operator>Select Operator-> Limit->File OutputOperator
Stage-0
Fetch Operator
读取文件
2、Mapper与InputFormat
该hive MR作业中指定的mapper是:
mapred.mapper.class = org.apache.hadoop.hive.ql.exec.ExecMapper
input format是:
hive.input.format =
org.apache.hadoop.hive.ql.io.CombineHiveInputFormat
该hive MR作业中指定的mapper是:
mapred.mapper.class = org.apache.hadoop.hive.ql.exec.ExecMapper
input format是:
hive.input.format =
org.apache.hadoop.hive.ql.io.CombineHiveInputFormat
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



