环境:VSPHERE5.5+独立oracle 11G数据库
现象:打开vcenter服务器控制台,输入密码后卡在欢迎界面无响应,客户端也无法正常登陆。
正常重启也不行。由于VC所在虚机为独立磁盘无法做快照,不能备当时状态。
查看所在WINDOWS系统日志发现硬件可能有问题。
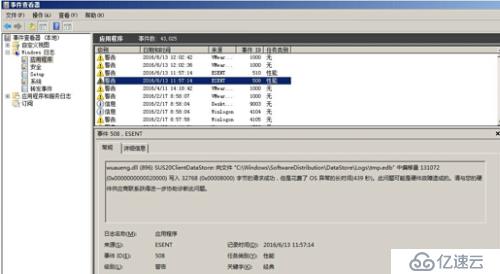
这是偏移量,并不能代表硬件有问题,怀疑VC连接的数据库有问题,逐登陆排查。
1、登陆11.15.146.2
首先查看数据库进程,正常。
2、查看数据库的告警日志,发现一个问题。

这个实际上是个比较常见的错误。通常来说是因为在日志被写满时会切换日志组,这个时候会触发一次checkpoint,DBWR会把内存中的脏块往数据文件中写,只要没写结束就不会释放这个日志组。如果归档模式被开启的话,还会伴随着ARCH写归档的过程。如果redo log产生的过快,当CPK或归档还没完成,LGWR已经把其余的日志组写满,又要往当前的日志组里面写redolog的时候,这个时候就会发生冲突,数据库就会被挂起。并且一直会往alert.log中写类似上面的错误信息。
分析原因:
服务器有三个日志组g1、g2、g3.当g1写完时,要往g2上写,这时候g1要进行归档,还要进行checkpoint。然后另外两个日志组继续写。当g2和g3都写完之后,又要往g1上写,但是问题来了,g1还没有完成归档和checkpoint操作。所以这时就会报警。
解决方法:
多加几个日志组,并且每个日志组空间大一点,这样就可以延缓时间,会留给g1充分的时间来完成归档和checkpoint任务。就不会有报错。
操作步骤:
首先查看下数据库的日志组状态
查看在线日志组:SQL> select * from v$log;
查看日志组中的成员:SQL> select * from v$logfile;
查看日志组的具体状态:SQL> select group#,sequence#,bytes,members,status from v$log;
GROUP# SEQUENCE# BYTES MEMBERS STATUS
------------------------------------------------
1 28825 52428800 1 INACTIVE
2 28826 52428800 1 ACTIVE
3 28827 52428800 1 CURRENT
CURRENT: 表示是当前的日志。
INACTIVE:脏数据已经写入数据块。该状态可以drop。
ACTIVE: 脏数据还没有写入数据块。
日志只有50M太小
扩充下日志组大小
SQL> alter database add logfile group 4 ('/u01/app/oracle/oradata/pvdb/redo04.log')size 500M;
Database altered.
SQL> alter database add logfile group 5('/u01/app/oracle/oradata/pvdb/redo05.log') size 500M;
Database altered.
SQL> alter database add logfile group 6 ('/u01/app/oracle/oradata/pvdb/redo06.log')size 500M;
Database altered.
切换日志组
SQL> alter system switch logfile;
System altered.
SQL> alter system switch logfile;
System altered.
注意:alter system switch logfile 和alter system archive log current这两个切换的区别。
alter system switch logfile 是不等待归档完成就switch logfile。如果database尚未开启archive log mode。那用这个切换是毋庸置疑了。另外,也是对单实例database和RAC模式下当前实例执行日志切换。
而alter system archive log current则需要等待归档完成才switch logfile。会对其中所有实例执行日志切换。
整体上说来,在自动归档的库里,两个命令的所产生的结果几乎一样。有区别的是alter system archive log current所用的时间会比alter system switch logfile 的长。
删除日志组
SQL> alter database drop logfile group 1;
Database altered.
SQL> alter database drop logfile group 2;
Database altered.
SQL> alter database drop logfile group 3;
Database altered.
注意删除日志组及日志组成员:
原则:删除前必须遵守如下原则,每个实例必须至少有两个日志组;当一个组处于ACTIVE或者CURRENT的状态时不可删除;删除日志组的操作只对数据库进行更改,操作系统的文件尚未删除;当删除时适用DROP LOGFILE GROUP N语句时,此时GROUP N内的所有成员都将被删除。
ALTER DATABASE DROP LOGFILE GROUP N;
日志组状态的改变:
SQL> select group#,sequence#,bytes,members,status from v$log;
GROUP# SEQUENCE# BYTES MEMBERS STATUS
---------- ---------- ---------- ---------- ----------------
1 201268 2147483648 1 CURRENT
2 201263 2147483648 1 ACTIVE
3 201264 2147483648 1 ACTIVE
4 201267 524288000 1 ACTIVE
5 201265 524288000 1 ACTIVE
6 201266 524288000 1 ACTIVE
SQL> ALTER SYSTEM CHECKPOINT;
SQL> select group#,sequence#,bytes,members,status from v$log;
GROUP# SEQUENCE# BYTES MEMBERS STATUS
---------- ---------- ---------- ---------- ----------------
1 201268 2147483648 1 CURRENT
2 201263 2147483648 1 INACTIVE
3 201264 2147483648 1 INACTIVE
4 201267 524288000 1 INACTIVE
5 201265 524288000 1 INACTIVE
6 201266 524288000 1 INACTIVE
删除日志成员的原则:当你删除一个是该组中最后一个成员的时候,你不能删除此成员;当组的转台处于current的状态时,不能删除组成员;在归档模式下,必须得归档之后才能删除;删除日志组成员的操作只对数据库进行更改,操作系统的文件尚未删除。
删除日志组后再删除相应日志文件,例如redo01.log
SQL> !rm /u01/app/oracle/oradata/pvdb/redo01.log
SQL> alter system switch logfile;
System altered.
SQL> select group#,sequence#,bytes,members,status from v$log;
GROUP# SEQUENCE# BYTES MEMBERS STATUS
------------------------------------------------
4 28828 524288000 1 INACTIVE
5 28829 524288000 1 ACTIVE
6 28830 524288000 1 CURRENT
最后切完日志组后,观察新建的REDO日志组已被应用,数据库正常,数据库日志再无报警,问题解决。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



