一、Sqoop介绍
Sqoop是一个用来将Hadoop(Hive、HBase)和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如:MySQL ,Oracle ,Postgres等)中的数据导入到Hadoop的HDFS中,也可以将HDFS的数据导入到关系型数据库中。
Sqoop目前已经是Apache的顶级项目了,目前版本是1.4.4 和 Sqoop2 1.99.3,本文以1.4.4的版本为例讲解基本的安装配置和简单应用的演示。
版本为:
sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
环境变量配置
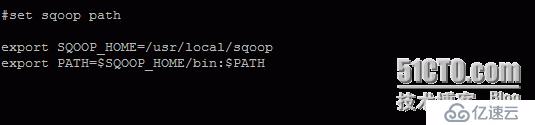
2.Sqoop参数配置
# Set Hadoop-specific environment variables here.
#Set path to where bin/hadoop is available
#export HADOOP_COMMON_HOME=
#Set path to where hadoop-*-core.jar is available
#export HADOOP_MAPRED_HOME=
#set the path to where bin/hbase is available
#export HBASE_HOME=
#Set the path to where bin/hive is available
#export HIVE_HOME=3.驱动jar包
下面测试演示以MySQL为例,则需要把mysql对应的驱动lib文件copy到<SQOOP_HOME>/lib 目录下。
4.Mysql中测试数据
CREATE TABLE `demo_blog` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`blog` varchar(100) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
CREATE TABLE `demo_log` (
`operator` varchar(16) NOT NULL,
`log` varchar(100) NOT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
插入测试数据:
insert into demo_blog (id, blog) values (1, "micmiu.com");
insert into demo_blog (id, blog) values (2, "ctosun.com");
insert into demo_blog (id, blog) values (3, "baby.micmiu.com");
insert into demo_log (operator, log) values ("micmiu", "create");
insert into demo_log (operator, log) values ("micmiu", "update");
insert into demo_log (operator, log) values ("michael", "edit");
insert into demo_log (operator, log) values ("michael", "delete");1.Sqoop基本命令
(1)列出Mysql中的数据库
sqoop list-databases --connect jdbc:mysql://Master-Hadoop:3306 --username root --password rootroot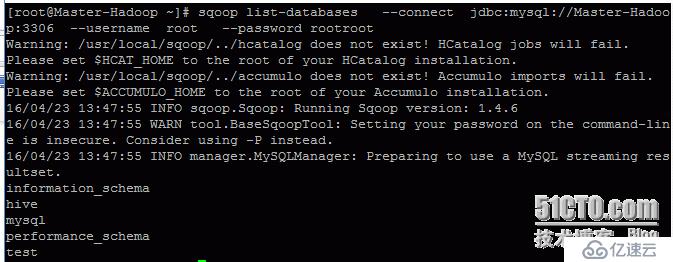
(2)列出test数据库中所有的表
sqoop list-databases --connect jdbc:mysql://Master-Hadoop:3306 --username root --password rootroot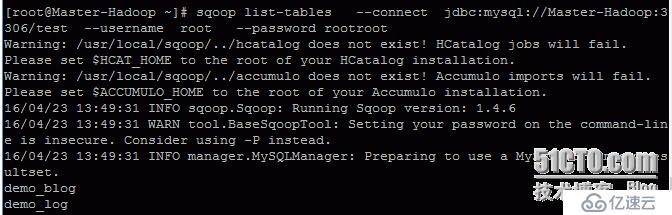
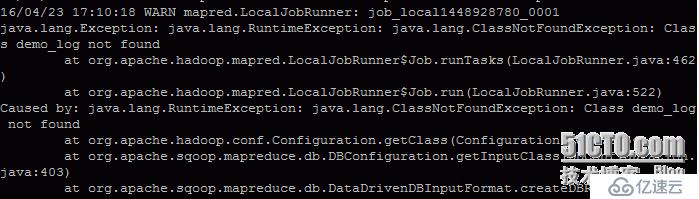
(3)从Mysql导入HDFS文件中
sqoop import --connect jdbc:mysql://Master-Hadoop:3306/test --username root --password rootroot --table demo_log --split-by operator --target-dir /usr/sqoop/other显示错误:找不到表中的类 Class demo_log not found
1.将/tmp/sqoop-root/compile/………下的编译文件复制到 /usr/local/sqoop/lib/下
2.需要以下注释配置
bin/configure-sqoop文件中把以下内容注释掉就可以了
## Moved to be a runtime check in sqoop.
#if [ ! -d "${HBASE_HOME}" ]; then
# echo "Warning: $HBASE_HOME does not exist! HBase imports will fail."
# echo 'Please set $HBASE_HOME to the root of your HBase installation.'
#fi
## Moved to be a runtime check in sqoop.
#if [ ! -d "${HCAT_HOME}" ]; then
# echo "Warning: $HCAT_HOME does not exist! HCatalog jobs will fail."
# echo 'Please set $HCAT_HOME to the root of your HCatalog installation.'
#fi(4)从HDFS中导入到Mysql中
sqoop export --connect jdbc:mysql://Master-Hadoop:3306/test --username root --password rootroot --table dutao --export-dir /usr/other/part-2 --input-fields-terminated-by '\t' -m 1(5)从mysql中导入到Hive中
sqoop import --connect jdbc:mysql://Master-Hadoop:3306/test --username root --password rootroot --table demo_log --warehouse-dir /user/sqoop/demo_log --hive-import --create-hive-table -m 1直接导入hive表
sqoop import --connect jdbc:postgresql://ip/db_name--username user_name --table table_name --hive-import -m 5
内部执行实际分三部,1.将数据导入hdfs(可在hdfs上找到相应目录),2.创建hive表名相同的表,3,将hdfs上数据传入hive表中
sqoop根据postgresql表创建hive表
sqoop create-hive-table --connect jdbc:postgresql://ip/db_name --username user_name --table table_name --hive-table hive_table_name( --hive-partition-key partition_name若需要分区则加入分区名称)
导入hive已经创建好的表中
sqoop import --connect jdbc:postgresql://ip/db_name --username user_name --table table_name --hive-import -m 5 --hive-table hive_table_name (--hive-partition-key partition_name --hive-partition-value partititon_value);
使用query导入hive表
sqoop import --connect jdbc:postgresql://ip/db_name --username user_name --query "select ,* from retail_tb_order where \$CONDITIONS" --hive-import -m 5 --hive-table hive_table_name (--hive-partition-key partition_name --hive-partition-value partititon_value);
注意:$CONDITIONS条件必须有,query子句若用双引号,则$CONDITIONS需要使用\转义,若使用单引号,则不需要转义。
(6)将hive中的表数据导入到mysql数据库表中
sqoop export --connect jdbc:mysql://Master-Hadoop:3306/test --username root --password rootroot --table demo_log --export-dir /user/hive/warehouse/demo_log/000000_1 --input-fields-terminated-by '\0001'在进行导入之前,mysql中的表 demo_log 必须已经提起创建好了。
1.将数据从关系数据库导入文件到hive表中,--query 语句使用
sqoop import --append --connect jdbc:mysql://192.168.20.118:3306/test --username dyh --password 000000 --query "select id,age,name from userinfos where \$CONDITIONS" -m 1 --target-dir /user/hive/warehouse/userinfos2 --fields-terminated-by ",";2.将数据从关系数据库导入文件到hive表中,--columns --where 语句使用
sqoop import --append --connect jdbc:mysql://192.168.20.118:3306/test --username dyh --password 000000 --table userinfos --columns "id,age,name" --where "id > 3 and (age = 88 or age = 80)" -m 1 --target-dir /user/hive/warehouse/userinfos2 --fields-terminated-by ",";注意:--target-dir /user/hive/warehouse/userinfos2 可以用 --hive-import --hive-table userinfos2 进行替换
(6)Hdfs与Hive之间数据
1.从Hive导出到本地系统
hive> insert overwrite local directory '/home/wyp/wyp'
> select * from wyp;2.从本地系统到Hive中
先在Hive里面创建好表,
hive> create table wyp
> (id int, name string,
> age int, tel string)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '\t'
> STORED AS TEXTFILE;
OK
Time taken: 2.832 seconds本地文件系统里面有个/home/wyp/wyp.txt文件
[wyp@master ~]$ cat wyp.txt
1 wyp 25 13188888888888
2 test 30 13888888888888
3 zs 34 899314121wyp.txt文件中的数据列之间是使用\t分割的,可以通过下面的语句将这个文件里面的数据导入到wyp表里面,操作如下:
hive> load data local inpath 'wyp.txt' into table wyp;
Copying data from file:/home/wyp/wyp.txt
Copying file: file:/home/wyp/wyp.txt
Loading data to table default.wyp
Table default.wyp stats:
[num_partitions: 0, num_files: 1, num_rows: 0, total_size: 67]
OK
Time taken: 5.967 seconds2.从Hive导出到HDFS
hive> insert overwrite directory '/home/wyp/hdfs'
> select * from wyp;免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务


