本篇内容主要讲解“用分表存储提高性能的方法有哪些”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“用分表存储提高性能的方法有哪些”吧!
首先,童家旺介绍了他认为的什么是优化:第一、做任何事情最快的方法就是什么也不做。

▲支付宝资深数据库架构师童家旺
第二、不访问不必要的数据:使用B*Tree/hash等方法定位必要的数据。使用column Store或分表的方式将数据分开存储。使用Bloom filter算法排除空值查询。
第三、合理的利用硬件来提升访问效率:使用缓存消除对数据的重复访问。使用批量处理来减少磁盘的Seek操作。使用批量处理来减少网络的Round Trip。使用SSD来提升磁盘访问效率。
响应时间和吞吐量之间的关系
1、性能。衡量完成特定任务的速度或效率。
2、响应时间。衡量系统与用户交互式多久能够发出响应。
3、吞吐量。衡量系统在单位时间里可以完成的任务量。
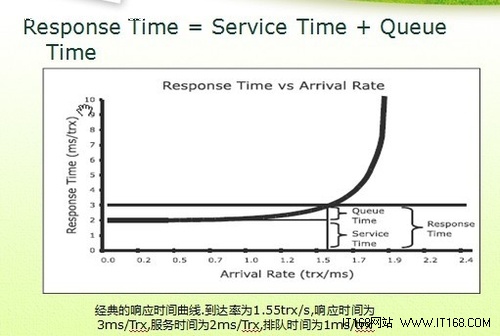
▲反应时间
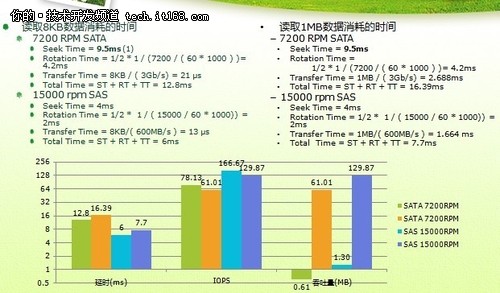
▲传统磁盘的访问特性
B*Tree优化数据访问介绍
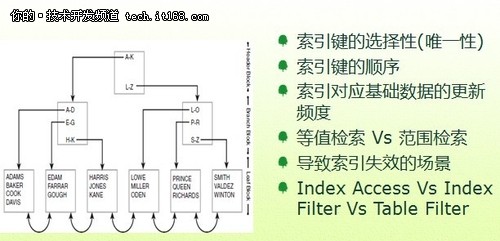
▲B*Tree优化数据访问
B*Tree优化数据访问模拟场景

▲B*Tree优化数据访问模拟场景
童家旺通过阿里巴巴的真实应用场景介绍了如何用分表存储来提高性能。
一、场景介绍:
1、表VeryBigTable含有30个列
2、表的记录数为50,000,000条
3、平均每个用户为300条左右
4、其中有2个列属于详细描述字段,平均长度为2k
5、其它的列的总长度平均为250个字节
6、此表上的查询有两种模式
7、列出表中的主要信息(每次20条,不包含详细信息,90%的查询)
8、查看记录的详细信息(10%的查询)
9、保存与Oracle数据库,默认block_size(8k)
二、要求:
1、对此业务进行优化
2、分析数据,说服开发部门实施此优化
三、性能分析
1、每块记录数
8192 * 0.80(1) / 250 = 25.5 (主表)
8192 * 0.80 / 2000 = 3.27(详情表)
8192 * 0.80 / ( 2000 + 250 ) = 2.91
2、访问的逻辑IO(内存块访问)
List的查询代价
改进后=( 300/25.5 ) * y + 4 + x = 4 + x + 11.8y = 4(2) + 7(3) + 11.8 * 1.5(4) = 28.7
改进前=( 300/2.91 ) * y + 4 + x = 4 + x + 103.y = 4 + 7 + 103 * 1.5 = 165.5
3、访问涉及到的物理读(磁盘块访问)
List的查询代价(逻辑IO * ( 1 – 命中率 ))
改进后=28.7 * ( 1 – 0.85(5)) = 4.305
改进前=165.5 * ( 1 – 0.85 ) = 24.825
4、访问时间(ms)
改进前=逻辑IO时间+物理IO时间= 28.7 * 0.01(6) + 4.305 * 7(7) = 30.422ms
改进后=逻辑IO时间+物理IO时间= 165.5 * 0.01 + 24.825 * 7 = 175.43ms
到此,相信大家对“用分表存储提高性能的方法有哪些”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





