这篇文章将为大家详细讲解有关UNIX中的进程及线程模型是怎样的,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
UNIX的传统倾向于将一个任务交给一个进程全权受理,但是一个任务内部也不仅仅是一个执行绪,比如一个公司的所有成员,大家都在做同一件事,每个人却只
负责一部分,粒度减小之后,所有的事情便可以同时进行,不管怎样,大家还都共享着所有的资源。因此就出现了线程。线程其实就是共享资源的不同的执行绪。线程的语义和朴素的UNIX进程是不同的。
朴素的UNIX进程依托于著名的fork调用,
就是这个fork调用让UNIX进程和Windows进程截然不同,也正是因为这个fork调用,使二者没有兼容的余地。这个fork调用的根源有久远的
历史。早在UNIX之前的大型操作系统中,它就存在了,UNIX刚出现的1969年,其实并未引入fork调用,当时之有两个固定的进程连接两个终端。当
fork调用引入后,进程的数量便快速增加了,注意,此时暂且还没有exec调用!
在理解fork背后的哲学之前,先看一下什么是fork。fork就是叉子,由同一个叉子柄逐渐分叉,变成一把叉子,也类似那种道生一,一生二,二生三,
三生万物。我们看到,有了fork,理论上可以生成无数的进程,它们都可以向上回溯到相同的根!为何UNIX会采用这个模型?我们首先要理解,在还没有
“可执行文件”概念的时候,进程意味着什么。
试想程序最初是怎么录入到计算机的。今天它们理所当然地存在于磁盘上,作为“可执行文件”已经深入人心,可是在1950-1960年代初,程序都是现场录
入的,通过原始的纸带或者携带很重的磁带,文件系统还没有概念,整个纸带,磁带上的内容就是计算机要执行的程序,执行完了,想执行另一个程序,就要换介
质...人们写一个程序当然是为了做一件不止做一次的事,因此如果可以有多个“进程”同时执行纸带/磁带上的程序,系统的吞吐率将大大提高,注意,多个进
程执行的是同一个程序!这是最朴素的分时系统进程模型。fork在伯克利分时系统应运而生!fork提供了复制当前执行流的手段,fork出来的所有子进
程可以方便地执行相同的代码。
这个著名的fork调用深深影响了人们如何解释分时系统!自然而然在1970年代初引入了朴素的UNIX,说fork调用著名,就是因为它跟随
UNIX(以及类UNIX,比如Linux)至今,直接影响了UNIX的进程模型。现在总结UNIX为何采用fork调用来生成进程。我们知道从0到1很
难,从1到2相对容易,也比较难,从2到3...就很简单了。这就是道生一,...三生万物!1969年的UNIX中已经有了两个进程,使用fork可以
超级简单地实现二生三,三生万物,于是,也许是一种巧合,早先的伯克利分时系统的fork正好就在那里,便被托马斯引入了UNIX。
我想说一下为何是三生万物而不是二生万物。道生一这个是最难的,我们都知道。0和1是两个极其特殊的数字,0更加特殊。2也比较特殊,但是3就很一般了,
为何2特殊呢?我不想用博弈理论来描述,只是举一个例子,2个人在一起,闻到一股屁味,每个人都肯定能百分百确定是谁放的,如果是我,那我肯定知道,如果
我没有放,那肯定是对方,当然两人一起放的几率也是有的。但是3个人在一起的时候,除了真正放屁的那个人之外的2个人根本无法判断这个屁到底是谁放的。这
就是3和0,1,2的本质区别。所以三生万物。
在UNIX伊始,进程的概念和其史前前辈是一致的,那个时
候文件系统相当不成熟,程序员关注的是执行好不容易写好的任务而不是编写任务本身(首先是没有那么大的需求,其次是信息存储是一个问题,没有互联网,可以
对比一下如今的AppStore...)。fork调用便直接将UNIX的进程组织成了tree,于是:
1.0号swap/sched进程和1号init进程便有了特殊地位;
2.形成了谁fork谁wait并回收的模型,在tree组织中这个很重要,便于资源回收;
3.如果父进程先退出,将所有子进程过继给init,这导致init必须存在且不容退出,总之,任何进程不能脱离整个进程tree。
总之,朴素的UNIX进程就是处在一棵树的某个节点的可执行对象。注意,它是可执行对象。
UNIX进程模型就是在上述基本原则上构建的,除此之外,在外围,UNIX延续了歇菜的Multics项目的shell思想,为每一个终端开放了一个
shell。shell是UNIX系统的第二个重要特征(如果先不说文件抽象的话!),它需要fork出来的进程exec出一个新的不同的执行流。从以上
fork/exec的历史上看,它们从一开始就是分离的,这就构建了完整的UNIX进程模型:fork+exec。
我们看一下UNIX的进程模型可以构建哪些东西。早期的UNIX将进程进行了组织,伙同终端的概念,UNIX给出了进程组,会话的概念。
进程组是相关联的一组进程的集合,比如管道符连接的各个命令。更多的是它们之间的关联由用户来解释。会话则是进程组的集合,会话的意义在于用户可以方便地
让多个进程组以某种形式共享终端访问权。因为坐在一个终端前的是一个人,他每次执行一个操作,这个操作作用给谁就是一个问题。他可以创建一个会话,该会话
内创建多个进程组,他以自己的方式让不同的进程组轮流成为前台进程组从而操作它。会话和进程组的概念可以理解成由操作员控制的分时系统,只是调度者不再是
操作系统,而成了终端前的操作员。和每个CPU同时只能有一个进程运行类似,每一个终端会话同时只能有一个前台进程组。
我们可以看到,UNIX进程模型构建的进程组织自然而然形成了一个分级的分时调度层次,最底层是进程,由操作系统内核调度,然后是进程组,协作完成一个任
务,组织多个进程,由创建所属会话的操作员调度。在这个分级的层次底层,所有的进程组织成一棵tree。这就是完整的UNIX进程模型构建的图景。之所以
可以构建如此美丽的图景,fork+exec是基本原则,fork和exec之间,给了进程更多的控制自己的空间,如何控制自己属于哪一个组或者会话,由
进程自己决定而不是调用者决定,相反的例子请看一下Win32
API的CreateProcess。现在麻烦来了,线程出现了,该怎么办?如果你想知道Linux是怎么创造历史的,请直接跳到最后。
我之所以没有提及任何UNIX版本对上述构建的实现,是因为思想远比实现更重要,实现反而会拖累你构建新的模型。本文的最后,我会说明Linux是如何调和不同的进程模型之间的语义的,同时印证了UNIX进程模型的先进性。
Windows
NT虽然在很多方面都借鉴了UNIX的思想,但是在进程模型上却采用了一种截然不同的思路。Windows
NT出生的1990年代,应用已经开始遍地开花,文件系统也已经非常成熟,可执行文件的概念延续自MS-DOS时代(其实UNIXv6版本就有可执行文件
的概念,在UNIX引入exec调用之后,可执行文件仅仅是进程的后备资源,仅此而已),人们可以基于Win32
API开发大量不同的程序,然后让它们分别运行,如果你想让一个程序执行多次,多点击它几次便是了。
在这样的时代,正如本文最初所说的,执行的粒度细化到了一个程序的内部。一个应用程序要完成一项任务,需要做不同的几件事,可能需要同时进行这几件事,类
似数学中的统筹方法。进程,在WinNT中也可以等同于从可执行文件中抽取出来的命名资源集合,已经不再适合作为可执行的对象,真正可执行的对象成了线
程。此时的进程只是提供了一个资源环境,线程使用这些可以共享的资源共同完成具体的事情。这种提供资源环境的进程模型我称为资源模型。
在本小节,我虽然以WinNT作为例子来描述另外一种进程模型,只是因为它作为这种模型的代表比较纯粹。实际上,很多的UNIX版本也在努力融合fork模型和资源模型这两者,企图既能继承UNIX的语义,又能实现多线程调度。
首先,fork模型和资源模型的冲突是明显的,典型体现于以下两个方面:
1.信号问题:到底哪个线程执行信号处理;
2.fork语义:假设已经运行了一个线程,在其中执行了fork,如何来解释fork的是哪个执行流;
其中第一个问题比较好解决,规定如果不是线程自身引发的异常导致的信号,就由任意线程来处理,反之由引发异常的线程来处理。第二个问题比较棘手,棘手之处在于某个UNIX是怎么实现进程模型的。
在进程结构体或者u区中维护一个链表,保存线程控制块指针!Oh,NO!这是怎么回事啊!UNIX怎么会忘了可执行的对象是进程啊!如此一来,进程岂不成
了线程的容器?直接倒向了资源模型,然而自己确实是纯正的UNIX!设计LWP是一个好方案吗?可能是,但是它引入很多的高层抽象,显得复杂了,如果几年
后再引入一个新的什么什么程呢?总之,任何修改朴素UNIX进程模型的方法都不是好方法。那么用户库级别的线程呢?这不属于内核的范畴,但表现了内核的无
能为力。
抛开实现,回到思想。我们再来看看进程,进程组,会话之间的关系,最基本的可执行对象是进程,上面的进程组,会话都是以某种组织形式对进程集合的封装,每
个集合都有一系列的资源可供这个集合中的进程共享。比如会话的环境变量,进程组的命令行变量等,线程是什么呢,线程不就是一组执行流的集合共享内存地址空
间吗?明白了些什么吗?如果不明白,我们可以把UNIX进程模型图景中的进程改成调度实体,只需要在这个图景的基础上往下走一层,线程自然而然就被支持
了:
线程,线程集合,进程组,会话...
换成调度实体的说法,就是:
调度实体,调度实体组,进程组,会话...
就
像进程组里面可以只有一个进程,组ID等于进程ID一样,进程里面也可以只有一个线程,线程ID就是进程ID。一切都统一到这个UNIX进程模型的图景中
了,如果一个线程集合只有一个线程,那么我们就称其为进程,如果拥有不止一个线程,我们就称这个集合为进程,而集合的元素为线程。其实,此时此刻,怎么称
呼已经无所谓了。
现在还缺什么?缺的是如何实现线程集合共享内存地址空间。传统的UNIX fork模型无疑无法做到这一点,因为它没有任何参数用来指示实现这种行为。于是需要稍微修改一下fork语义,引入一个clone调用,含有用户可以控制的参数:
int clone(int (*fn)(void *), void *child_stack, int flags, void *arg, ... /* pid_t *ptid, struct user_desc *tls, pid_t *ctid */ );
用户不但可以控制用户栈的位置,还可以有诸多的flags可供选择,如果要共享调用者的内存,CLONE_VM这个标志无疑是需要的,当然想clone线程不仅仅需要这一个标志,这里就不细说了,具体可以参考NPTL最新规范。
Linux
实现的线程支持非常帅,它几乎没有触动任何已经有的task_struct结构体,也没有改变任何既有的fork语义。它只是引入了一个PID类型,叫做
TGID,即进程组ID。Linux中的可执行对象就是task_struct,而且只有task_struct。每一个task_struct拥有不止
一个ID,依照这些ID的不同的解释方式即不同的类型,将task_struct定位到一个进程或者是一个进程的某个线程。ID类型如下所示:
enum pid_type
{
PIDTYPE_PID,
PIDTYPE_TGID,
PIDTYPE_PGID,
PIDTYPE_SID,
PIDTYPE_MAX
};
其中:
PIDTYPE_PID:调度实体ID。如果该task_struct是一个进程的线程,那么它就是线程ID,如果该进程只有唯一的线程,那么它同时也是进程ID;
PIDTYPE_TGID,:线程集合ID。如果该task_struct所属的进程拥有多个线程,它就是进程ID,如果只有一个线程,它等同于PIDTYPE_PID;
PIDTYPE_PGID:进程组ID。不解释;
PIDTYPE_SID:会话ID。不解释。
根据上述解释,不管一个进程拥有一个线程还是拥有多个线程,其进程ID即PID均等于PIDTYPE_TGID标识的ID。而PIDTYPE_PID标识的ID则根据具体情况给予不同的解释。具体实施如下:
1.每一个task_struct均有一个本PID命名空间内唯一的ID标识符,初始化时将其同时赋给进程ID和线程ID;
2.如果该task_struct是一个进程的第一个线程,即由标准的fork调用创建,那么保持1的初始化数值不变;
3.如果该task_struct不是一个进程的第一个线程,即由带有CLONE_VM等的clone调用创建,那么将当前调用者的PIDTYPE_TGID标识的ID覆盖新task_struct的PIDTYPE_TGID标识的ID;
4.关于进程组ID以及会话ID的设置,有专门的setpgid, setpgrp,setsid等系统调用来完成,实现很类似上述进程和线程;
5.每个task_struct中有4个pid结构体,将这些pid结构体而不是task_struct本身用链表连接起来,指示谁是进程,谁是哪个进程的线程,谁是哪个进程组当头的组成员...
总之,在Linux中,不管是线程,还是进程,都是使用task_struct这个结构体,由其PID type的值的连接方式指示如何构建UNIX进程模型的图景,这真的是太帅了。个人认为还是用一张图表示连接方式比较直观,文字表达在这方面弱爆了:
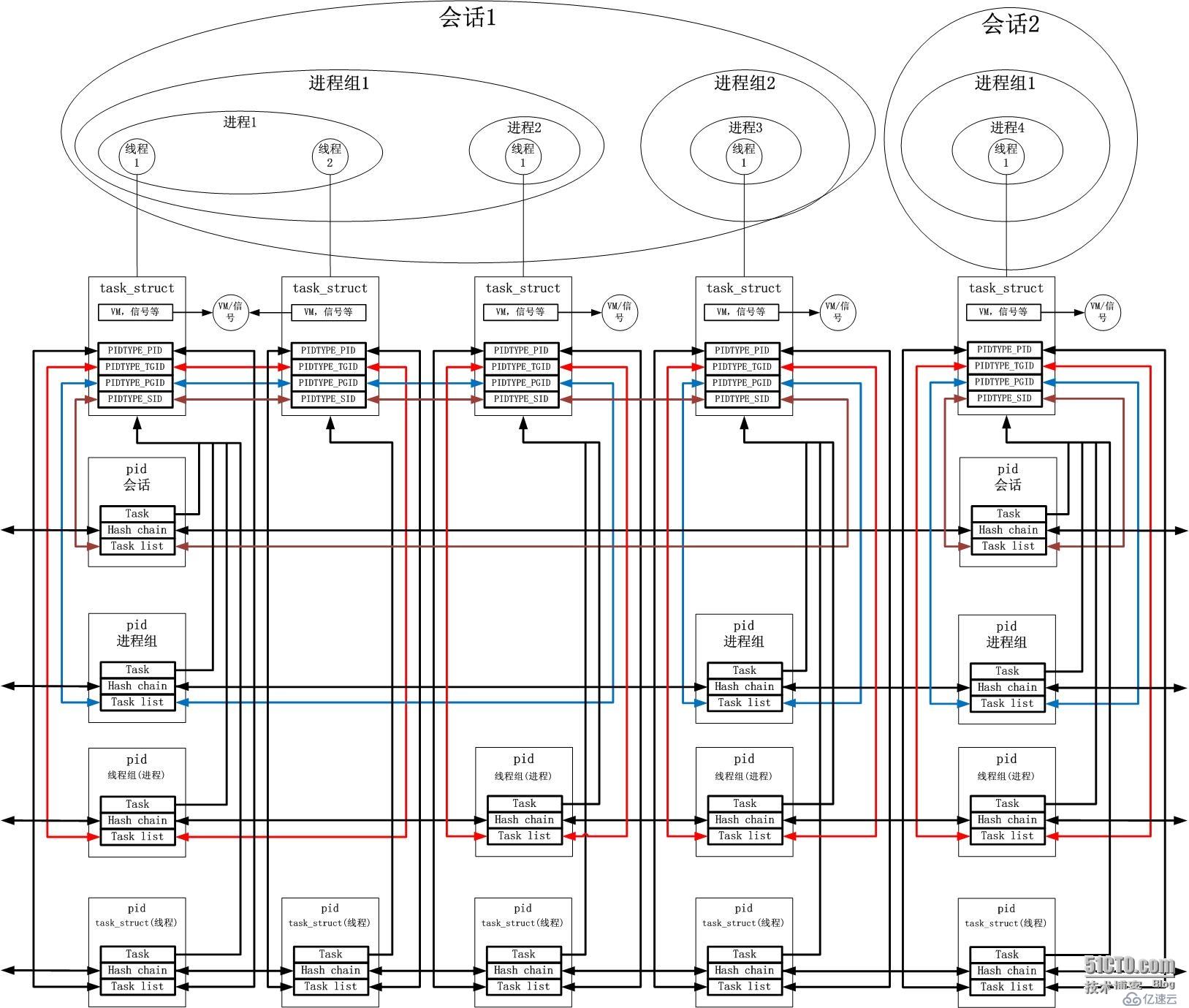
如
果理解了上面的图,就会明白Linux在实现UNIX进程模型方面做的是多么帅。如此精简的一个模型和Linux如此精简的实现正好搭配,不知为何被传统
的UNIX引到了那么复杂的方向...Linux的实现明显洞察到了UNIX进程模型的层次化结构,即进程,进程组,会话这三个层次,如果再往下延伸一个
层次,将task_struct向下移动到最底层,就基本绘制出了上面的图景。
关于UNIX中的进程及线程模型是怎样的就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





