LinuxдёӯиҝӣзЁӢеҶ…ж ёж ҲжҳҜд»Җд№Ҳ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚдәҶLinuxдёӯиҝӣзЁӢеҶ…ж ёж ҲжҳҜд»Җд№ҲпјҢе…·жңүдёҖе®ҡеҖҹйүҙд»·еҖјпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢеҸҜд»ҘеҸӮиҖғдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« д№ӢеҗҺеӨ§жңү收иҺ·пјҢдёӢйқўи®©е°Ҹзј–еёҰзқҖеӨ§е®¶дёҖиө·дәҶи§ЈдёҖдёӢгҖӮ
д»Җд№ҲжҳҜиҝӣзЁӢзҡ„вҖңеҶ…ж ёж ҲвҖқпјҹ
еңЁжҜҸдёҖдёӘиҝӣзЁӢзҡ„з”ҹе‘Ҫе‘ЁжңҹдёӯпјҢеҝ…然дјҡйҖҡиҝҮеҲ°зі»з»ҹи°ғз”Ёйҷ·е…ҘеҶ…ж ёгҖӮеңЁжү§иЎҢзі»з»ҹи°ғз”Ёйҷ·е…ҘеҶ…ж ёд№ӢеҗҺпјҢиҝҷдәӣеҶ…ж ёд»Јз ҒжүҖдҪҝз”Ёзҡ„ж Ҳ并дёҚжҳҜеҺҹе…Ҳз”ЁжҲ·з©әй—ҙдёӯзҡ„ж ҲпјҢиҖҢжҳҜдёҖдёӘеҶ…ж ёз©әй—ҙзҡ„ж ҲпјҢиҝҷдёӘз§°дҪңиҝӣзЁӢзҡ„вҖңеҶ…ж ёж ҲвҖқгҖӮ
жҜ”еҰӮпјҢжңүдёҖдёӘз®ҖеҚ•зҡ„еӯ—з¬Ұй©ұеҠЁе®һзҺ°дәҶopenж–№жі•гҖӮеңЁиҝҷдёӘй©ұеҠЁжҢӮиҪҪеҗҺпјҢеә”з”ЁзЁӢеәҸеҜ№йӮЈдёӘй©ұеҠЁжүҖеҜ№еә”зҡ„и®ҫеӨҮиҠӮзӮ№жү§иЎҢopenж“ҚдҪңпјҢиҝҷдёӘеә”з”ЁзЁӢеәҸзҡ„openе…¶е®һе°ұйҖҡиҝҮglibеә“и°ғз”ЁдәҶLinuxзҡ„openзі»з»ҹи°ғз”ЁпјҢжү§иЎҢзі»з»ҹи°ғз”Ёйҷ·е…ҘеҶ…ж ёеҗҺпјҢеӨ„зҗҶеҷЁиҪ¬жҚўдёәдәҶзү№жқғжЁЎејҸпјҲе…·дҪ“зҡ„иҪ¬жҚўжңәеҲ¶еӣ жһ„жһ¶иҖҢејӮпјҢеҜ№дәҺARMжқҘиҜҙжҷ®йҖҡжЁЎејҸе’Ңз”ЁжҲ·жЁЎејҸзҡ„зҡ„ж Ҳй’ҲпјҲSPпјүжҳҜдёҚеҗҢзҡ„еҜ„еӯҳеҷЁпјүпјҢжӯӨж—¶дҪҝз”Ёзҡ„ж ҲжҢҮй’Ҳе°ұжҳҜеҶ…ж ёж ҲжҢҮй’ҲпјҢд»–жҢҮеҗ‘еҶ…ж ёдёәжҜҸдёӘиҝӣзЁӢеҲҶй…Қзҡ„еҶ…ж ёж Ҳз©әй—ҙгҖӮ
еҶ…ж ёж Ҳзҡ„дҪңз”Ё
жҲ‘дёӘдәәзҡ„зҗҶи§ЈжҳҜпјҡеңЁйҷ·е…ҘеҶ…ж ёеҗҺпјҢзі»з»ҹи°ғз”Ёдёӯд№ҹжҳҜеӯҳеңЁеҮҪж•°и°ғз”Ёе’ҢиҮӘеҠЁеҸҳйҮҸпјҢиҝҷдәӣйғҪйңҖиҰҒж Ҳж”ҜжҢҒгҖӮз”ЁжҲ·з©әй—ҙзҡ„ж Ҳжҳҫ然дёҚе®үе…ЁпјҢйңҖиҰҒеҶ…ж ёж Ҳзҡ„ж”ҜжҢҒгҖӮжӯӨеӨ–пјҢеҶ…ж ёж ҲеҗҢж—¶з”ЁдәҺдҝқеӯҳдёҖдәӣзі»з»ҹи°ғз”ЁеүҚзҡ„еә”з”ЁеұӮдҝЎжҒҜпјҲеҰӮз”ЁжҲ·з©әй—ҙж ҲжҢҮй’ҲгҖҒзі»з»ҹи°ғз”ЁеҸӮж•°пјүгҖӮ
еҶ…ж ёж ҲдёҺиҝӣзЁӢз»“жһ„дҪ“зҡ„е…іиҒ”
жҜҸдёӘиҝӣзЁӢеңЁеҲӣе»әзҡ„ж—¶еҖҷйғҪдјҡеҫ—еҲ°дёҖдёӘеҶ…ж ёж Ҳз©әй—ҙпјҢеҶ…ж ёж Ҳе’ҢиҝӣзЁӢзҡ„еҜ№еә”е…ізі»жҳҜйҖҡиҝҮ2дёӘз»“жһ„дҪ“дёӯзҡ„жҢҮй’ҲжҲҗе‘ҳжқҘе®ҢжҲҗзҡ„пјҡ
пјҲ1пјүstruct task_struct
еңЁеӯҰд№ LinuxиҝӣзЁӢз®ЎзҗҶиӮҜе®ҡиҰҒеӯҰзҡ„з»“жһ„дҪ“пјҢеңЁеҶ…ж ёдёӯд»ЈиЎЁдәҶдёҖдёӘиҝӣзЁӢпјҢе…¶дёӯи®°еҪ•зҡ„иҝӣзЁӢзҡ„жүҖжңүзҠ¶жҖҒдҝЎжҒҜпјҢе®ҡд№үеңЁSched.h (include\linux)гҖӮ
е…¶дёӯжңүдёҖдёӘжҲҗе‘ҳпјҡvoid *stack;е°ұжҳҜжҢҮеҗ‘дёӢйқўзҡ„еҶ…ж ёж Ҳз»“жһ„дҪ“зҡ„вҖңж Ҳеә•вҖқгҖӮ
еңЁзі»з»ҹиҝҗиЎҢзҡ„ж—¶еҖҷпјҢе®ҸcurrentиҺ·еҫ—зҡ„е°ұжҳҜеҪ“еүҚиҝӣзЁӢзҡ„struct task_structз»“жһ„дҪ“гҖӮ
пјҲ2пјүеҶ…ж ёж Ҳз»“жһ„дҪ“union thread_union
union thread_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};
е…¶дёӯstruct thread_infoжҳҜи®°еҪ•йғЁеҲҶиҝӣзЁӢдҝЎжҒҜзҡ„з»“жһ„дҪ“пјҢе…¶дёӯеҢ…жӢ¬дәҶиҝӣзЁӢдёҠдёӢж–ҮдҝЎжҒҜ:
/*
* low level task data that entry.S needs immediate access to.
* __switch_to() assumes cpu_context follows immediately after cpu_domain.
*/
struct thread_info {
unsigned long flags; /* low level flags */
int preempt_count; /* 0 => preemptable, <0 => bug */
mm_segment_t addr_limit; /* address limit */
struct task_struct *task; /* main task structure */
struct exec_domain *exec_domain; /* execution domain */
__u32 cpu; /* cpu */
__u32 cpu_domain; /* cpu domain */
struct cpu_context_save cpu_context; /* cpu context */
__u32 syscall; /* syscall number */
__u8 used_cp[16]; /* thread used copro */
unsigned long tp_value;
struct crunch_state crunchstate;
union fp_state fpstate __attribute__((aligned(8)));
union vfp_state vfpstate;
#ifdef CONFIG_ARM_THUMBEE
unsigned long thumbee_state; /* ThumbEE Handler Base register */
#endif
struct restart_block restart_block;
};
е…ій”®жҳҜе…¶дёӯзҡ„taskжҲҗе‘ҳпјҢжҢҮеҗ‘зҡ„жҳҜжүҖеҲӣе»әзҡ„иҝӣзЁӢзҡ„struct task_structз»“жһ„дҪ“
иҖҢе…¶дёӯзҡ„stackжҲҗе‘ҳе°ұжҳҜеҶ…ж ёж ҲгҖӮд»ҺиҝҷйҮҢеҸҜд»ҘзңӢеҮәеҶ…ж ёж Ҳз©әй—ҙе’Ң thread_infoжҳҜе…ұз”ЁдёҖеқ—з©әй—ҙзҡ„гҖӮеҰӮжһңеҶ…ж ёж ҲжәўеҮәпјҢ thread_infoе°ұдјҡ被摧жҜҒпјҢзі»з»ҹеҙ©жәғдәҶпҪһпҪһпҪһ
еҶ…ж ёж Ҳ---struct thread_info----struct task_structдёүиҖ…зҡ„е…ізі»е…ҘдёӢеӣҫпјҡ
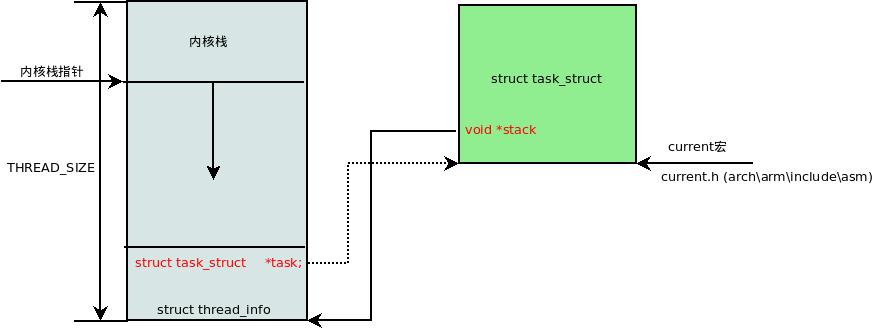
еҶ…ж ёж Ҳзҡ„дә§з”ҹ
еңЁиҝӣзЁӢиў«еҲӣе»әзҡ„ж—¶еҖҷпјҢforkж—Ҹзҡ„зі»з»ҹи°ғз”ЁдёӯдјҡеҲҶеҲ«дёәеҶ…ж ёж Ҳе’Ңstruct task_structеҲҶй…Қз©әй—ҙпјҢи°ғз”ЁиҝҮзЁӢжҳҜпјҡ
forkж—Ҹзҡ„зі»з»ҹи°ғз”Ё--->do_fork--->copy_process--->dup_task_struct
еңЁdup_task_structеҮҪж•°дёӯпјҡ
static struct task_struct *dup_task_struct(struct task_struct *orig)
{
struct task_struct *tsk;
struct thread_info *ti;
unsigned long *stackend;
int err;
prepare_to_copy(orig);
tsk = alloc_task_struct();
if (!tsk)
return NULL;
ti = alloc_thread_info(tsk);
if (!ti) {
free_task_struct(tsk);
return NULL;
}
err = arch_dup_task_struct(tsk, orig);
if (err)
goto out;
tsk->stack = ti;
err = prop_local_init_single(&tsk->dirties);
if (err)
goto out;
setup_thread_stack(tsk, orig);
......
е…¶дёӯalloc_task_structдҪҝз”ЁеҶ…ж ёзҡ„slabеҲҶй…ҚеҷЁеҺ»дёәжүҖиҰҒеҲӣе»әзҡ„иҝӣзЁӢеҲҶй…Қstruct task_structзҡ„з©әй—ҙ
иҖҢalloc_thread_infoдҪҝз”ЁеҶ…ж ёзҡ„дјҷдјҙзі»з»ҹеҺ»дёәжүҖиҰҒеҲӣе»әзҡ„иҝӣзЁӢеҲҶй…ҚеҶ…ж ёж ҲпјҲunion thread_union пјүз©әй—ҙ
жіЁж„Ҹпјҡ
еҗҺйқўзҡ„tsk->stack = ti;иҜӯеҸҘпјҢиҝҷе°ұжҳҜе…іиҒ”дәҶstruct task_structе’ҢеҶ…ж ёж Ҳ
иҖҢеңЁsetup_thread_stack(tsk, orig);дёӯпјҢе…іиҒ”дәҶеҶ…ж ёж Ҳе’Ңstruct task_structпјҡ
static inline void setup_thread_stack(struct task_struct *p, struct task_struct *org)
{
*task_thread_info(p) = *task_thread_info(org);
task_thread_info(p)->task = p;
}
еҶ…ж ёж Ҳзҡ„еӨ§е°Ҹ
з”ұдәҺжҳҜжҜҸдёҖдёӘиҝӣзЁӢйғҪеҲҶй…ҚдёҖдёӘеҶ…ж ёж Ҳз©әй—ҙпјҢжүҖд»ҘдёҚеҸҜиғҪеҲҶй…ҚеҫҲеӨ§гҖӮиҝҷдёӘеӨ§е°ҸжҳҜжһ„жһ¶зӣёе…ізҡ„пјҢдёҖиҲ¬д»ҘйЎөдёәеҚ•дҪҚгҖӮе…¶е®һд№ҹе°ұжҳҜдёҠйқўжҲ‘们зңӢеҲ°зҡ„THREAD_SIZEпјҢиҝҷдёӘеҖјдёҖиҲ¬дёә4KжҲ–иҖ…8KгҖӮеҜ№дәҺARMжһ„жһ¶пјҢиҝҷдёӘе®ҡд№үеңЁThread_info.h (arch\arm\include\asm)пјҢ
#define THREAD_SIZE_ORDER 1
#define THREAD_SIZE 8192
#define THREAD_START_SP (THREAD_SIZE - 8)
жүҖд»ҘARMзҡ„еҶ…ж ёж ҲжҳҜ8KB
еңЁпјҲеҶ…ж ёпјүй©ұеҠЁзј–зЁӢж—¶йңҖиҰҒжіЁж„Ҹзҡ„й—®йўҳпјҡ
з”ұдәҺж Ҳз©әй—ҙзҡ„йҷҗеҲ¶пјҢеңЁзј–еҶҷзҡ„й©ұеҠЁпјҲзү№еҲ«жҳҜиў«зі»з»ҹи°ғз”ЁдҪҝз”Ёзҡ„еә•еұӮеҮҪж•°пјүдёӯиҰҒжіЁж„ҸйҒҝе…ҚеҜ№ж Ҳз©әй—ҙж¶ҲиҖ—иҫғеӨ§зҡ„д»Јз ҒпјҢжҜ”еҰӮйҖ’еҪ’з®—жі•гҖҒеұҖйғЁиҮӘеҠЁеҸҳйҮҸе®ҡд№үзҡ„еӨ§е°Ҹзӯүзӯү
ж„ҹи°ўдҪ иғҪеӨҹи®Өзңҹйҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« пјҢеёҢжңӣе°Ҹзј–еҲҶдә«зҡ„вҖңLinuxдёӯиҝӣзЁӢеҶ…ж ёж ҲжҳҜд»Җд№ҲвҖқиҝҷзҜҮж–Үз« еҜ№еӨ§е®¶жңүеё®еҠ©пјҢеҗҢж—¶д№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘пјҢе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢжӣҙеӨҡзӣёе…ізҹҘиҜҶзӯүзқҖдҪ жқҘеӯҰд№ !





