#!/usr/bin/python3
#coding=UTF-8
import requests
from bs4 import BeautifulSoup
'''
需求:【python小项目】抓取编程网收费vip文章的非vip用户观看界面的url! 例如收费文章http://c.biancheng.net/view/vip_6005.html对应非收费地址是http://c.biancheng.net/view/5315.html这个网站总是有一些vip文章 但是vip文章通过百度标题是可以搜索到的,我想爬取所有这样的文章标题和网页的地址!后期看到一个vip文章,你可以通过检索标题得到非vip的观看链接地址
编写日期:2019-10-18
作者:xiaoxiaohui
说明:python3程序 而且最好在linux运行 windows下有gbk那个编码问题
'''
def get_biaoti(url):
response = requests.get(url)
response.encoding='utf-8' #如果不设置成utf8则中文乱码或者报错 参考https://www.cnblogs.com/supery007/p/8303472.html
soup = BeautifulSoup(response.text,'html.parser')
links_div = soup.find_all('h2')
return links_div[0].text
f = open("a1.txt", 'a')
for yema in range(1,500):
url = 'http://c.biancheng.net/view/'+str(yema)+'.html'
biaoti = get_biaoti(url)
print(url,biaoti)
f.write(url+'\t'+biaoti+'\n')
f.close()运行结果、收集到的文章和url对应关系截图:
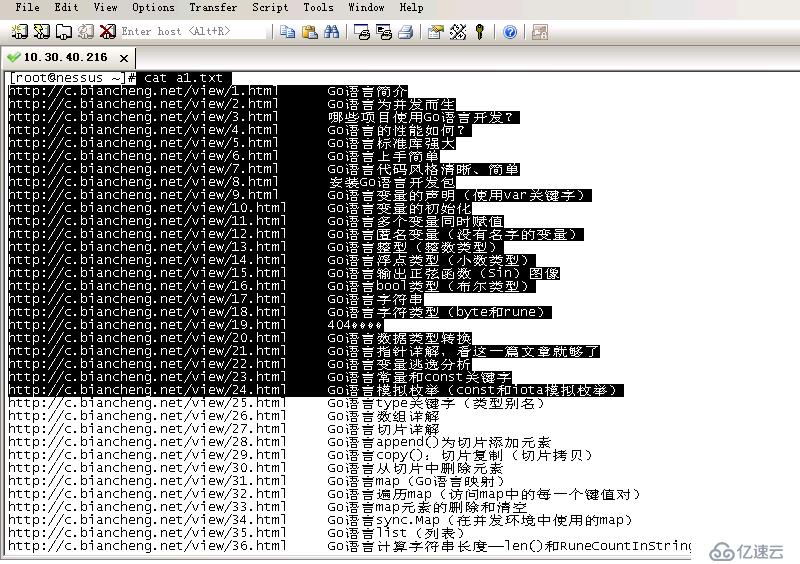
自己学到的:
这次学到的 原来我的爬虫都是爬某个div的,都是links_div = soup.find_all('div',class_="listpic"), 原来也可以直接links_div = soup.find_all('h2'),也就是带一个参数这样的
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





