首先这次学习的是利用写Python脚本对网页信息的获取,并且把他保存到我们的数据库里最后形成一个Excel表格
刚开始我们需要做一些准备:
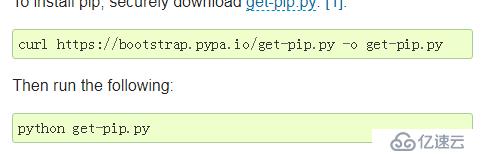
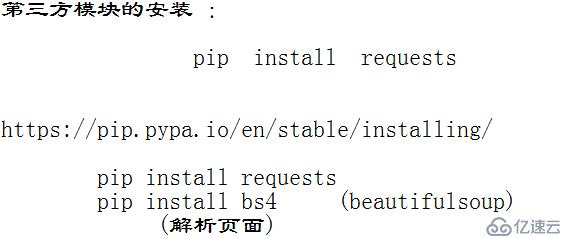
先安装第三方模块
https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-3.2.5.tgz

思路如下:
headers获取:
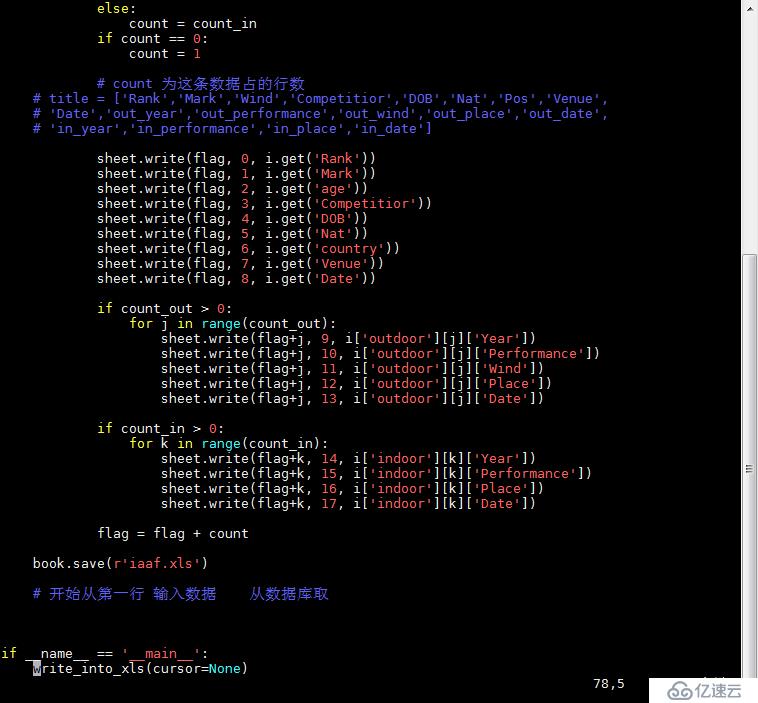
脚本1:
运行前打开mongod :
./mongod & 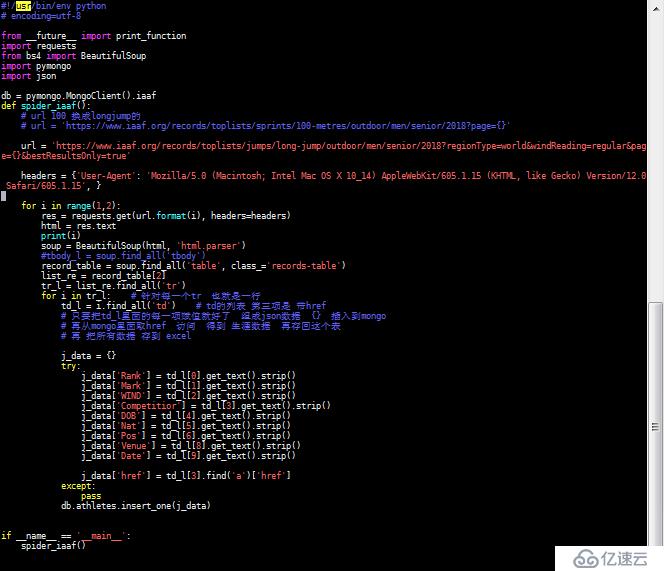
脚本2: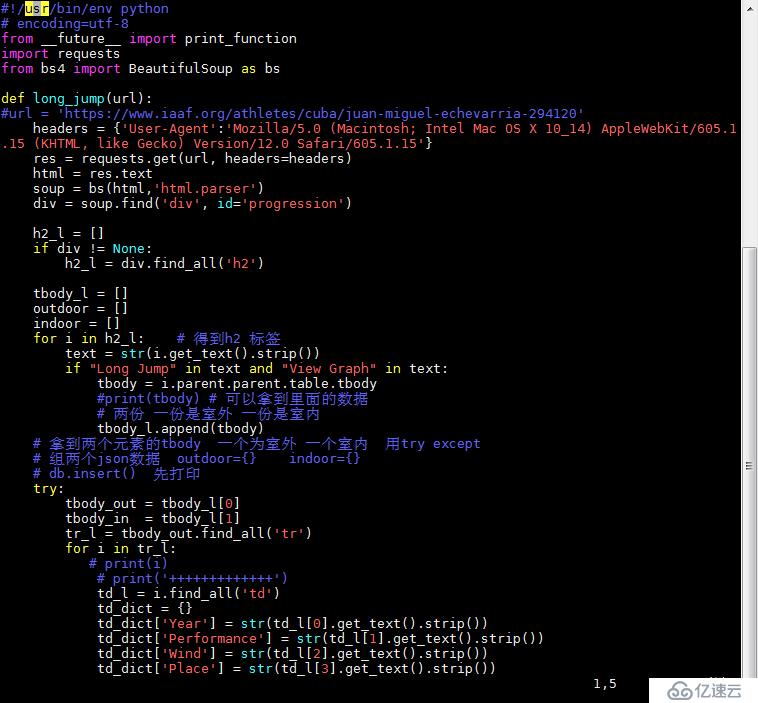
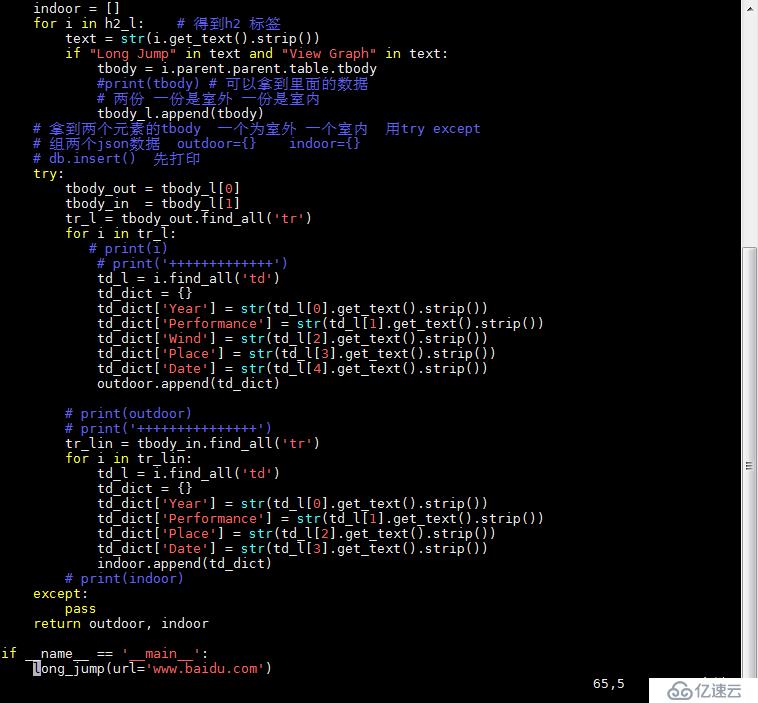
Long Jump 和 View Graph 是根据他们可以定位到我们想获取的信息的标签上
这个脚本写完不需要运行,他的url是由第三个脚本导入的
脚本3:
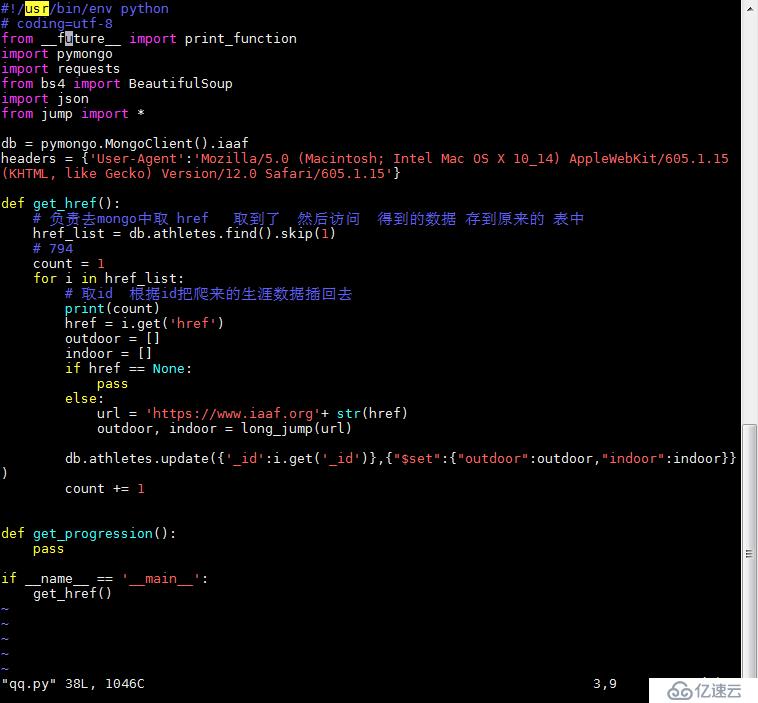
运行前都要检查MongoD是否运行,运行后可进入数据库去看我们存入的信息
在MongoDB的bin下
./mongo
use iaaf
db.athletes.find()脚本4:
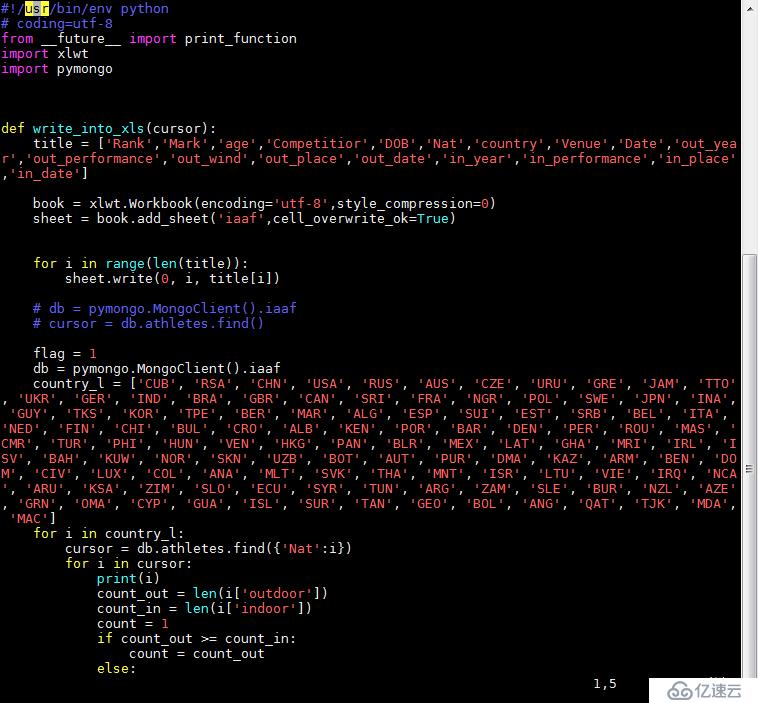
requests是一个很实用的Python HTTP客户端库,编写爬虫和测试服务器响应数据时经常会用到。可以说,Requests 完全满足如今网络的需求
1.作用:发送请求获取响应为什么使用requesst?
1)requests底层实现的是urllib2)requests在python2和python3中通用,方法完全一样
3)requests简单易用(python特性)
4)requests能够帮助我们解压响应内容(自动解压完善请求头,自动获取cookie)
pymongo是python操作 mongodb的工具包
bs4概念:
bs4库是解析、遍历、维护、"标签树"的功能库
通俗一点说就是:bs4库把HTML源代码重新进行了格式化,
从而方便我们对其中的节点、标签、属性等进行操作
2.BS4的4中对象
①Tag对象:是html中的一个标签,用BeautifulSoup就能解析出来Tag的具体内容,具体
的格式为‘soup.name‘,其中name是html下的标签。
②BeautifulSoup对象:整个html文本对象,可当作Tag对象
③NavigableString对象:标签内的文本对象
④Comment对象:是一个特殊的NavigableString对象,如果html标签内存在注释,那么它可以过滤掉注释符号保留注释文本
最常用的还是BeautifulSoup对象和Tag对象
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





