本文主要给大家简单讲讲使用pandas模块解决mysql中的重复数据问题,相关专业术语大家可以上网查查或者找一些相关书籍补充一下,这里就不涉猎了,我们就直奔主题吧,希望使用pandas模块解决mysql中的重复数据问题这篇文章可以给大家带来一些实际帮助。
直接上代码
import pymysql
import pandas as pda
conn=pymysql.connect(host="127.0.0.1",user="root",passwd="pw",db="test001",charset="utf8")
sql="select * from table001"
data1 = pda.read_sql(sql,conn)
print(data1.count())
data2 = data1.drop_duplicates(subset="big",keep="last")
data2.to_sql("table002",con=conn,flavor="mysql",if_exists="append",index=False)
print(data2.count())table001表为原始表,big为表里不能重复的字段,keep="last"代表留重复数据的最后一条,table002表为清洗完数据保存数据的表。
运行该脚本,十来分钟左右,800W条数据已经全部清洗完毕,还剩余200W条不重复数据,并且还和朋友正确的数据一条不差。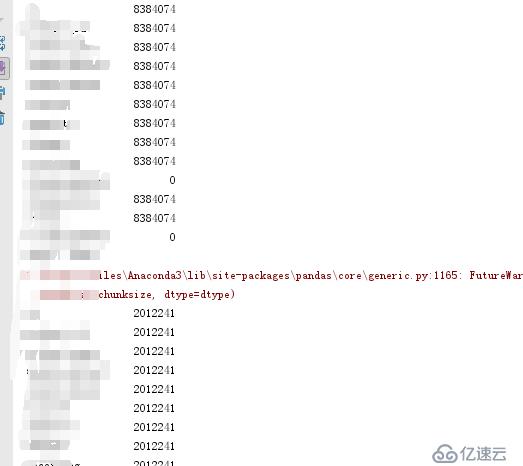
随后将数据表上传至朋友的线上云服务器,朋友验证数据都没问题。
使用pandas模块解决mysql中的重复数据问题就先给大家讲到这里,对于其它相关问题大家想要了解的可以持续关注我们的行业资讯。我们的板块内容每天都会捕捉一些行业新闻及专业知识分享给大家的。
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



