本篇文章为大家展示了使用python怎么实现逐步回归,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
逐步回归是一种线性回归模型自变量选择方法;
逐步回归的基本思想是将变量逐个引入模型,每引入一个解释变量后都要进行F检验,并对已经选入的解释变量逐个进行t检验,当原来引入的解释变量由于后面解释变量的引入变得不再显著时,则将其删除。以确保每次引入新的变量之前回归方程中只包含显著性变量。这是一个反复的过程,直到既没有显著的解释变量选入回归方程,也没有不显著的解释变量从回归方程中剔除为止。以保证最后所得到的解释变量集是最优的。
这里我们选择赤池信息量(Akaike Information Criterion)来作为自变量选择的准则,赤池信息量(AIC)达到最小:基于最大似然估计原理的模型选择准则。
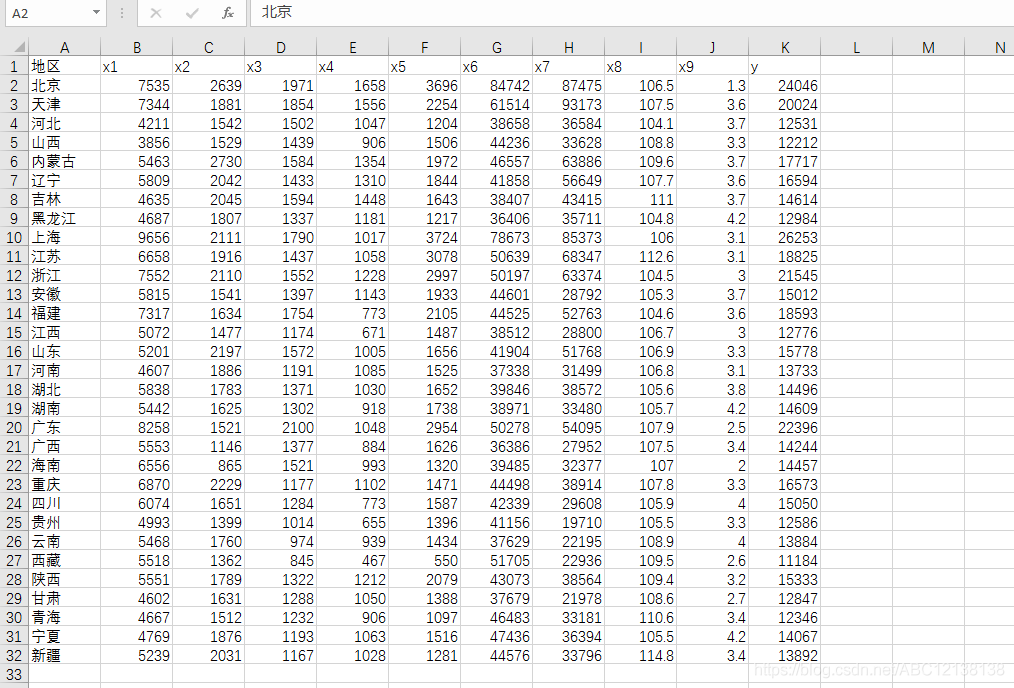
在现实生活中,影响一个地区居民消费的因素有很多,例如一个地区的人均生产总值、收入水平等等,本案例选取了9个解释变量研究城镇居民家庭平均每人全年的消费新支出y,解释变量为:
x1——居民的食品花费
x2——居民的衣着消费
x3——居民的居住花费
x4——居民的医疗保健花费
x5——居民的文教娱乐花费
x6——地区的职工平均工资
x7——地区的人均GDP
x8——地区的消费价格指数
x9——地区的失业率(%)
# -*- coding: UTF-8 -*-
import numpy as np
import statsmodels.api as sm
import statsmodels.formula.api as smf
from statsmodels.stats.api import anova_lm
import matplotlib.pyplot as plt
import pandas as pd
from patsy import dmatrices
import itertools as it
import random
# Load data 读取数据
df = pd.read_csv('data3.1.csv',encoding='gbk')
print(df)
target = 'y'
variate = set(df.columns) #获取列名
variate.remove(target) #去除无关列
variate.remove('地区')
#定义多个数组,用来分别用来添加变量,删除变量
x = []
variate_add = []
variate_del = variate.copy()
# print(variate_del)
y = random.sample(variate,3) #随机生成一个选模型,3为变量的个数
print(y)
#将随机生成的三个变量分别输入到 添加变量和删除变量的数组
for i in y:
variate_add.append(i)
x.append(i)
variate_del.remove(i)
global aic #设置全局变量 这里选择AIC值作为指标
formula="{}~{}".format("y","+".join(variate_add)) #将自变量名连接起来
aic=smf.ols(formula=formula,data=df).fit().aic #获取随机函数的AIC值,与后面的进行对比
print("随机化选模型为:{}~{},对应的AIC值为:{}".format("y","+".join(variate_add), aic))
print("\n")
#添加变量
def forwark():
score_add = []
global best_add_score
global best_add_c
print("添加变量")
for c in variate_del:
formula = "{}~{}".format("y", "+".join(variate_add+[c]))
score = smf.ols(formula = formula, data = df).fit().aic
score_add.append((score, c)) #将添加的变量,以及新的AIC值一起存储在数组中
print('自变量为{},对应的AIC值为:{}'.format("+".join(variate_add+[c]), score))
score_add.sort(reverse=True) #对数组内的数据进行排序,选择出AIC值最小的
best_add_score, best_add_c = score_add.pop()
print("最小AIC值为:{}".format(best_add_score))
print("\n")
#删除变量
def back():
score_del = []
global best_del_score
global best_del_c
print("剔除变量")
for i in x:
select = x.copy() #copy一个集合,避免重复修改到原集合
select.remove(i)
formula = "{}~{}".format("y","+".join(select))
score = smf.ols(formula = formula, data = df).fit().aic
print('自变量为{},对应的AIC值为:{}'.format("+".join(select), score))
score_del.append((score, i))
score_del.sort(reverse=True) #排序,方便将最小值输出
best_del_score, best_del_c = score_del.pop() #将最小的AIC值以及对应剔除的变量分别赋值
print("最小AIC值为:{}".format(best_del_score))
print("\n")
print("剩余变量为:{}".format(variate_del))
forwark()
back()
while variate:
# forwark()
# back()
if(aic < best_add_score < best_del_score or aic < best_del_score < best_add_score):
print("当前回归方程为最优回归方程,为{}~{},AIC值为:{}".format("y","+".join(variate_add), aic))
break
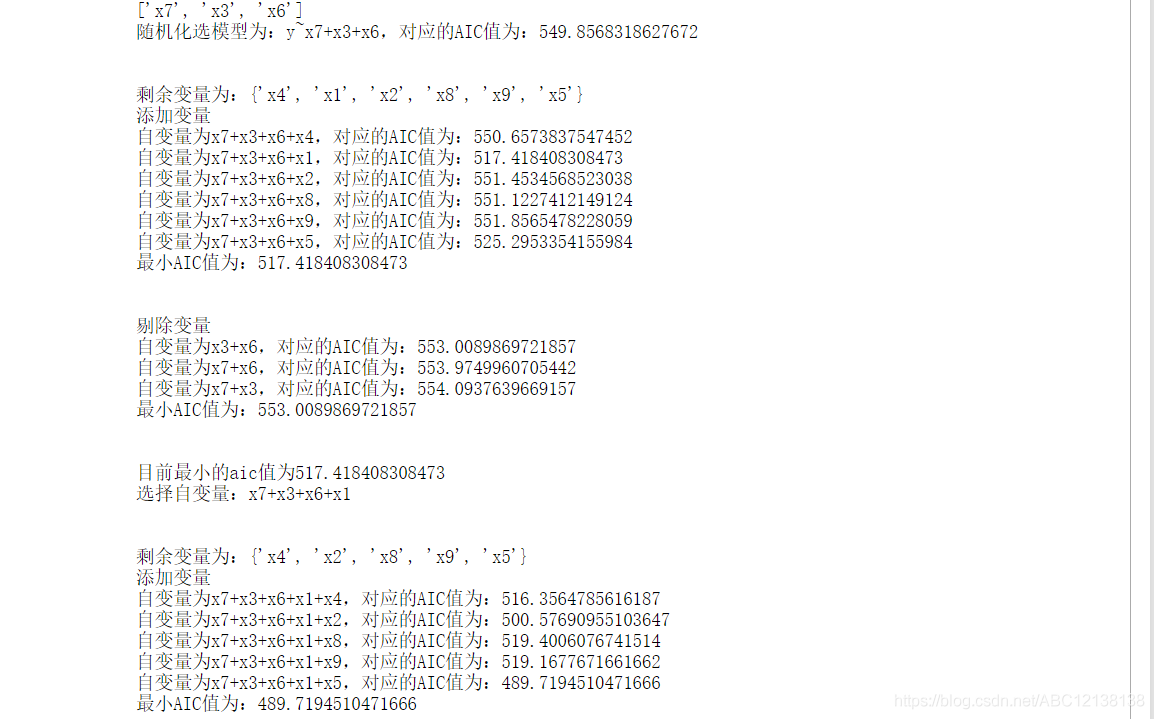
elif(best_add_score < best_del_score < aic or best_add_score < aic < best_del_score):
print("目前最小的aic值为{}".format(best_add_score))
print('选择自变量:{}'.format("+".join(variate_add + [best_add_c])))
print('\n')
variate_del.remove(best_add_c)
variate_add.append(best_add_c)
print("剩余变量为:{}".format(variate_del))
aic = best_add_score
forwark()
else:
print('当前最小AIC值为:{}'.format(best_del_score))
print('需要剔除的变量为:{}'.format(best_del_c))
aic = best_del_score #将AIC值较小的选模型AIC值赋给aic再接着下一轮的对比
x.remove(best_del_c) #在原集合上剔除选模型所对应剔除的变量
back()

上述内容就是使用python怎么实现逐步回归,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



