Redisзҡ„йқўиҜ•йўҳжңүе“Әдәӣ
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іRedis зҡ„йқўиҜ•йўҳжңүе“ӘдәӣпјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
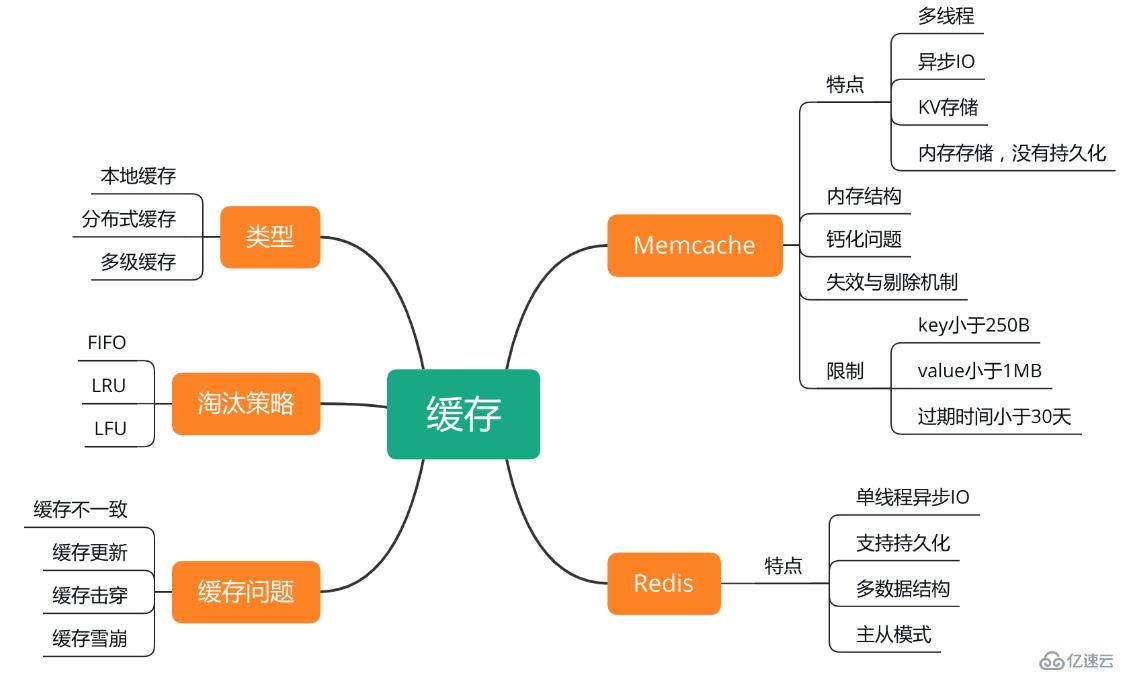
зј“еӯҳзҹҘиҜҶзӮ№
зј“еӯҳжңүе“Әдәӣзұ»еһӢпјҹ
зј“еӯҳжҳҜй«ҳ并еҸ‘еңәжҷҜдёӢжҸҗй«ҳзғӯзӮ№ж•°жҚ®и®ҝй—®жҖ§иғҪзҡ„дёҖдёӘжңүж•ҲжүӢж®өпјҢеңЁејҖеҸ‘йЎ№зӣ®ж—¶дјҡз»ҸеёёдҪҝз”ЁеҲ°гҖӮ
зј“еӯҳзҡ„зұ»еһӢеҲҶдёәпјҡжң¬ең°зј“еӯҳ гҖҒеҲҶеёғејҸзј“еӯҳ е’ҢеӨҡзә§зј“еӯҳ гҖӮ
жң¬ең°зј“еӯҳпјҡ
жң¬ең°зј“еӯҳ е°ұжҳҜеңЁиҝӣзЁӢзҡ„еҶ…еӯҳдёӯиҝӣиЎҢзј“еӯҳпјҢжҜ”еҰӮжҲ‘们зҡ„ JVM е ҶдёӯпјҢеҸҜд»Ҙз”Ё LRUMap жқҘе®һзҺ°пјҢд№ҹеҸҜд»ҘдҪҝз”Ё Ehcache иҝҷж ·зҡ„е·Ҙе…·жқҘе®һзҺ°гҖӮ
жң¬ең°зј“еӯҳжҳҜеҶ…еӯҳи®ҝй—®пјҢжІЎжңүиҝңзЁӢдәӨдә’ејҖй”ҖпјҢжҖ§иғҪжңҖеҘҪпјҢдҪҶжҳҜеҸ—йҷҗдәҺеҚ•жңәе®№йҮҸпјҢдёҖиҲ¬зј“еӯҳиҫғе°Ҹдё”ж— жі•жү©еұ•гҖӮ
еҲҶеёғејҸзј“еӯҳпјҡ
еҲҶеёғејҸзј“еӯҳ еҸҜд»ҘеҫҲеҘҪеҫ—и§ЈеҶіиҝҷдёӘй—®йўҳгҖӮ
еҲҶеёғејҸзј“еӯҳдёҖиҲ¬йғҪе…·жңүиүҜеҘҪзҡ„ж°ҙе№іжү©еұ•иғҪеҠӣпјҢеҜ№иҫғеӨ§ж•°жҚ®йҮҸзҡ„еңәжҷҜд№ҹиғҪеә”д»ҳиҮӘеҰӮгҖӮзјәзӮ№е°ұжҳҜйңҖиҰҒиҝӣиЎҢиҝңзЁӢиҜ·жұӮпјҢжҖ§иғҪдёҚеҰӮжң¬ең°зј“еӯҳгҖӮ
еӨҡзә§зј“еӯҳпјҡ
дёәдәҶе№іиЎЎиҝҷз§Қжғ…еҶөпјҢе®һйҷ…дёҡеҠЎдёӯдёҖиҲ¬йҮҮз”ЁеӨҡзә§зј“еӯҳ пјҢжң¬ең°зј“еӯҳеҸӘдҝқеӯҳи®ҝй—®йў‘зҺҮжңҖй«ҳзҡ„йғЁеҲҶзғӯзӮ№ж•°жҚ®пјҢе…¶д»–зҡ„зғӯзӮ№ж•°жҚ®ж”ҫеңЁеҲҶеёғејҸзј“еӯҳдёӯгҖӮ
еңЁзӣ®еүҚзҡ„дёҖзәҝеӨ§еҺӮдёӯпјҢиҝҷд№ҹжҳҜжңҖеёёз”Ёзҡ„зј“еӯҳж–№жЎҲпјҢеҚ•иҖғеҚ•дёҖзҡ„зј“еӯҳж–№жЎҲеҫҖеҫҖйҡҫд»Ҙж’‘дҪҸеҫҲеӨҡй«ҳ并еҸ‘зҡ„еңәжҷҜгҖӮ
ж·ҳжұ°зӯ–з•Ҙ
дёҚз®ЎжҳҜжң¬ең°зј“еӯҳиҝҳжҳҜеҲҶеёғејҸзј“еӯҳпјҢдёәдәҶдҝқиҜҒиҫғй«ҳжҖ§иғҪпјҢйғҪжҳҜдҪҝз”ЁеҶ…еӯҳжқҘдҝқеӯҳж•°жҚ®пјҢз”ұдәҺжҲҗжң¬е’ҢеҶ…еӯҳйҷҗеҲ¶пјҢеҪ“еӯҳеӮЁзҡ„ж•°жҚ®и¶…иҝҮзј“еӯҳе®№йҮҸж—¶пјҢйңҖиҰҒеҜ№зј“еӯҳзҡ„ж•°жҚ®иҝӣиЎҢеү”йҷӨгҖӮ
дёҖиҲ¬зҡ„еү”йҷӨзӯ–з•Ҙжңү FIFO ж·ҳжұ°жңҖж—©ж•°жҚ®гҖҒLRU еү”йҷӨжңҖиҝ‘жңҖе°‘дҪҝз”ЁгҖҒе’Ң LFU еү”йҷӨжңҖиҝ‘дҪҝз”Ёйў‘зҺҮжңҖдҪҺзҡ„ж•°жҚ®еҮ з§Қзӯ–з•ҘгҖӮ
noeviction :иҝ”еӣһй”ҷиҜҜеҪ“еҶ…еӯҳйҷҗеҲ¶иҫҫеҲ°е№¶дё”е®ўжҲ·з«Ҝе°қиҜ•жү§иЎҢдјҡи®©жӣҙеӨҡеҶ…еӯҳиў«дҪҝз”Ёзҡ„е‘Ҫд»ӨпјҲеӨ§йғЁеҲҶзҡ„еҶҷе…ҘжҢҮд»ӨпјҢдҪҶDELе’ҢеҮ дёӘдҫӢеӨ–пјү
allkeys-lru : е°қиҜ•еӣһ收жңҖе°‘дҪҝз”Ёзҡ„й”®пјҲLRUпјүпјҢдҪҝеҫ—ж–°ж·»еҠ зҡ„ж•°жҚ®жңүз©әй—ҙеӯҳж”ҫгҖӮ
volatile-lru : е°қиҜ•еӣһ收жңҖе°‘дҪҝз”Ёзҡ„й”®пјҲLRUпјүпјҢдҪҶд»…йҷҗдәҺеңЁиҝҮжңҹйӣҶеҗҲзҡ„й”®,дҪҝеҫ—ж–°ж·»еҠ зҡ„ж•°жҚ®жңүз©әй—ҙеӯҳж”ҫгҖӮ
allkeys-random : еӣһ收йҡҸжңәзҡ„й”®дҪҝеҫ—ж–°ж·»еҠ зҡ„ж•°жҚ®жңүз©әй—ҙеӯҳж”ҫгҖӮ
volatile-random : еӣһ收йҡҸжңәзҡ„й”®дҪҝеҫ—ж–°ж·»еҠ зҡ„ж•°жҚ®жңүз©әй—ҙеӯҳж”ҫпјҢдҪҶд»…йҷҗдәҺеңЁиҝҮжңҹйӣҶеҗҲзҡ„й”®гҖӮ
volatile-ttl : еӣһ收еңЁиҝҮжңҹйӣҶеҗҲзҡ„й”®пјҢ并且дјҳе…Ҳеӣһ收еӯҳжҙ»ж—¶й—ҙпјҲTTLпјүиҫғзҹӯзҡ„й”®,дҪҝеҫ—ж–°ж·»еҠ зҡ„ж•°жҚ®жңүз©әй—ҙеӯҳж”ҫгҖӮ
еҰӮжһңжІЎжңүй”®ж»Ўи¶іеӣһ收зҡ„еүҚжҸҗжқЎд»¶зҡ„иҜқпјҢзӯ–з•Ҙvolatile-lru , volatile-random д»ҘеҸҠvolatile-ttl е°ұе’Ңnoeviction е·®дёҚеӨҡдәҶгҖӮ
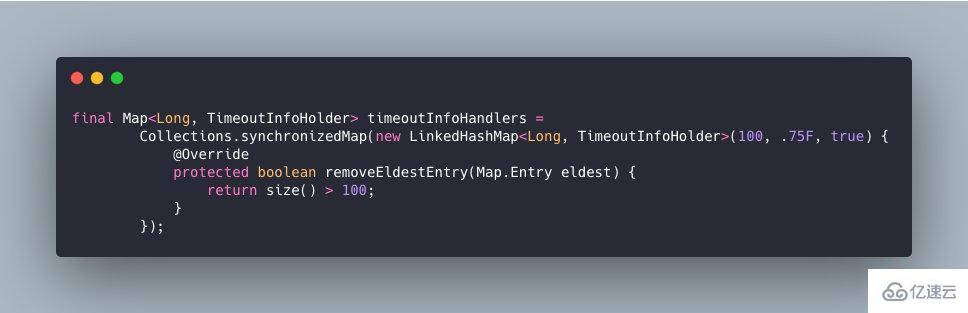
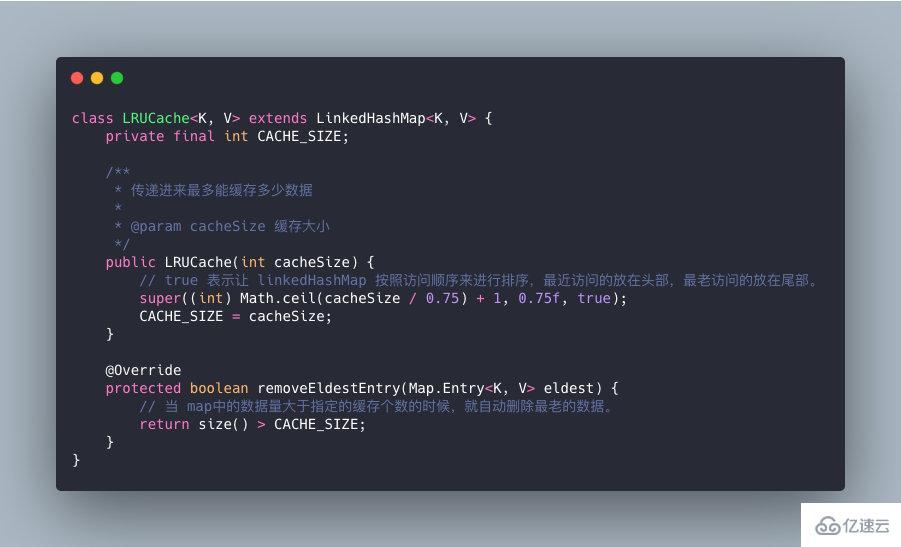
е…¶е®һеңЁеӨ§е®¶зҶҹжӮүзҡ„LinkedHashMap дёӯд№ҹе®һзҺ°дәҶLruз®—жі•зҡ„пјҢе®һзҺ°еҰӮдёӢпјҡ
еҪ“е®№йҮҸи¶…иҝҮ100ж—¶пјҢејҖе§Ӣжү§иЎҢLRU зӯ–з•Ҙпјҡе°ҶжңҖиҝ‘жңҖе°‘жңӘдҪҝз”Ёзҡ„ TimeoutInfoHolder еҜ№иұЎ evict жҺүгҖӮ
зңҹе®һйқўиҜ•дёӯдјҡи®©дҪ еҶҷLURз®—жі•пјҢдҪ еҸҜеҲ«жҗһеҺҹе§Ӣзҡ„йӮЈдёӘпјҢйӮЈзңҹTMеӨҡпјҢеҶҷдёҚе®Ңзҡ„пјҢдҪ иҰҒд№ҲжҖјдёҠйқўиҝҷдёӘпјҢиҰҒд№ҲжҖјдёӢйқўиҝҷдёӘпјҢжүҫдёҖдёӘж•°жҚ®з»“жһ„е®һзҺ°дёӢJavaзүҲжң¬зҡ„LRUиҝҳжҳҜжҜ”иҫғе®№жҳ“зҡ„пјҢзҹҘйҒ“е•ҘеҺҹзҗҶе°ұеҘҪдәҶгҖӮ
Memcache
жіЁж„ҸеҗҺйқўдјҡжҠҠ Memcache з®Җз§°дёә MCгҖӮ
е…ҲжқҘзңӢзңӢ MC зҡ„зү№зӮ№пјҡ
MC еӨ„зҗҶиҜ·жұӮж—¶дҪҝз”ЁеӨҡзәҝзЁӢејӮжӯҘ IO зҡ„ж–№ејҸпјҢеҸҜд»ҘеҗҲзҗҶеҲ©з”Ё CPU еӨҡж ёзҡ„дјҳеҠҝпјҢжҖ§иғҪйқһеёёдјҳз§Җпјӣ
MC еҠҹиғҪз®ҖеҚ•пјҢдҪҝз”ЁеҶ…еӯҳеӯҳеӮЁж•°жҚ®пјӣ
MC зҡ„еҶ…еӯҳз»“жһ„д»ҘеҸҠй’ҷеҢ–й—®йўҳжҲ‘е°ұдёҚз»ҶиҜҙдәҶпјҢеӨ§е®¶еҸҜд»ҘжҹҘзңӢе®ҳзҪ‘дәҶи§ЈдёӢпјӣ
MC еҜ№зј“еӯҳзҡ„ж•°жҚ®еҸҜд»Ҙи®ҫзҪ®еӨұж•ҲжңҹпјҢиҝҮжңҹеҗҺзҡ„ж•°жҚ®дјҡиў«жё…йҷӨпјӣ
еӨұж•Ҳзҡ„зӯ–з•ҘйҮҮ用延иҝҹеӨұж•ҲпјҢе°ұжҳҜеҪ“еҶҚж¬ЎдҪҝз”Ёж•°жҚ®ж—¶жЈҖжҹҘжҳҜеҗҰеӨұж•Ҳпјӣ
еҪ“е®№йҮҸеӯҳж»Ўж—¶пјҢдјҡеҜ№зј“еӯҳдёӯзҡ„ж•°жҚ®иҝӣиЎҢеү”йҷӨпјҢеү”йҷӨж—¶йҷӨдәҶдјҡеҜ№иҝҮжңҹ key иҝӣиЎҢжё…зҗҶпјҢиҝҳдјҡжҢү LRU зӯ–з•ҘеҜ№ж•°жҚ®иҝӣиЎҢеү”йҷӨгҖӮ
еҸҰеӨ–пјҢдҪҝз”Ё MC жңүдёҖдәӣйҷҗеҲ¶пјҢиҝҷдәӣйҷҗеҲ¶еңЁзҺ°еңЁзҡ„дә’иҒ”зҪ‘еңәжҷҜдёӢеҫҲиҮҙе‘ҪпјҢжҲҗдёәеӨ§е®¶йҖүжӢ©Redis гҖҒMongoDB
key дёҚиғҪи¶…иҝҮ 250 дёӘеӯ—иҠӮпјӣ
value дёҚиғҪи¶…иҝҮ 1M еӯ—иҠӮпјӣ
key зҡ„жңҖеӨ§еӨұж•Ҳж—¶й—ҙжҳҜ 30 еӨ©пјӣ
еҸӘж”ҜжҢҒ K-V з»“жһ„пјҢдёҚжҸҗдҫӣжҢҒд№…еҢ–е’Ңдё»д»ҺеҗҢжӯҘеҠҹиғҪгҖӮ
Redis
е…Ҳз®ҖеҚ•иҜҙдёҖдёӢ Redis зҡ„зү№зӮ№пјҢж–№дҫҝе’Ң MC жҜ”иҫғгҖӮ
дёҺ MC дёҚеҗҢзҡ„жҳҜпјҢRedis йҮҮз”ЁеҚ•зәҝзЁӢжЁЎејҸеӨ„зҗҶиҜ·жұӮгҖӮиҝҷж ·еҒҡзҡ„еҺҹеӣ жңү 2 дёӘпјҡдёҖдёӘжҳҜеӣ дёәйҮҮз”ЁдәҶйқһйҳ»еЎһзҡ„ејӮжӯҘдәӢ件еӨ„зҗҶжңәеҲ¶пјӣеҸҰдёҖдёӘжҳҜзј“еӯҳж•°жҚ®йғҪжҳҜеҶ…еӯҳж“ҚдҪң IO ж—¶й—ҙдёҚдјҡеӨӘй•ҝпјҢеҚ•зәҝзЁӢеҸҜд»ҘйҒҝе…ҚзәҝзЁӢдёҠдёӢж–ҮеҲҮжҚўдә§з”ҹзҡ„д»Јд»·гҖӮ
Redis ж”ҜжҢҒжҢҒд№…еҢ–пјҢжүҖд»Ҙ Redis дёҚд»…д»…еҸҜд»Ҙз”ЁдҪңзј“еӯҳпјҢд№ҹеҸҜд»Ҙз”ЁдҪң NoSQL ж•°жҚ®еә“гҖӮ
зӣёжҜ” MCпјҢRedis иҝҳжңүдёҖдёӘйқһеёёеӨ§зҡ„дјҳеҠҝпјҢе°ұжҳҜйҷӨдәҶ K-V д№ӢеӨ–пјҢиҝҳж”ҜжҢҒеӨҡз§Қж•°жҚ®ж јејҸпјҢдҫӢеҰӮ listгҖҒsetгҖҒsorted setгҖҒhash зӯүгҖӮ
Redis жҸҗдҫӣдё»д»ҺеҗҢжӯҘжңәеҲ¶пјҢд»ҘеҸҠ Cluster йӣҶзҫӨйғЁзҪІиғҪеҠӣпјҢиғҪеӨҹжҸҗдҫӣй«ҳеҸҜз”ЁжңҚеҠЎгҖӮ
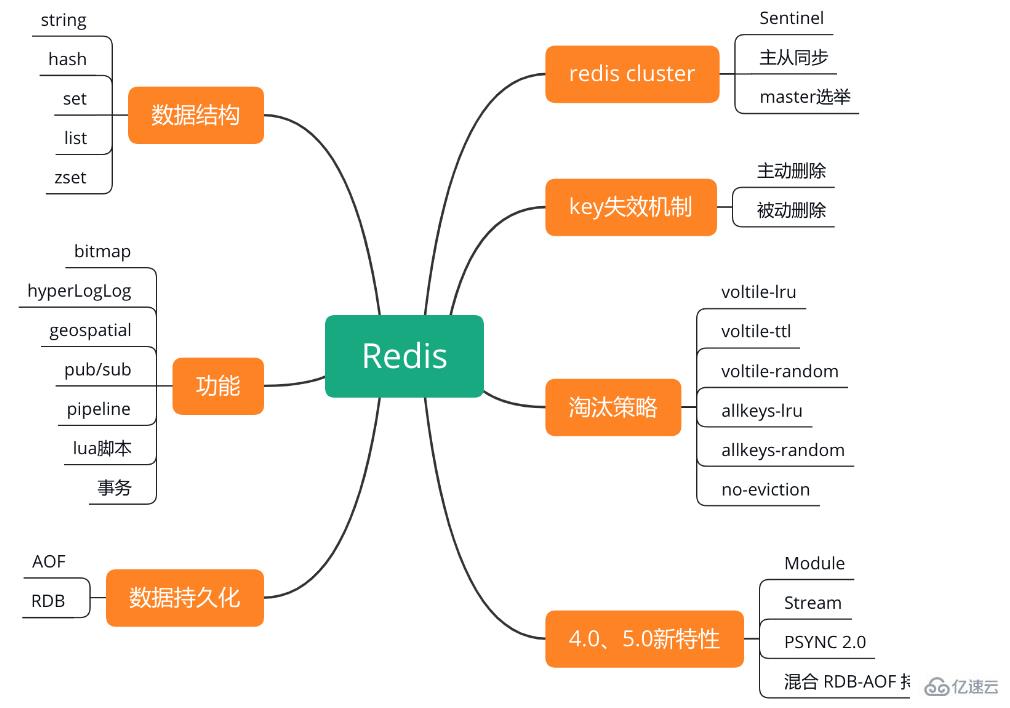
иҜҰи§Ј Redis
Redis зҡ„зҹҘиҜҶзӮ№з»“жһ„еҰӮдёӢеӣҫжүҖзӨәгҖӮ
еҠҹиғҪ
жқҘзңӢ Redis жҸҗдҫӣзҡ„еҠҹиғҪжңүе“Әдәӣеҗ§пјҒ
жҲ‘们е…ҲзңӢеҹәзЎҖзұ»еһӢпјҡ Stringпјҡ
String зұ»еһӢжҳҜ Redis дёӯжңҖеёёдҪҝз”Ёзҡ„зұ»еһӢпјҢеҶ…йғЁзҡ„е®һзҺ°жҳҜйҖҡиҝҮ SDS пјҲSimple Dynamic String пјүжқҘеӯҳеӮЁзҡ„гҖӮSDS зұ»дјјдәҺ Java дёӯзҡ„ ArrayList пјҢеҸҜд»ҘйҖҡиҝҮйў„еҲҶй…ҚеҶ—дҪҷз©әй—ҙзҡ„ж–№ејҸжқҘеҮҸе°‘еҶ…еӯҳзҡ„йў‘з№ҒеҲҶй…ҚгҖӮ
иҝҷжҳҜжңҖз®ҖеҚ•зҡ„зұ»еһӢпјҢе°ұжҳҜжҷ®йҖҡзҡ„ set е’Ң getпјҢеҒҡз®ҖеҚ•зҡ„ KV зј“еӯҳгҖӮ
дҪҶжҳҜзңҹе®һзҡ„ејҖеҸ‘зҺҜеўғдёӯпјҢеҫҲеӨҡд»”еҸҜиғҪдјҡжҠҠеҫҲеӨҡжҜ”иҫғеӨҚжқӮзҡ„з»“жһ„д№ҹз»ҹдёҖиҪ¬жҲҗString еҺ»еӯҳеӮЁдҪҝз”ЁпјҢжҜ”еҰӮжңүзҡ„д»”д»–е°ұе–ңж¬ўжҠҠеҜ№иұЎжҲ–иҖ…List иҪ¬жҚўдёәJSONString иҝӣиЎҢеӯҳеӮЁпјҢжӢҝеҮәжқҘеҶҚеҸҚеәҸеҲ—иҜқе•Ҙзҡ„гҖӮ
жҲ‘еңЁиҝҷйҮҢе°ұдёҚи®Ёи®әиҝҷж ·еҒҡзҡ„еҜ№й”ҷдәҶпјҢдҪҶжҳҜжҲ‘иҝҳжҳҜеёҢжңӣеӨ§е®¶иғҪеңЁжңҖеҗҲйҖӮзҡ„еңәжҷҜдҪҝз”ЁжңҖеҗҲйҖӮзҡ„ж•°жҚ®з»“жһ„пјҢеҜ№иұЎжүҫдёҚеҲ°жңҖеҗҲйҖӮзҡ„дҪҶжҳҜзұ»еһӢеҸҜд»ҘйҖүжңҖеҗҲйҖӮзҡ„еҳӣпјҢд№ӢеҗҺеҲ«дәәжҺҘжүӢдҪ зҡ„д»Јз ҒдёҖзңӢиҝҷд№Ҳ规иҢғ пјҢиҜ¶иҝҷе°ҸдјҷеӯҗжңүзӮ№дёңиҘҝ е‘ҖпјҢзңӢеҲ°дҪ е•ҘйғҪжҳҜз”Ёзҡ„String пјҢеһғеңҫпјҒ
еҘҪдәҶиҝҷдәӣйғҪжҳҜйўҳеӨ–иҜқдәҶпјҢйҒ“зҗҶиҝҳжҳҜеёҢжңӣеӨ§е®¶и®°еңЁеҝғйҮҢпјҢд№ жғҜжҲҗиҮӘ然еҳӣпјҢе°Ҹд№ жғҜжҲҗе°ұдҪ гҖӮ
String зҡ„е®һйҷ…еә”з”ЁеңәжҷҜжҜ”иҫғе№ҝжіӣзҡ„жңүпјҡ
зј“еӯҳеҠҹиғҪпјҡString еӯ—з¬ҰдёІжҳҜжңҖеёёз”Ёзҡ„ж•°жҚ®зұ»еһӢпјҢдёҚд»…д»…жҳҜRedis пјҢеҗ„дёӘиҜӯиЁҖйғҪжҳҜжңҖеҹәжң¬зұ»еһӢпјҢеӣ жӯӨпјҢеҲ©з”ЁRedis дҪңдёәзј“еӯҳпјҢй…ҚеҗҲе…¶е®ғж•°жҚ®еә“дҪңдёәеӯҳеӮЁеұӮпјҢеҲ©з”ЁRedis ж”ҜжҢҒй«ҳ并еҸ‘зҡ„зү№зӮ№пјҢеҸҜд»ҘеӨ§еӨ§еҠ еҝ«зі»з»ҹзҡ„иҜ»еҶҷйҖҹеәҰгҖҒд»ҘеҸҠйҷҚдҪҺеҗҺз«Ҝж•°жҚ®еә“зҡ„еҺӢеҠӣгҖӮ
и®Ўж•°еҷЁпјҡ и®ёеӨҡзі»з»ҹйғҪдјҡдҪҝз”ЁRedis дҪңдёәзі»з»ҹзҡ„е®һж—¶и®Ўж•°еҷЁпјҢеҸҜд»Ҙеҝ«йҖҹе®һзҺ°и®Ўж•°е’ҢжҹҘиҜўзҡ„еҠҹиғҪгҖӮиҖҢдё”жңҖз»Ҳзҡ„ж•°жҚ®з»“жһңеҸҜд»ҘжҢүз…§зү№е®ҡзҡ„ж—¶й—ҙиҗҪең°еҲ°ж•°жҚ®еә“жҲ–иҖ…е…¶е®ғеӯҳеӮЁд»ӢиҙЁеҪ“дёӯиҝӣиЎҢж°ёд№…дҝқеӯҳгҖӮ
е…ұдә«з”ЁжҲ·Sessionпјҡ з”ЁжҲ·йҮҚж–°еҲ·ж–°дёҖж¬Ўз•ҢйқўпјҢеҸҜиғҪйңҖиҰҒи®ҝй—®дёҖдёӢж•°жҚ®иҝӣиЎҢйҮҚж–°зҷ»еҪ•пјҢжҲ–иҖ…и®ҝй—®йЎөйқўзј“еӯҳCookie пјҢдҪҶжҳҜеҸҜд»ҘеҲ©з”ЁRedis е°Ҷз”ЁжҲ·зҡ„Session йӣҶдёӯз®ЎзҗҶпјҢеңЁиҝҷз§ҚжЁЎејҸеҸӘйңҖиҰҒдҝқиҜҒRedis зҡ„й«ҳеҸҜз”ЁпјҢжҜҸж¬Ўз”ЁжҲ·Session зҡ„жӣҙж–°е’ҢиҺ·еҸ–йғҪеҸҜд»Ҙеҝ«йҖҹе®ҢжҲҗгҖӮеӨ§еӨ§жҸҗй«ҳж•ҲзҺҮгҖӮ
Hashпјҡ
иҝҷдёӘжҳҜзұ»дјј Map зҡ„дёҖз§Қз»“жһ„пјҢиҝҷдёӘдёҖиҲ¬е°ұжҳҜеҸҜд»Ҙе°Ҷз»“жһ„еҢ–зҡ„ж•°жҚ®пјҢжҜ”еҰӮдёҖдёӘеҜ№иұЎпјҲеүҚжҸҗжҳҜиҝҷдёӘеҜ№иұЎжІЎеөҢеҘ—е…¶д»–зҡ„еҜ№иұЎ пјүз»ҷзј“еӯҳеңЁ Redis йҮҢпјҢ然еҗҺжҜҸж¬ЎиҜ»еҶҷзј“еӯҳзҡ„ж—¶еҖҷпјҢеҸҜд»Ҙе°ұж“ҚдҪң Hash йҮҢзҡ„жҹҗдёӘеӯ—ж®ө гҖӮ
дҪҶжҳҜиҝҷдёӘзҡ„еңәжҷҜе…¶е®һиҝҳжҳҜеӨҡе°‘еҚ•дёҖдәҶдёҖдәӣпјҢеӣ дёәзҺ°еңЁеҫҲеӨҡеҜ№иұЎйғҪжҳҜжҜ”иҫғеӨҚжқӮзҡ„пјҢжҜ”еҰӮдҪ зҡ„е•Ҷе“ҒеҜ№иұЎеҸҜиғҪйҮҢйқўе°ұеҢ…еҗ«дәҶеҫҲеӨҡеұһжҖ§пјҢе…¶дёӯд№ҹжңүеҜ№иұЎгҖӮжҲ‘иҮӘе·ұдҪҝз”Ёзҡ„еңәжҷҜз”Ёеҫ—дёҚжҳҜйӮЈд№ҲеӨҡгҖӮ
Listпјҡ
List жҳҜжңүеәҸеҲ—иЎЁпјҢиҝҷдёӘиҝҳжҳҜеҸҜд»ҘзҺ©е„ҝеҮәеҫҲеӨҡиҠұж ·зҡ„гҖӮ
жҜ”еҰӮеҸҜд»ҘйҖҡиҝҮ List еӯҳеӮЁдёҖдәӣеҲ—иЎЁеһӢзҡ„ж•°жҚ®з»“жһ„пјҢзұ»дјјзІүдёқеҲ—иЎЁгҖҒж–Үз« зҡ„иҜ„и®әеҲ—иЎЁд№Ӣзұ»зҡ„дёңиҘҝгҖӮ
жҜ”еҰӮеҸҜд»ҘйҖҡиҝҮ lrange е‘Ҫд»ӨпјҢиҜ»еҸ–жҹҗдёӘй—ӯеҢәй—ҙеҶ…зҡ„е…ғзҙ пјҢеҸҜд»ҘеҹәдәҺ List е®һзҺ°еҲҶйЎөжҹҘиҜўпјҢиҝҷдёӘжҳҜеҫҲжЈ’зҡ„дёҖдёӘеҠҹиғҪпјҢеҹәдәҺ Redis е®һзҺ°з®ҖеҚ•зҡ„й«ҳжҖ§иғҪеҲҶйЎөпјҢеҸҜд»ҘеҒҡзұ»дјјеҫ®еҚҡйӮЈз§ҚдёӢжӢүдёҚж–ӯеҲҶйЎөзҡ„дёңиҘҝпјҢжҖ§иғҪй«ҳпјҢе°ұдёҖйЎөдёҖйЎөиө°гҖӮ
жҜ”еҰӮеҸҜд»ҘжҗһдёӘз®ҖеҚ•зҡ„ж¶ҲжҒҜйҳҹеҲ—пјҢд»Һ List еӨҙжҖјиҝӣеҺ»пјҢд»Һ List еұҒиӮЎйӮЈйҮҢеј„еҮәжқҘгҖӮ
List жң¬иә«е°ұжҳҜжҲ‘们еңЁејҖеҸ‘иҝҮзЁӢдёӯжҜ”иҫғеёёз”Ёзҡ„ж•°жҚ®з»“жһ„дәҶпјҢзғӯзӮ№ж•°жҚ®жӣҙдёҚз”ЁиҜҙдәҶгҖӮ
ж¶ҲжҒҜйҳҹеҲ—пјҡRedis зҡ„й“ҫиЎЁз»“жһ„пјҢеҸҜд»ҘиҪ»жқҫе®һзҺ°йҳ»еЎһйҳҹеҲ—пјҢеҸҜд»ҘдҪҝз”Ёе·ҰиҝӣеҸіеҮәзҡ„е‘Ҫд»Өз»„жҲҗжқҘе®ҢжҲҗйҳҹеҲ—зҡ„и®ҫи®ЎгҖӮжҜ”еҰӮпјҡж•°жҚ®зҡ„з”ҹдә§иҖ…еҸҜд»ҘйҖҡиҝҮLpush е‘Ҫд»Өд»Һе·Ұиҫ№жҸ’е…Ҙж•°жҚ®пјҢеӨҡдёӘж•°жҚ®ж¶Ҳиҙ№иҖ…пјҢеҸҜд»ҘдҪҝз”ЁBRpop е‘Ҫд»Өйҳ»еЎһзҡ„вҖңжҠўвҖқеҲ—иЎЁе°ҫйғЁзҡ„ж•°жҚ®гҖӮ
ж–Үз« еҲ—иЎЁжҲ–иҖ…ж•°жҚ®еҲҶйЎөеұ•зӨәзҡ„еә”з”ЁгҖӮ
жҜ”еҰӮпјҢжҲ‘们常用зҡ„еҚҡе®ўзҪ‘з«ҷзҡ„ж–Үз« еҲ—иЎЁпјҢеҪ“з”ЁжҲ·йҮҸи¶ҠжқҘи¶ҠеӨҡж—¶пјҢиҖҢдё”жҜҸдёҖдёӘз”ЁжҲ·йғҪжңүиҮӘе·ұзҡ„ж–Үз« еҲ—иЎЁпјҢиҖҢдё”еҪ“ж–Үз« еӨҡж—¶пјҢйғҪйңҖиҰҒеҲҶйЎөеұ•зӨәпјҢиҝҷж—¶еҸҜд»ҘиҖғиҷ‘дҪҝз”ЁRedis зҡ„еҲ—иЎЁпјҢеҲ—иЎЁдёҚдҪҶжңүеәҸеҗҢж—¶иҝҳж”ҜжҢҒжҢүз…§иҢғеӣҙеҶ…иҺ·еҸ–е…ғзҙ пјҢеҸҜд»Ҙе®ҢзҫҺи§ЈеҶіеҲҶйЎөжҹҘиҜўеҠҹиғҪгҖӮеӨ§еӨ§жҸҗй«ҳжҹҘиҜўж•ҲзҺҮгҖӮ
Setпјҡ
Set жҳҜж— еәҸйӣҶеҗҲпјҢдјҡиҮӘеҠЁеҺ»йҮҚзҡ„йӮЈз§ҚгҖӮ
зӣҙжҺҘеҹәдәҺ Set е°Ҷзі»з»ҹйҮҢйңҖиҰҒеҺ»йҮҚзҡ„ж•°жҚ®жү”иҝӣеҺ»пјҢиҮӘеҠЁе°ұз»ҷеҺ»йҮҚдәҶпјҢеҰӮжһңдҪ йңҖиҰҒеҜ№дёҖдәӣж•°жҚ®иҝӣиЎҢеҝ«йҖҹзҡ„е…ЁеұҖеҺ»йҮҚпјҢдҪ еҪ“然д№ҹеҸҜд»ҘеҹәдәҺ JVM еҶ…еӯҳйҮҢзҡ„ HashSet иҝӣиЎҢеҺ»йҮҚпјҢдҪҶжҳҜеҰӮжһңдҪ зҡ„жҹҗдёӘзі»з»ҹйғЁзҪІеңЁеӨҡеҸ°жңәеҷЁдёҠе‘ўпјҹеҫ—еҹәдәҺRedis иҝӣиЎҢе…ЁеұҖзҡ„ Set еҺ»йҮҚгҖӮ
еҸҜд»ҘеҹәдәҺ Set зҺ©е„ҝдәӨйӣҶгҖҒ并йӣҶгҖҒе·®йӣҶзҡ„ж“ҚдҪңпјҢжҜ”еҰӮдәӨйӣҶеҗ§пјҢжҲ‘们еҸҜд»ҘжҠҠдёӨдёӘдәәзҡ„еҘҪеҸӢеҲ—иЎЁж•ҙдёҖдёӘдәӨйӣҶпјҢзңӢзңӢдҝ©дәәзҡ„е…ұеҗҢеҘҪеҸӢжҳҜи°ҒпјҹеҜ№еҗ§гҖӮ
еҸҚжӯЈиҝҷдәӣеңәжҷҜжҜ”иҫғеӨҡпјҢеӣ дёәеҜ№жҜ”еҫҲеҝ«пјҢж“ҚдҪңд№ҹз®ҖеҚ•пјҢдёӨдёӘжҹҘиҜўдёҖдёӘSet жҗһе®ҡгҖӮ
Sorted Setпјҡ
Sorted set жҳҜжҺ’еәҸзҡ„ Set пјҢеҺ»йҮҚдҪҶеҸҜд»ҘжҺ’еәҸпјҢеҶҷиҝӣеҺ»зҡ„ж—¶еҖҷз»ҷдёҖдёӘеҲҶж•°пјҢиҮӘеҠЁж №жҚ®еҲҶж•°жҺ’еәҸгҖӮ
жңүеәҸйӣҶеҗҲзҡ„дҪҝз”ЁеңәжҷҜдёҺйӣҶеҗҲзұ»дјјпјҢдҪҶжҳҜsetйӣҶеҗҲдёҚжҳҜиҮӘеҠЁжңүеәҸзҡ„пјҢиҖҢSorted set еҸҜд»ҘеҲ©з”ЁеҲҶж•°иҝӣиЎҢжҲҗе‘ҳй—ҙзҡ„жҺ’еәҸпјҢиҖҢдё”жҳҜжҸ’е…Ҙж—¶е°ұжҺ’еәҸеҘҪгҖӮжүҖд»ҘеҪ“дҪ йңҖиҰҒдёҖдёӘжңүеәҸдё”дёҚйҮҚеӨҚзҡ„йӣҶеҗҲеҲ—иЎЁж—¶пјҢе°ұеҸҜд»ҘйҖүжӢ©Sorted set ж•°жҚ®з»“жһ„дҪңдёәйҖүжӢ©ж–№жЎҲгҖӮ
жҺ’иЎҢжҰңпјҡжңүеәҸйӣҶеҗҲз»Ҹе…ёдҪҝз”ЁеңәжҷҜгҖӮдҫӢеҰӮи§Ҷйў‘зҪ‘з«ҷйңҖиҰҒеҜ№з”ЁжҲ·дёҠдј зҡ„и§Ҷйў‘еҒҡжҺ’иЎҢжҰңпјҢжҰңеҚ•з»ҙжҠӨеҸҜиғҪжҳҜеӨҡж–№йқўпјҡжҢүз…§ж—¶й—ҙгҖҒжҢүз…§ж’ӯж”ҫйҮҸгҖҒжҢүз…§иҺ·еҫ—зҡ„иөһж•°зӯүгҖӮ
з”ЁSorted Sets жқҘеҒҡеёҰжқғйҮҚзҡ„йҳҹеҲ—пјҢжҜ”еҰӮжҷ®йҖҡж¶ҲжҒҜзҡ„scoreдёә1пјҢйҮҚиҰҒж¶ҲжҒҜзҡ„scoreдёә2пјҢ然еҗҺе·ҘдҪңзәҝзЁӢеҸҜд»ҘйҖүжӢ©жҢүscoreзҡ„еҖ’еәҸжқҘиҺ·еҸ–е·ҘдҪңд»»еҠЎгҖӮи®©йҮҚиҰҒзҡ„д»»еҠЎдјҳе…Ҳжү§иЎҢгҖӮ
еҫ®еҚҡзғӯжҗңжҰңпјҢе°ұжҳҜжңүдёӘеҗҺйқўзҡ„зғӯеәҰеҖјпјҢеүҚйқўе°ұжҳҜеҗҚз§°
й«ҳзә§з”Ёжі•пјҡ
Bitmap :
дҪҚеӣҫжҳҜж”ҜжҢҒжҢү bit дҪҚжқҘеӯҳеӮЁдҝЎжҒҜпјҢеҸҜд»Ҙз”ЁжқҘе®һзҺ° еёғйҡҶиҝҮж»ӨеҷЁпјҲBloomFilterпјү пјӣ
HyperLogLog:
дҫӣдёҚзІҫзЎ®зҡ„еҺ»йҮҚи®Ўж•°еҠҹиғҪпјҢжҜ”иҫғйҖӮеҗҲз”ЁжқҘеҒҡеӨ§и§„жЁЎж•°жҚ®зҡ„еҺ»йҮҚз»ҹи®ЎпјҢдҫӢеҰӮз»ҹи®Ў UVпјӣ
Geospatial:
еҸҜд»Ҙз”ЁжқҘдҝқеӯҳең°зҗҶдҪҚзҪ®пјҢ并дҪңдҪҚзҪ®и·қзҰ»и®Ўз®—жҲ–иҖ…ж №жҚ®еҚҠеҫ„и®Ўз®—дҪҚзҪ®зӯүгҖӮжңүжІЎжңүжғіиҝҮз”ЁRedisжқҘе®һзҺ°йҷ„иҝ‘зҡ„дәәпјҹжҲ–иҖ…и®Ўз®—жңҖдјҳең°еӣҫи·Ҝеҫ„пјҹ
иҝҷдёүдёӘе…¶е®һд№ҹеҸҜд»Ҙз®—дҪңдёҖз§Қж•°жҚ®з»“жһ„пјҢдёҚзҹҘйҒ“иҝҳжңүеӨҡе°‘жңӢеҸӢи®°еҫ—пјҢжҲ‘еңЁжўҰејҖе§Ӣзҡ„ең°ж–№пјҢRedisеҹәзЎҖдёӯжҸҗеҲ°иҝҮпјҢдҪ еҰӮжһңеҸӘзҹҘйҒ“дә”з§ҚеҹәзЎҖзұ»еһӢйӮЈеҸӘиғҪжӢҝ60еҲҶпјҢеҰӮжһңдҪ иғҪи®ІеҮәй«ҳзә§з”Ёжі•пјҢйӮЈе°ұи§үеҫ—дҪ жңүзӮ№дёңиҘҝ гҖӮ
pub/subпјҡ
еҠҹиғҪжҳҜи®ўйҳ…еҸ‘еёғеҠҹиғҪпјҢеҸҜд»Ҙз”ЁдҪңз®ҖеҚ•зҡ„ж¶ҲжҒҜйҳҹеҲ—гҖӮ
Pipelineпјҡ
еҸҜд»Ҙжү№йҮҸжү§иЎҢдёҖз»„жҢҮд»ӨпјҢдёҖж¬ЎжҖ§иҝ”еӣһе…ЁйғЁз»“жһңпјҢеҸҜд»ҘеҮҸе°‘йў‘з№Ғзҡ„иҜ·жұӮеә”зӯ”гҖӮ
Luaпјҡ
Redis ж”ҜжҢҒжҸҗдәӨ Lua и„ҡжң¬жқҘжү§иЎҢдёҖзі»еҲ—зҡ„еҠҹиғҪгҖӮ
жҲ‘еңЁеүҚз”өе•ҶиҖҒдёң家зҡ„ж—¶еҖҷпјҢз§’жқҖеңәжҷҜз»ҸеёёдҪҝз”ЁиҝҷдёӘдёңиҘҝпјҢи®ІйҒ“зҗҶжңүзӮ№йҰҷпјҢеҲ©з”Ёд»–зҡ„еҺҹеӯҗжҖ§гҖӮ
иҜқиҜҙдҪ 们жғізңӢз§’жқҖзҡ„и®ҫи®Ўд№ҲпјҹжҲ‘и®°еҫ—жҲ‘йқўиҜ•еҘҪеғҸжҜҸж¬ЎйғҪй—®е•ҠпјҢжғізңӢзҡ„зӣҙжҺҘзӮ№иөһ еҗҺиҜ„и®әз§’жқҖеҗ§гҖӮ
дәӢеҠЎпјҡ
жңҖеҗҺдёҖдёӘеҠҹиғҪжҳҜдәӢеҠЎпјҢдҪҶ Redis жҸҗдҫӣзҡ„дёҚжҳҜдёҘж јзҡ„дәӢеҠЎпјҢRedis еҸӘдҝқиҜҒдёІиЎҢжү§иЎҢе‘Ҫд»ӨпјҢ并且иғҪдҝқиҜҒе…ЁйғЁжү§иЎҢпјҢдҪҶжҳҜжү§иЎҢе‘Ҫд»ӨеӨұиҙҘ时并дёҚдјҡеӣһж»ҡпјҢиҖҢжҳҜдјҡ继з»ӯжү§иЎҢдёӢеҺ»гҖӮ
жҢҒд№…еҢ–
Redis жҸҗдҫӣдәҶ RDB е’Ң AOF дёӨз§ҚжҢҒд№…еҢ–ж–№ејҸпјҢRDB жҳҜжҠҠеҶ…еӯҳдёӯзҡ„ж•°жҚ®йӣҶд»Ҙеҝ«з…§еҪўејҸеҶҷе…ҘзЈҒзӣҳпјҢе®һйҷ…ж“ҚдҪңжҳҜйҖҡиҝҮ fork еӯҗиҝӣзЁӢжү§иЎҢпјҢйҮҮз”ЁдәҢиҝӣеҲ¶еҺӢзј©еӯҳеӮЁпјӣAOF жҳҜд»Ҙж–Үжң¬ж—Ҙеҝ—зҡ„еҪўејҸи®°еҪ• Redis еӨ„зҗҶзҡ„жҜҸдёҖдёӘеҶҷе…ҘжҲ–еҲ йҷӨж“ҚдҪңгҖӮ
RDB жҠҠж•ҙдёӘ Redis зҡ„ж•°жҚ®дҝқеӯҳеңЁеҚ•дёҖж–Ү件дёӯпјҢжҜ”иҫғйҖӮеҗҲз”ЁжқҘеҒҡзҒҫеӨҮпјҢдҪҶзјәзӮ№жҳҜеҝ«з…§дҝқеӯҳе®ҢжҲҗд№ӢеүҚеҰӮжһңе®•жңәпјҢиҝҷж®өж—¶й—ҙзҡ„ж•°жҚ®е°ҶдјҡдёўеӨұпјҢеҸҰеӨ–дҝқеӯҳеҝ«з…§ж—¶еҸҜиғҪеҜјиҮҙжңҚеҠЎзҹӯж—¶й—ҙдёҚеҸҜз”ЁгҖӮ
AOF еҜ№ж—Ҙеҝ—ж–Ү件зҡ„еҶҷе…Ҙж“ҚдҪңдҪҝз”Ёзҡ„иҝҪеҠ жЁЎејҸпјҢжңүзҒөжҙ»зҡ„еҗҢжӯҘзӯ–з•ҘпјҢж”ҜжҢҒжҜҸз§’еҗҢжӯҘгҖҒжҜҸж¬Ўдҝ®ж”№еҗҢжӯҘе’ҢдёҚеҗҢжӯҘпјҢзјәзӮ№е°ұжҳҜзӣёеҗҢ规模зҡ„ж•°жҚ®йӣҶпјҢAOF иҰҒеӨ§дәҺ RDBпјҢAOF еңЁиҝҗиЎҢж•ҲзҺҮдёҠеҫҖеҫҖдјҡж…ўдәҺ RDBгҖӮ
з»ҶиҠӮзҡ„зӮ№еӨ§е®¶еҺ»й«ҳеҸҜз”Ёиҝҷз« зңӢпјҢзү№еҲ«жҳҜдёӨиҖ…зҡ„дјҳзјәзӮ№пјҢд»ҘеҸҠжҖҺд№ҲжҠүжӢ©гҖӮ
гҖҠеҗҠжү“йқўиҜ•е®ҳгҖӢзі»еҲ—-Redisе“Ёе…өгҖҒжҢҒд№…еҢ–гҖҒдё»д»ҺгҖҒжүӢж’•LRU
й«ҳеҸҜз”Ё
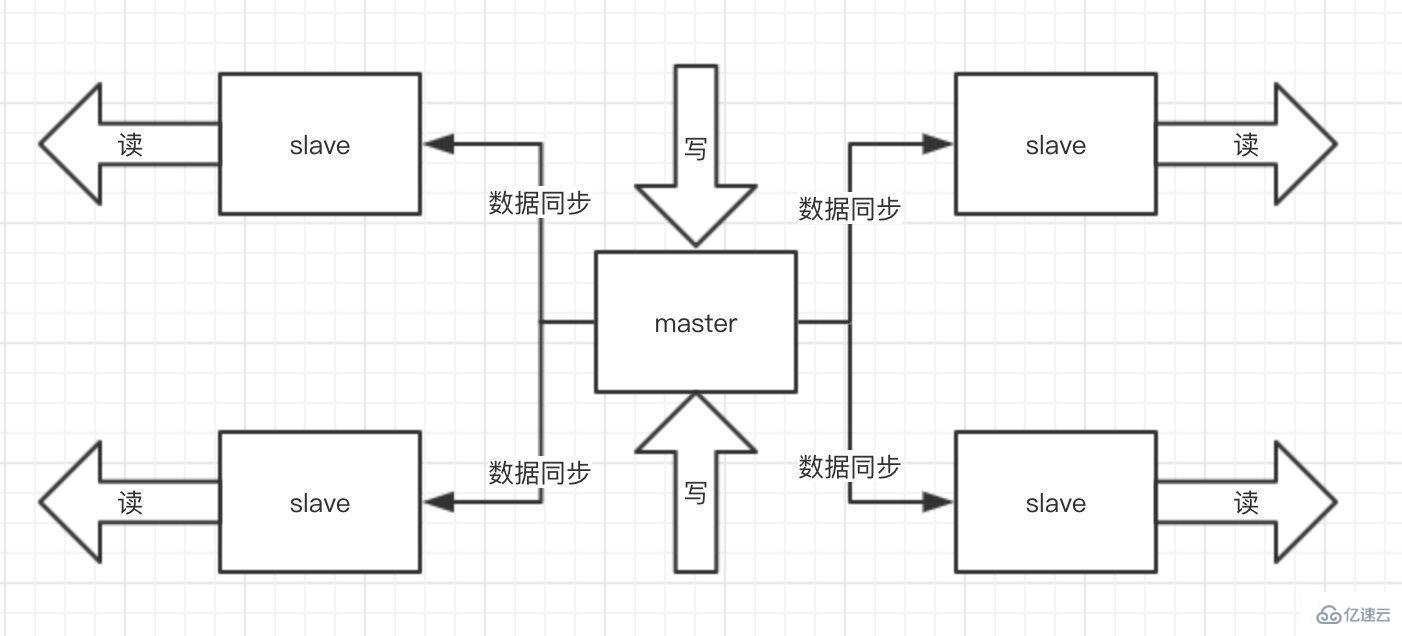
жқҘзңӢ Redis зҡ„й«ҳеҸҜз”ЁгҖӮRedis ж”ҜжҢҒдё»д»ҺеҗҢжӯҘпјҢжҸҗдҫӣ Cluster йӣҶзҫӨйғЁзҪІжЁЎејҸпјҢйҖҡиҝҮ Sentine lе“Ёе…өжқҘзӣ‘жҺ§ Redis дё»жңҚеҠЎеҷЁ зҡ„зҠ¶жҖҒгҖӮеҪ“дё»жҢӮжҺүж—¶пјҢеңЁд»ҺиҠӮзӮ№дёӯж №жҚ®дёҖе®ҡзӯ–з•ҘйҖүеҮәж–°дё»пјҢ并и°ғж•ҙе…¶д»–д»Һ slaveof еҲ°ж–°дё»гҖӮ
йҖүдё»зҡ„зӯ–з•Ҙз®ҖеҚ•жқҘиҜҙжңүдёүдёӘпјҡ
slave зҡ„ priority и®ҫзҪ®зҡ„и¶ҠдҪҺпјҢдјҳе…Ҳзә§и¶Ҡй«ҳпјӣ
еҗҢзӯүжғ…еҶөдёӢпјҢslave еӨҚеҲ¶зҡ„ж•°жҚ®и¶ҠеӨҡдјҳе…Ҳзә§и¶Ҡй«ҳпјӣ
зӣёеҗҢзҡ„жқЎд»¶дёӢ runid и¶Ҡе°Ҹи¶Ҡе®№жҳ“иў«йҖүдёӯгҖӮ
еңЁ Redis йӣҶзҫӨдёӯпјҢsentinel д№ҹдјҡиҝӣиЎҢеӨҡе®һдҫӢйғЁзҪІпјҢsentinel д№Ӣй—ҙйҖҡиҝҮ Raft еҚҸи®®жқҘдҝқиҜҒиҮӘиә«зҡ„й«ҳеҸҜз”ЁгҖӮ
Redis Cluster дҪҝз”ЁеҲҶзүҮжңәеҲ¶пјҢеңЁеҶ…йғЁеҲҶдёә 16384 дёӘ slot жҸ’ж§ҪпјҢеҲҶеёғеңЁжүҖжңү master иҠӮзӮ№дёҠпјҢжҜҸдёӘ master иҠӮзӮ№иҙҹиҙЈдёҖйғЁеҲҶ slotгҖӮж•°жҚ®ж“ҚдҪңж—¶жҢү key еҒҡ CRC16 жқҘи®Ўз®—еңЁе“ӘдёӘ slotпјҢз”ұе“ӘдёӘ master иҝӣиЎҢеӨ„зҗҶгҖӮж•°жҚ®зҡ„еҶ—дҪҷжҳҜйҖҡиҝҮ slave иҠӮзӮ№жқҘдҝқйҡңгҖӮ
е“Ёе…ө
е“Ёе…өеҝ…йЎ»з”ЁдёүдёӘе®һдҫӢеҺ»дҝқиҜҒиҮӘе·ұзҡ„еҒҘеЈ®жҖ§зҡ„пјҢе“Ёе…ө+дё»д»Һ并дёҚиғҪдҝқиҜҒж•°жҚ®дёҚдёўеӨұ пјҢдҪҶжҳҜеҸҜд»ҘдҝқиҜҒйӣҶзҫӨзҡ„й«ҳеҸҜз”Ё гҖӮ
дёәе•Ҙеҝ…йЎ»иҰҒдёүдёӘе®һдҫӢе‘ўпјҹжҲ‘们е…ҲзңӢзңӢдёӨдёӘе“Ёе…өдјҡе’Ӣж ·гҖӮ
masterе®•жңәдәҶ s1е’Ңs2дёӨдёӘе“Ёе…өеҸӘиҰҒжңүдёҖдёӘи®ӨдёәдҪ е®•жңәдәҶе°ұеҲҮжҚўдәҶпјҢ并且дјҡйҖүдёҫеҮәдёҖдёӘе“Ёе…өеҺ»жү§иЎҢж•…йҡңпјҢдҪҶжҳҜиҝҷдёӘж—¶еҖҷд№ҹйңҖиҰҒеӨ§еӨҡж•°е“Ёе…өйғҪжҳҜиҝҗиЎҢзҡ„гҖӮ
йӮЈиҝҷж ·жңүе•Ҙй—®йўҳе‘ўпјҹM1е®•жңәдәҶпјҢS1жІЎжҢӮйӮЈе…¶е®һжҳҜOKзҡ„пјҢдҪҶжҳҜж•ҙдёӘжңәеҷЁйғҪжҢӮдәҶе‘ўпјҹе“Ёе…өе°ұеҸӘеү©дёӢS2дёӘиЈёеұҢдәҶпјҢжІЎжңүе“Ёе…өеҺ»е…Ғи®ёж•…йҡңиҪ¬з§»дәҶпјҢиҷҪ然еҸҰеӨ–дёҖдёӘжңәеҷЁдёҠиҝҳжңүR1пјҢдҪҶжҳҜж•…йҡңиҪ¬з§»е°ұжҳҜдёҚжү§иЎҢгҖӮ
з»Ҹе…ёзҡ„е“Ёе…өйӣҶзҫӨжҳҜиҝҷж ·зҡ„пјҡ
M1жүҖеңЁзҡ„жңәеҷЁжҢӮдәҶпјҢе“Ёе…өиҝҳжңүдёӨдёӘпјҢдёӨдёӘдәәдёҖзңӢд»–дёҚжҳҜжҢӮдәҶеҳӣпјҢйӮЈжҲ‘们е°ұйҖүдёҫдёҖдёӘеҮәжқҘжү§иЎҢж•…йҡңиҪ¬з§»дёҚе°ұеҘҪдәҶгҖӮ
жҡ–з”·жҲ‘пјҢе°Ҹзҡ„жҖ»з»“дёӢе“Ёе…ө组件зҡ„дё»иҰҒеҠҹиғҪпјҡ
йӣҶзҫӨзӣ‘жҺ§пјҡиҙҹиҙЈзӣ‘жҺ§ Redis master е’Ң slave иҝӣзЁӢжҳҜеҗҰжӯЈеёёе·ҘдҪңгҖӮ
ж¶ҲжҒҜйҖҡзҹҘпјҡеҰӮжһңжҹҗдёӘ Redis е®һдҫӢжңүж•…йҡңпјҢйӮЈд№Ҳе“Ёе…өиҙҹиҙЈеҸ‘йҖҒж¶ҲжҒҜдҪңдёәжҠҘиӯҰйҖҡзҹҘз»ҷз®ЎзҗҶе‘ҳгҖӮ
ж•…йҡңиҪ¬з§»пјҡеҰӮжһң master node жҢӮжҺүдәҶпјҢдјҡиҮӘеҠЁиҪ¬з§»еҲ° slave node дёҠгҖӮ
й…ҚзҪ®дёӯеҝғпјҡеҰӮжһңж•…йҡңиҪ¬з§»еҸ‘з”ҹдәҶпјҢйҖҡзҹҘ client е®ўжҲ·з«Ҝж–°зҡ„ master ең°еқҖгҖӮ
дё»д»Һ
жҸҗеҲ°иҝҷдёӘпјҢе°ұи·ҹжҲ‘еүҚйқўжҸҗеҲ°зҡ„ж•°жҚ®жҢҒд№…еҢ–зҡ„RDB е’ҢAOF жңүзқҖжҜ”еҜҶеҲҮзҡ„е…ізі»дәҶгҖӮ
жҲ‘е…ҲиҜҙдёӢдёәе•ҘиҰҒз”Ёдё»д»Һиҝҷж ·зҡ„жһ¶жһ„жЁЎејҸпјҢеүҚйқўжҸҗеҲ°дәҶеҚ•жңәQPS жҳҜжңүдёҠйҷҗзҡ„пјҢиҖҢдё”Redis зҡ„зү№жҖ§е°ұжҳҜеҝ…йЎ»ж”Ҝж’‘иҜ»й«ҳ并еҸ‘зҡ„пјҢйӮЈдҪ дёҖеҸ°жңәеҷЁеҸҲиҜ»еҸҲеҶҷпјҢиҝҷи°ҒйЎ¶еҫ—дҪҸе•Ҡ пјҢдёҚеҪ“дәәе•ҠпјҒдҪҶжҳҜдҪ и®©иҝҷдёӘmasterжңәеҷЁеҺ»еҶҷпјҢж•°жҚ®еҗҢжӯҘз»ҷеҲ«зҡ„slaveжңәеҷЁпјҢ他们йғҪжӢҝеҺ»иҜ»пјҢеҲҶеҸ‘жҺүеӨ§йҮҸзҡ„иҜ·жұӮйӮЈжҳҜдёҚжҳҜеҘҪеҫҲеӨҡпјҢиҖҢдё”жү©е®№зҡ„ж—¶еҖҷиҝҳеҸҜд»ҘиҪ»жқҫе®һзҺ°ж°ҙе№іжү©е®№гҖӮ
дҪ еҗҜеҠЁдёҖеҸ°slave зҡ„ж—¶еҖҷпјҢд»–дјҡеҸ‘йҖҒдёҖдёӘpsync е‘Ҫд»Өз»ҷmaster пјҢеҰӮжһңжҳҜиҝҷдёӘslave第дёҖж¬ЎиҝһжҺҘеҲ°masterпјҢд»–дјҡи§ҰеҸ‘дёҖдёӘе…ЁйҮҸеӨҚеҲ¶гҖӮmasterе°ұдјҡеҗҜеҠЁдёҖдёӘзәҝзЁӢпјҢз”ҹжҲҗRDB еҝ«з…§пјҢиҝҳдјҡжҠҠж–°зҡ„еҶҷиҜ·жұӮйғҪзј“еӯҳеңЁеҶ…еӯҳдёӯпјҢRDB ж–Ү件з”ҹжҲҗеҗҺпјҢmasterдјҡе°ҶиҝҷдёӘRDB еҸ‘йҖҒз»ҷslaveзҡ„пјҢslaveжӢҝеҲ°д№ӢеҗҺеҒҡзҡ„第дёҖ件дәӢжғ…е°ұжҳҜеҶҷиҝӣжң¬ең°зҡ„зЈҒзӣҳпјҢ然еҗҺеҠ иҪҪиҝӣеҶ…еӯҳпјҢ然еҗҺmasterдјҡжҠҠеҶ…еӯҳйҮҢйқўзј“еӯҳзҡ„йӮЈдәӣж–°е‘ҪеҗҚйғҪеҸ‘з»ҷslaveгҖӮ
жҲ‘еҸ‘еҮәжқҘд№ӢеҗҺжқҘиҮӘCSDNзҡ„зҪ‘еҸӢпјҡJian_Shen_Zer й—®дәҶдёӘй—®йўҳпјҡ
дё»д»ҺеҗҢжӯҘзҡ„ж—¶еҖҷпјҢж–°зҡ„slaverиҝӣжқҘзҡ„ж—¶еҖҷз”ЁRDB пјҢйӮЈд№ӢеҗҺзҡ„ж•°жҚ®е‘ўпјҹжңүж–°зҡ„ж•°жҚ®иҝӣе…ҘmasterжҖҺд№ҲеҗҢжӯҘеҲ°slaverе•Ҡ
ж•–дёҷзӯ”пјҡз¬ЁпјҢAOF еҳӣпјҢеўһйҮҸзҡ„е°ұеғҸMySQL Binlog дёҖж ·пјҢжҠҠж—Ҙеҝ—еўһйҮҸеҗҢжӯҘз»ҷд»ҺжңҚеҠЎе°ұеҘҪдәҶ
key еӨұж•ҲжңәеҲ¶
Redis зҡ„ key еҸҜд»Ҙи®ҫзҪ®иҝҮжңҹж—¶й—ҙпјҢиҝҮжңҹеҗҺ Redis йҮҮз”Ёдё»еҠЁе’Ңиў«еҠЁз»“еҗҲзҡ„еӨұж•ҲжңәеҲ¶пјҢдёҖдёӘжҳҜе’Ң MC дёҖж ·еңЁи®ҝй—®ж—¶и§ҰеҸ‘иў«еҠЁеҲ йҷӨпјҢеҸҰдёҖз§ҚжҳҜе®ҡжңҹзҡ„дё»еҠЁеҲ йҷӨгҖӮ
е®ҡжңҹ+жғ°жҖ§+еҶ…еӯҳж·ҳжұ°
зј“еӯҳеёёи§Ғй—®йўҳ
зј“еӯҳжӣҙж–°ж–№ејҸ
иҝҷжҳҜеҶіе®ҡеңЁдҪҝз”Ёзј“еӯҳж—¶е°ұиҜҘиҖғиҷ‘зҡ„й—®йўҳгҖӮ
зј“еӯҳзҡ„ж•°жҚ®еңЁж•°жҚ®жәҗеҸ‘з”ҹеҸҳжӣҙж—¶йңҖиҰҒеҜ№зј“еӯҳиҝӣиЎҢжӣҙж–°пјҢж•°жҚ®жәҗеҸҜиғҪжҳҜ DBпјҢд№ҹеҸҜиғҪжҳҜиҝңзЁӢжңҚеҠЎгҖӮжӣҙж–°зҡ„ж–№ејҸеҸҜд»ҘжҳҜдё»еҠЁжӣҙж–°гҖӮж•°жҚ®жәҗжҳҜ DB ж—¶пјҢеҸҜд»ҘеңЁжӣҙж–°е®Ң DB еҗҺе°ұзӣҙжҺҘжӣҙж–°зј“еӯҳгҖӮ
еҪ“ж•°жҚ®жәҗдёҚжҳҜ DB иҖҢжҳҜе…¶д»–иҝңзЁӢжңҚеҠЎпјҢеҸҜиғҪж— жі•еҸҠж—¶дё»еҠЁж„ҹзҹҘж•°жҚ®еҸҳжӣҙпјҢиҝҷз§Қжғ…еҶөдёӢдёҖиҲ¬дјҡйҖүжӢ©еҜ№зј“еӯҳж•°жҚ®и®ҫзҪ®еӨұж•ҲжңҹпјҢд№ҹе°ұжҳҜж•°жҚ®дёҚдёҖиҮҙзҡ„жңҖеӨ§е®№еҝҚж—¶й—ҙгҖӮ
иҝҷз§ҚеңәжҷҜдёӢпјҢеҸҜд»ҘйҖүжӢ©еӨұж•Ҳжӣҙж–°пјҢkey дёҚеӯҳеңЁжҲ–еӨұж•Ҳж—¶е…ҲиҜ·жұӮж•°жҚ®жәҗиҺ·еҸ–жңҖж–°ж•°жҚ®пјҢ然еҗҺеҶҚж¬Ўзј“еӯҳпјҢ并жӣҙж–°еӨұж•ҲжңҹгҖӮ
дҪҶиҝҷж ·еҒҡжңүдёӘй—®йўҳпјҢеҰӮжһңдҫқиө–зҡ„иҝңзЁӢжңҚеҠЎеңЁжӣҙж–°ж—¶еҮәзҺ°ејӮеёёпјҢеҲҷдјҡеҜјиҮҙж•°жҚ®дёҚеҸҜз”ЁгҖӮж”№иҝӣзҡ„еҠһжі•жҳҜејӮжӯҘжӣҙж–°пјҢе°ұжҳҜеҪ“еӨұж•Ҳж—¶е…ҲдёҚжё…йҷӨж•°жҚ®пјҢ继з»ӯдҪҝз”Ёж—§зҡ„ж•°жҚ®пјҢ然еҗҺз”ұејӮжӯҘзәҝзЁӢеҺ»жү§иЎҢжӣҙж–°д»»еҠЎгҖӮиҝҷж ·е°ұйҒҝе…ҚдәҶеӨұж•Ҳзһ¬й—ҙзҡ„з©әзӘ—жңҹгҖӮеҸҰеӨ–иҝҳжңүдёҖз§ҚзәҜејӮжӯҘжӣҙж–°ж–№ејҸпјҢе®ҡж—¶еҜ№ж•°жҚ®иҝӣиЎҢеҲҶжү№жӣҙж–°гҖӮе®һйҷ…дҪҝз”Ёж—¶еҸҜд»Ҙж №жҚ®дёҡеҠЎеңәжҷҜйҖүжӢ©жӣҙж–°ж–№ејҸгҖӮ
ж•°жҚ®дёҚдёҖиҮҙ
第дәҢдёӘй—®йўҳжҳҜж•°жҚ®дёҚдёҖиҮҙзҡ„й—®йўҳпјҢеҸҜд»ҘиҜҙеҸӘиҰҒдҪҝз”Ёзј“еӯҳпјҢе°ұиҰҒиҖғиҷ‘еҰӮдҪ•йқўеҜ№иҝҷдёӘй—®йўҳгҖӮзј“еӯҳдёҚдёҖиҮҙдә§з”ҹзҡ„еҺҹеӣ дёҖиҲ¬жҳҜдё»еҠЁжӣҙж–°еӨұиҙҘпјҢдҫӢеҰӮжӣҙж–° DB еҗҺпјҢжӣҙж–° Redis еӣ дёәзҪ‘з»ңеҺҹеӣ иҜ·жұӮи¶…ж—¶пјӣжҲ–иҖ…жҳҜејӮжӯҘжӣҙж–°еӨұиҙҘеҜјиҮҙгҖӮ
и§ЈеҶізҡ„еҠһжі•жҳҜпјҢеҰӮжһңжңҚеҠЎеҜ№иҖ—ж—¶дёҚжҳҜзү№еҲ«ж•Ҹж„ҹеҸҜд»ҘеўһеҠ йҮҚиҜ•пјӣеҰӮжһңжңҚеҠЎеҜ№иҖ—ж—¶ж•Ҹж„ҹеҸҜд»ҘйҖҡиҝҮејӮжӯҘиЎҘеҒҝд»»еҠЎжқҘеӨ„зҗҶеӨұиҙҘзҡ„жӣҙж–°пјҢжҲ–иҖ…зҹӯжңҹзҡ„ж•°жҚ®дёҚдёҖиҮҙдёҚдјҡеҪұе“ҚдёҡеҠЎпјҢйӮЈд№ҲеҸӘиҰҒдёӢж¬Ўжӣҙж–°ж—¶еҸҜд»ҘжҲҗеҠҹпјҢиғҪдҝқиҜҒжңҖз»ҲдёҖиҮҙжҖ§е°ұеҸҜд»ҘгҖӮ
зј“еӯҳз©ҝйҖҸ
зј“еӯҳз©ҝйҖҸ гҖӮдә§з”ҹиҝҷдёӘй—®йўҳзҡ„еҺҹеӣ еҸҜиғҪжҳҜеӨ–йғЁзҡ„жҒ¶ж„Ҹж”»еҮ»пјҢдҫӢеҰӮпјҢеҜ№з”ЁжҲ·дҝЎжҒҜиҝӣиЎҢдәҶзј“еӯҳпјҢдҪҶжҒ¶ж„Ҹж”»еҮ»иҖ…дҪҝз”ЁдёҚеӯҳеңЁзҡ„з”ЁжҲ·idйў‘з№ҒиҜ·жұӮжҺҘеҸЈпјҢеҜјиҮҙжҹҘиҜўзј“еӯҳдёҚе‘ҪдёӯпјҢ然еҗҺз©ҝйҖҸ DB жҹҘиҜўдҫқ然дёҚе‘ҪдёӯгҖӮиҝҷж—¶дјҡжңүеӨ§йҮҸиҜ·жұӮз©ҝйҖҸзј“еӯҳи®ҝй—®еҲ° DBгҖӮ
и§ЈеҶізҡ„еҠһжі•еҰӮдёӢгҖӮ
еҜ№дёҚеӯҳеңЁзҡ„з”ЁжҲ·пјҢеңЁзј“еӯҳдёӯдҝқеӯҳдёҖдёӘз©әеҜ№иұЎиҝӣиЎҢж Үи®°пјҢйҳІжӯўзӣёеҗҢ ID еҶҚж¬Ўи®ҝй—® DBгҖӮдёҚиҝҮжңүж—¶иҝҷдёӘ方法并дёҚиғҪеҫҲеҘҪи§ЈеҶій—®йўҳпјҢеҸҜиғҪеҜјиҮҙзј“еӯҳдёӯеӯҳеӮЁеӨ§йҮҸж— з”Ёж•°жҚ®гҖӮ
дҪҝз”Ё BloomFilter иҝҮж»ӨеҷЁпјҢBloomFilter зҡ„зү№зӮ№жҳҜеӯҳеңЁжҖ§жЈҖжөӢпјҢеҰӮжһң BloomFilter дёӯдёҚеӯҳеңЁпјҢйӮЈд№Ҳж•°жҚ®дёҖе®ҡдёҚеӯҳеңЁпјӣеҰӮжһң BloomFilter дёӯеӯҳеңЁпјҢе®һйҷ…ж•°жҚ®д№ҹжңүеҸҜиғҪдјҡдёҚеӯҳеңЁгҖӮйқһеёёйҖӮеҗҲи§ЈеҶіиҝҷзұ»зҡ„й—®йўҳгҖӮ
зј“еӯҳеҮ»з©ҝ
зј“еӯҳеҮ»з©ҝ пјҢе°ұжҳҜжҹҗдёӘзғӯзӮ№ж•°жҚ®еӨұж•Ҳж—¶пјҢеӨ§йҮҸй’ҲеҜ№иҝҷдёӘж•°жҚ®зҡ„иҜ·жұӮдјҡз©ҝйҖҸеҲ°ж•°жҚ®жәҗгҖӮ
и§ЈеҶіиҝҷдёӘй—®йўҳжңүеҰӮдёӢеҠһжі•гҖӮ
еҸҜд»ҘдҪҝз”Ёдә’ж–Ҙй”Ғжӣҙж–°пјҢдҝқиҜҒеҗҢдёҖдёӘиҝӣзЁӢдёӯй’ҲеҜ№еҗҢдёҖдёӘж•°жҚ®дёҚдјҡ并еҸ‘иҜ·жұӮеҲ° DBпјҢеҮҸе°Ҹ DB еҺӢеҠӣгҖӮ
дҪҝз”ЁйҡҸжңәйҖҖйҒҝж–№ејҸпјҢеӨұж•Ҳж—¶йҡҸжңә sleep дёҖдёӘеҫҲзҹӯзҡ„ж—¶й—ҙпјҢеҶҚж¬ЎжҹҘиҜўпјҢеҰӮжһңеӨұиҙҘеҶҚжү§иЎҢжӣҙж–°гҖӮ
й’ҲеҜ№еӨҡдёӘзғӯзӮ№ key еҗҢж—¶еӨұж•Ҳзҡ„й—®йўҳпјҢеҸҜд»ҘеңЁзј“еӯҳж—¶дҪҝз”Ёеӣәе®ҡж—¶й—ҙеҠ дёҠдёҖдёӘе°Ҹзҡ„йҡҸжңәж•°пјҢйҒҝе…ҚеӨ§йҮҸзғӯзӮ№ key еҗҢдёҖж—¶еҲ»еӨұж•ҲгҖӮ
зј“еӯҳйӣӘеҙ©
зј“еӯҳйӣӘеҙ© пјҢдә§з”ҹзҡ„еҺҹеӣ жҳҜзј“еӯҳжҢӮжҺүпјҢиҝҷж—¶жүҖжңүзҡ„иҜ·жұӮйғҪдјҡз©ҝйҖҸеҲ° DBгҖӮ
и§ЈеҶіж–№жі•пјҡ
е®һйҷ…еңәжҷҜдёӯпјҢиҝҷдёӨз§Қж–№жі•дјҡз»“еҗҲдҪҝз”ЁгҖӮ
иҖҒжңӢеҸӢйғҪзҹҘйҒ“дёәе•ҘжҲ‘жІЎжңүеӨ§зҜҮе№…д»Ӣз»Қ иҝҷдёӘеҮ дёӘзӮ№дәҶеҗ§пјҢжҲ‘еңЁд№ӢеүҚзҡ„ж–Үз« е®һеңЁжҳҜеҶҷеҫ—еӨӘиҜҰз»ҶдәҶпјҢеҝҚдёҚдҪҸзӮ№иөһ йӮЈз§ҚпјҢжҲ‘иҝҷйҮҢе°ұдёҚеҒҡйҮҚеӨҚжӢ·иҙқдәҶгҖӮ
гҖҠеҗҠжү“йқўиҜ•е®ҳгҖӢзі»еҲ—-RedisеҹәзЎҖ
гҖҠеҗҠжү“йқўиҜ•е®ҳгҖӢзі»еҲ—-зј“еӯҳйӣӘеҙ©гҖҒеҮ»з©ҝгҖҒз©ҝйҖҸ
гҖҠеҗҠжү“йқўиҜ•е®ҳгҖӢзі»еҲ—-Redisе“Ёе…өгҖҒжҢҒд№…еҢ–гҖҒдё»д»ҺгҖҒжүӢж’•LRU
гҖҠеҗҠжү“йқўиҜ•е®ҳгҖӢзі»еҲ—-Redisз»Ҳз« -еҮӣеҶ¬е°ҶиҮігҖҒFPX-ж–°зҺӢзҷ»еҹә
иҖғзӮ№дёҺеҠ еҲҶйЎ№
жӢҝ笔记дёҖдёӢпјҒ
иҖғзӮ№
йқўиҜ•зҡ„ж—¶еҖҷй—®дҪ зј“еӯҳпјҢдё»иҰҒжҳҜиҖғеҜҹзј“еӯҳзү№жҖ§зҡ„зҗҶи§ЈпјҢеҜ№ MC гҖҒRedis зҡ„зү№зӮ№е’ҢдҪҝз”Ёж–№ејҸзҡ„жҺҢжҸЎгҖӮ
- еҜ№ DB зғӯзӮ№ж•°жҚ®иҝӣиЎҢзј“еӯҳеҮҸе°‘ DB еҺӢеҠӣпјӣеҜ№дҫқиө–зҡ„жңҚеҠЎиҝӣиЎҢзј“еӯҳпјҢжҸҗй«ҳ并еҸ‘жҖ§иғҪпјӣ
- еҚ•зәҜ K-V зј“еӯҳзҡ„еңәжҷҜеҸҜд»ҘдҪҝз”Ё MC пјҢиҖҢйңҖиҰҒзј“еӯҳ listгҖҒset зӯүзү№ж®Ҡж•°жҚ®ж јејҸпјҢеҸҜд»ҘдҪҝз”Ё Redis пјӣ
- йңҖиҰҒзј“еӯҳдёҖдёӘз”ЁжҲ·жңҖиҝ‘ж’ӯж”ҫи§Ҷйў‘зҡ„еҲ—иЎЁеҸҜд»ҘдҪҝз”Ё Redis зҡ„ list жқҘдҝқеӯҳгҖҒйңҖиҰҒи®Ўз®—жҺ’иЎҢжҰңж•°жҚ®ж—¶пјҢеҸҜд»ҘдҪҝз”Ё Redis зҡ„ zset з»“жһ„жқҘдҝқеӯҳгҖӮ
иҰҒдәҶи§Ј MC е’Ң Redis зҡ„еёёз”Ёе‘Ҫд»ӨпјҢдҫӢеҰӮеҺҹеӯҗеўһеҮҸгҖҒеҜ№дёҚеҗҢж•°жҚ®з»“жһ„иҝӣиЎҢж“ҚдҪңзҡ„е‘Ҫд»ӨзӯүгҖӮ
дәҶи§Ј MC е’Ң Redis еңЁеҶ…еӯҳдёӯзҡ„еӯҳеӮЁз»“жһ„пјҢиҝҷеҜ№иҜ„дј°дҪҝз”Ёе®№йҮҸдјҡеҫҲжңүеё®еҠ©гҖӮ
дәҶи§Ј MC е’Ң Redis зҡ„ж•°жҚ®еӨұж•Ҳж–№ејҸе’Ңеү”йҷӨзӯ–з•ҘпјҢжҜ”еҰӮдё»еҠЁи§ҰеҸ‘зҡ„е®ҡжңҹеү”йҷӨе’Ңиў«еҠЁи§ҰеҸ‘延жңҹеү”йҷӨ
иҰҒзҗҶи§Ј Redis зҡ„жҢҒд№…еҢ–гҖҒдё»д»ҺеҗҢжӯҘдёҺ Cluster йғЁзҪІзҡ„еҺҹзҗҶпјҢжҜ”еҰӮ RDB е’Ң AOF зҡ„е®һзҺ°ж–№ејҸдёҺеҢәеҲ«гҖӮ
иҰҒзҹҘйҒ“зј“еӯҳз©ҝйҖҸгҖҒеҮ»з©ҝгҖҒйӣӘеҙ©еҲҶеҲ«зҡ„ејӮеҗҢзӮ№д»ҘеҸҠи§ЈеҶіж–№жЎҲгҖӮ
дёҚз®ЎдҪ жңүжІЎжңүз”өе•Ҷз»ҸйӘҢжҲ‘и§үеҫ—дҪ йғҪеә”иҜҘзҹҘйҒ“з§’жқҖзҡ„е…·дҪ“е®һзҺ°пјҢд»ҘеҸҠз»ҶиҠӮзӮ№гҖӮ
вҖҰвҖҰ..
еҠ еҲҶйЎ№
еҰӮжһңжғіиҰҒеңЁйқўиҜ•дёӯиҺ·еҫ—жӣҙеҘҪзҡ„иЎЁзҺ°пјҢиҝҳеә”дәҶи§ЈдёӢйқўиҝҷдәӣеҠ еҲҶйЎ№гҖӮ
жҳҜиҰҒз»“еҗҲе®һйҷ…еә”з”ЁеңәжҷҜжқҘд»Ӣз»Қзј“еӯҳзҡ„дҪҝз”ЁгҖӮдҫӢеҰӮи°ғз”ЁеҗҺз«ҜжңҚеҠЎжҺҘеҸЈиҺ·еҸ–дҝЎжҒҜж—¶пјҢеҸҜд»ҘдҪҝз”Ёжң¬ең°+иҝңзЁӢзҡ„еӨҡзә§зј“еӯҳпјӣеҜ№дәҺеҠЁжҖҒжҺ’иЎҢжҰңзұ»зҡ„еңәжҷҜеҸҜд»ҘиҖғиҷ‘йҖҡиҝҮ Redis зҡ„ Sorted set жқҘе®һзҺ°зӯүзӯүгҖӮ
жңҖеҘҪдҪ жңүиҝҮеҲҶеёғејҸзј“еӯҳи®ҫи®Ўе’ҢдҪҝз”Ёз»ҸйӘҢпјҢдҫӢеҰӮйЎ№зӣ®дёӯеңЁд»Җд№ҲеңәжҷҜдҪҝз”ЁиҝҮ Redis пјҢдҪҝз”ЁдәҶд»Җд№Ҳж•°жҚ®з»“жһ„пјҢи§ЈеҶіе“Әзұ»зҡ„й—®йўҳпјӣдҪҝз”Ё MC ж—¶ж №жҚ®йў„дј°еҖјеӨ§е°Ҹи°ғж•ҙ McSlab еҲҶй…ҚеҸӮж•°зӯүзӯүгҖӮ
жңҖеҘҪеҸҜд»ҘдәҶи§Јзј“еӯҳдҪҝз”ЁдёӯеҸҜиғҪдә§з”ҹзҡ„й—®йўҳгҖӮжҜ”еҰӮ Redis жҳҜеҚ•зәҝзЁӢеӨ„зҗҶиҜ·жұӮпјҢеә”е°ҪйҮҸйҒҝе…ҚиҖ—ж—¶иҫғй«ҳзҡ„еҚ•дёӘиҜ·жұӮд»»еҠЎпјҢйҳІжӯўзӣёдә’еҪұе“ҚпјӣRedis жңҚеҠЎеә”йҒҝе…Қе’Ңе…¶д»– CPU еҜҶйӣҶеһӢзҡ„иҝӣзЁӢйғЁзҪІеңЁеҗҢдёҖжңәеҷЁпјӣжҲ–иҖ…зҰҒз”Ё Swap еҶ…еӯҳдәӨжҚўпјҢйҳІжӯў Redis зҡ„зј“еӯҳж•°жҚ®дәӨжҚўеҲ°зЎ¬зӣҳдёҠпјҢеҪұе“ҚжҖ§иғҪгҖӮеҶҚжҜ”еҰӮеүҚйқўжҸҗеҲ°зҡ„ MC й’ҷеҢ–й—®йўҳзӯүзӯүгҖӮ
иҰҒдәҶи§Ј Redis зҡ„е…ёеһӢеә”з”ЁеңәжҷҜпјҢдҫӢеҰӮпјҢдҪҝз”Ё Redis жқҘе®һзҺ°еҲҶеёғејҸй”ҒпјӣдҪҝз”Ё Bitmap жқҘе®һзҺ° BloomFilter пјҢдҪҝз”Ё HyperLogLog жқҘиҝӣиЎҢ UV з»ҹи®ЎзӯүзӯүгҖӮ
зҹҘйҒ“ Redis4.0гҖҒ5.0 дёӯзҡ„ж–°зү№жҖ§пјҢдҫӢеҰӮж”ҜжҢҒеӨҡж’ӯзҡ„еҸҜжҢҒд№…еҢ–ж¶ҲжҒҜйҳҹеҲ— StreamпјӣйҖҡиҝҮ Module зі»з»ҹжқҘиҝӣиЎҢе®ҡеҲ¶еҠҹиғҪжү©еұ•зӯүзӯүгҖӮ
е…ідәҺвҖңRedisзҡ„йқўиҜ•йўҳжңүе“ӘдәӣвҖқиҝҷзҜҮж–Үз« е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢдҪҝеҗ„дҪҚеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶпјҢеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢиҜ·жҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ