序列化:把内存中的数据类型转换为字符串,以便能够存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes。
反序列化:把硬盘中的数据转换为内存数据类型
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
data = {"haha":"哈哈"}
fw = open(file="写文件.txt",mode="w",encoding="utf-8")
fw.write(str(data)) # 序列化
fw.close()
fr = open(file="写文件.txt",mode="r",encoding="utf-8")
d = fr.read()
d = eval(d) # 反序列化
print(d)
fr.close()
E:\PythonProject\python-test\venvP3\Scripts\python.exe E:/PythonProject/python-test/BasicGrammer/test.py
{'haha': '哈哈'}
Process finished with exit code 0
优点:跨语言、体积小
缺点:只能支持int\str\list\tuple\dict
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
import json
data = {"haha":"哈哈"}
# dumps并没有把内容写入到硬盘中
d = json.dumps(data)
print(d,type(d))
E:\PythonProject\python-test\venvP3\Scripts\python.exe E:/PythonProject/python-test/BasicGrammer/test.py
{"haha": "\u54c8\u54c8"} <class 'str'>
Process finished with exit code 0
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
import json
data = {"haha":"哈哈"}
# dumps并没有把内容写入到硬盘中
d = json.dumps(data)
d2 = json.loads(d)
print(d2,type(d2))
E:\PythonProject\python-test\venvP3\Scripts\python.exe E:/PythonProject/python-test/BasicGrammer/test.py
{'haha': '哈哈'} <class 'dict'>
Process finished with exit code 0#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
import json
data = {"haha":"哈哈"}
fw = open(file="写文件.txt",mode="w",encoding="utf-8")
d = json.dump(data,fw)
E:\PythonProject\python-test\venvP3\Scripts\python.exe E:/PythonProject/python-test/BasicGrammer/test.py
Process finished with exit code 0
查看文件中的内容
{"haha": "\u54c8\u54c8"}#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
import json
data = {"haha":"哈哈"}
fr = open(file="写文件.txt",mode="r",encoding="utf-8")
d = json.load(fr)
print(d,type(d))
E:\PythonProject\python-test\venvP3\Scripts\python.exe E:/PythonProject/python-test/BasicGrammer/test.py
{'haha': '哈哈'} <class 'dict'>
Process finished with exit code 0
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
import json
data = {"haha":"哈哈"}
data2 = {"hehe":"呵呵"}
fw = open(file="写文件.json",mode="w",encoding="utf-8")
json.dump(data,fw)
json.dump(data2,fw)
E:\PythonProject\python-test\venvP3\Scripts\python.exe E:/PythonProject/python-test/BasicGrammer/test.py
Process finished with exit code 0
查看文件内容
{"haha": "\u54c8\u54c8"}{"hehe": "\u5475\u5475"}
多次dump是没有报错,但是load()#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
import json
data = {"haha":"哈哈"}
data2 = {"hehe":"呵呵"}
fr = open(file="写文件.json",mode="r",encoding="utf-8")
print(json.load(fr))
E:\PythonProject\python-test\venvP3\Scripts\python.exe E:/PythonProject/python-test/BasicGrammer/test.py
Traceback (most recent call last):
File "E:/PythonProject/python-test/BasicGrammer/test.py", line 8, in <module>
print(json.load(fr))
File "D:\software2\Python3\install\lib\json\__init__.py", line 299, in load
parse_constant=parse_constant, object_pairs_hook=object_pairs_hook, **kw)
File "D:\software2\Python3\install\lib\json\__init__.py", line 354, in loads
return _default_decoder.decode(s)
File "D:\software2\Python3\install\lib\json\decoder.py", line 342, in decode
raise JSONDecodeError("Extra data", s, end)
json.decoder.JSONDecodeError: Extra data: line 1 column 25 (char 24)
Process finished with exit code 1
"说明不要dump多次,虽然dump不报错,但是load不回来了。因为在一行有两种类型的数据"优点:转为python设计,支持python所有数据类型。
缺点:只能在python中使用,存储数据占用空间大。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
import pickle
data = {"haha":"哈哈"}
d = pickle.dumps(data)
print(d,type(d))
l = pickle.loads(d)
print(l,type(l))
E:\PythonProject\python-test\venvP3\Scripts\python.exe E:/PythonProject/python-test/BasicGrammer/test.py
b'\x80\x03}q\x00X\x04\x00\x00\x00hahaq\x01X\x06\x00\x00\x00\xe5\x93\x88\xe5\x93\x88q\x02s.' <class 'bytes'>
{'haha': '哈哈'} <class 'dict'>
Process finished with exit code 0#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
import pickle
data = {"haha":"哈哈"}
fw = open(file="写文件.json",mode="wb") #由于dump后数据类型是bytes类型,所以mode="wb"
d = pickle.dump(data,fw)
fw.close()
fr = open(file="写文件.json",mode="rb") #写入时是wb,读取时是rb
l = pickle.load(fr)
print(l,type(l))
fr.close()
E:\PythonProject\python-test\venvP3\Scripts\python.exe E:/PythonProject/python-test/BasicGrammer/test.py
{'haha': '哈哈'} <class 'dict'>
Process finished with exit code 0
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
import pickle
def fun():
print("232")
d = pickle.dumps(fun)
print(d,type(d))
l = pickle.loads(d)
print(l,type(l))
E:\PythonProject\python-test\venvP3\Scripts\python.exe E:/PythonProject/python-test/BasicGrammer/test.py
b'\x80\x03c__main__\nfun\nq\x00.' <class 'bytes'>
<function fun at 0x00000157C0883E18> <class 'function'>
Process finished with exit code 0
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
import pickle
def fun():
print("232")
fw = open(file="写文件.json",mode="wb")
d = pickle.dump(fun,fw)
fw.close()
fr = open(file="写文件.json",mode="rb")
l = pickle.load(fr)
print(l,type(l))
fr.close()
E:\PythonProject\python-test\venvP3\Scripts\python.exe E:/PythonProject/python-test/BasicGrammer/test.py
<function fun at 0x0000017668504C80> <class 'function'>
Process finished with exit code 0
可序列化多次,反序列化多次,就像操作字典一样操作数据
shelve是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式
"注意:shelve打开文件时,文件如果是存在的,是会报下面的错误的"
E:\PythonProject\python-test\venvP3\Scripts\python.exe E:/PythonProject/python-test/BasicGrammer/test.py
Traceback (most recent call last):
File "E:/PythonProject/python-test/BasicGrammer/test.py", line 5, in <module>
f = shelve.open("写文件.txt")
File "D:\software2\Python3\install\lib\shelve.py", line 243, in open
return DbfilenameShelf(filename, flag, protocol, writeback)
File "D:\software2\Python3\install\lib\shelve.py", line 227, in __init__
Shelf.__init__(self, dbm.open(filename, flag), protocol, writeback)
File "D:\software2\Python3\install\lib\dbm\__init__.py", line 88, in open
raise error[0]("db type could not be determined")
dbm.error: db type could not be determined
Process finished with exit code 1
"shelve序列化"
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
import shelve
f = shelve.open("写文件.txt") #此处的文件不能是已经存在的
names = ["vita","丽丽","lyly"]
info = {"name":"vita","age":23}
f["names"]=names
f["info_dic"]=info
f.close()
E:\PythonProject\python-test\venvP3\Scripts\python.exe E:/PythonProject/python-test/BasicGrammer/test.py
Process finished with exit code 0
写入成功后,产生如下的文件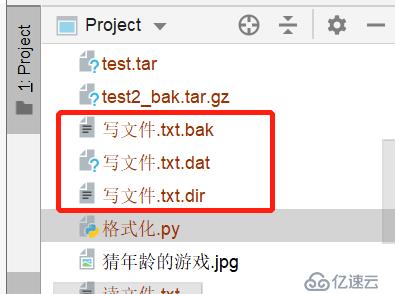
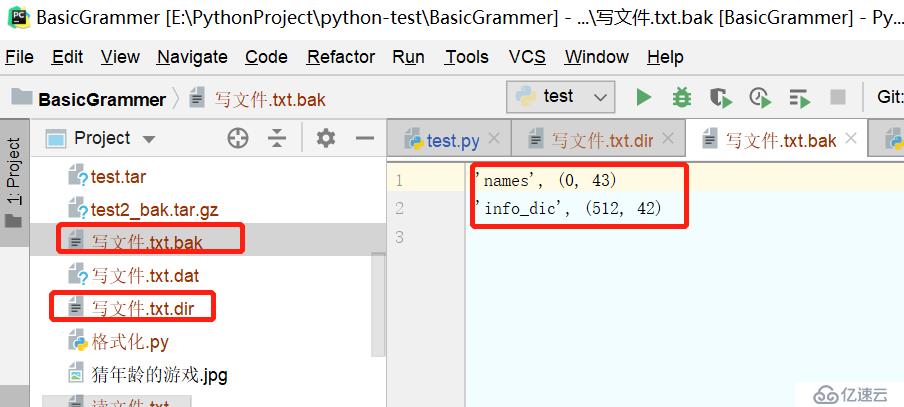
"shelve反序列化"
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
import shelve
f = shelve.open("写文件.txt")
print(f["names"])
print(f["info_dic"])
E:\PythonProject\python-test\venvP3\Scripts\python.exe E:/PythonProject/python-test/BasicGrammer/test.py
['vita', '丽丽', 'lyly']
{'name': 'vita', 'age': 23}
Process finished with exit code 0
"查询"
>>> f = shelve.open("写文件.txt")
>>> f
<shelve.DbfilenameShelf object at 0x000002A52DB5E780>
>>> f.keys()
KeysView(<shelve.DbfilenameShelf object at 0x000002A52DB5E780>)
>>> list(f.keys())
['names', 'info_dic']
>>> list(f.items())
[('names', ['vita', '丽丽', 'lyly']), ('info_dic', {'name': 'vita', 'age': 23})]
>>> f.get("names")
['vita', '丽丽', 'lyly']
>>> f.get("info_dic")
{'name': 'vita', 'age': 23}
>>> f["names"][1]
'丽丽'
"修改"
>>> f["names"][1]="超超" #这样修改是不可以的
>>> f["names"][1] "
'丽丽'
>>> f["names"]=["ccc","lll"] #可以这样修改
>>> f["names"]
['ccc', 'lll']
>>> f.items()
ItemsView(<shelve.DbfilenameShelf object at 0x000002A52DB5E780>)
>>> list(f.items())
[('names', ['ccc', 'lll']), ('info_dic', {'name': 'vita', 'age': 23})]
"删除"
>>> del f["names"]
>>> list(f.items())
[('info_dic', {'name': 'vita', 'age': 23})]
"增加"
>>> f["scores"]=[90,89]
>>> list(f.items())
[('info_dic', {'name': 'vita', 'age': 23}), ('scores', [90, 89])]
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



