这篇文章给大家分享的是有关selenium怎么处理iframe作用域问题的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
在使用python进行爬虫操作的过程中,一般为了防止爬虫,会使用iframe,但是由于iframe有限制,iframe是前端内嵌页面,访问域名与主网页不同,所以有时会得到不自己想要的数据。本文针对抓包工具定位没有定位到iframe中的小的html中提供解决方法。
以文本块生成xpath为/html/body/text(),根据xpath进行如下代码编写。
#!/user/bin/
# -*- coding:UTF-8 -*-
# Author:Master
from selenium import webdriver
import time
driver = webdriver.Chrome(executable_path="./chromedriver")
driver.get('https://www.runoob.com/try/runcode.php?filename=HelloWorld&type=python3')
time.sleep(2)
text = driver.find_element_by_xpath('/html/body').text
print(text)
time.sleep(5)
driver.quit()得到结果
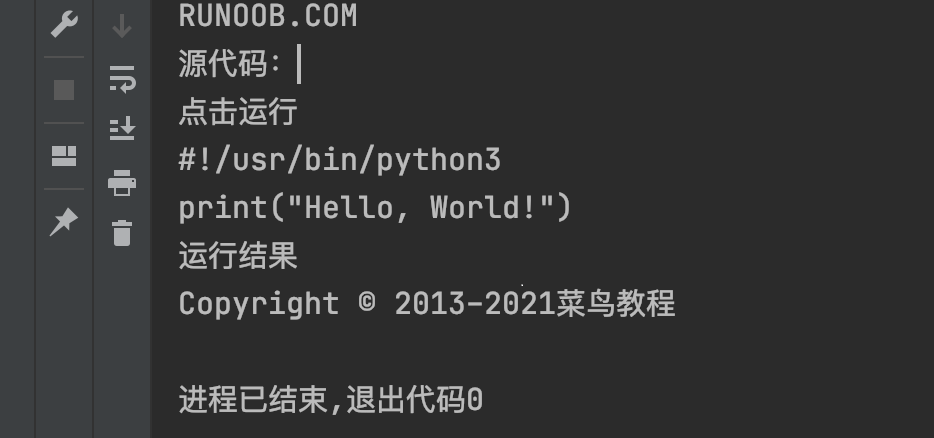
原因分析
当我们打开抓包工具定位到Hello, World!文本的时候会发现,该文本是在一个iframe中。这样的话我们xpath所定位到的内容则是大的html中的路径。我们需要的内容则是在iframe中的小的html中。
解决方法
通过分析发现,想要解决问题的实质就是改变作用域。通过switch_to.frame(‘id’)方法来改变作用域就可以了。
重新编写代码:
#!/user/bin/
# -*- coding:UTF-8 -*-
# Author:Master
from selenium import webdriver
import time
driver = webdriver.Chrome(executable_path="./chromedriver")
driver.get('https://www.runoob.com/try/runcode.php?filename=HelloWorld&type=python3')
time.sleep(2)
driver.switch_to.frame('iframeResult')
text = driver.find_element_by_xpath('/html/body').text
print(text)
time.sleep(5)
driver.quit()运行结果
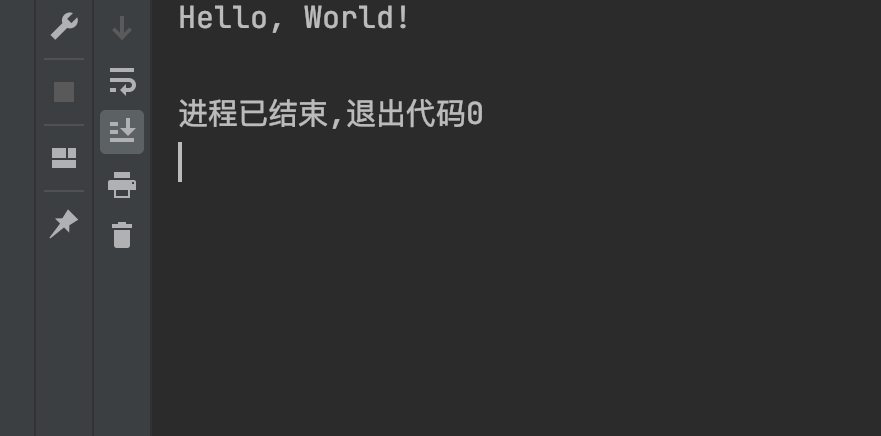
感谢各位的阅读!关于“selenium怎么处理iframe作用域问题”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





