本篇文章为大家展示了怎么在R语言中使用summary()函数,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
R语言是用于统计分析、绘图的语言和操作环境,属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
summary():获取描述性统计量,可以提供最小值、最大值、四分位数和数值型变量的均值,以及因子向量和逻辑型向量的频数统计等。
结果解读如下:
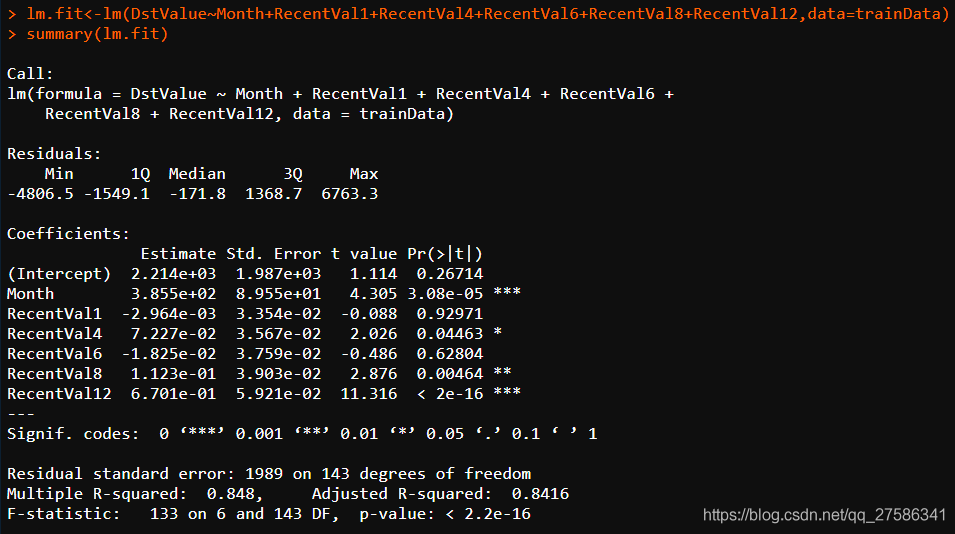
lm(formula = DstValue ~ Month + RecentVal1 + RecentVal4 + RecentVal6 + RecentVal8 + RecentVal12, data = trainData)
当创建模型时,以上代码表明lm是如何被调用的。
Min 1Q Median 3Q Max -4806.5 -1549.1 -171.8 1368.7 6763.3
残差第一四分位数(1Q)和第三分位数(Q3)有大约相同的幅度,意味着有较对称的钟形分布。
Estimate Std. Error t value Pr(>|t|) (Intercept) 1.345e+06 5.659e+05 2.377 0.01879 * Month 8.941e+02 2.072e+02 4.316 3.00e-05 ***
分别表示: 估值 标准误差 T值 P值
Intercept:表示截距
Month:影响因子/特征
Estimate的列:包含由普通最小二乘法计算出来的估计回归系数。
Std. Error的列:估计的回归系数的标准误差。
P值估计系数不显著的可能性,有较大P值的变量是可以从模型中移除的候选变量。
t 统计量和P值:从理论上说,如果一个变量的系数是0,那么该变量是无意义的,它对模型毫无贡献。
然而,这里显示的系数只是估计,它们不会正好为0。
因此,我们不禁会问:从统计的角度而言,真正的系数为0的可能性有多大?这是t统计量和P值的目的,在汇总中被标记为t value和Pr(>|t|)。
其 中,我们可以直接通过P值与我们预设的0.05进行比较,来判定对应的解释变量的显著性,我们检验的原假设是:该系数显著为0;若P<0.05,则拒绝原假设,即对应的变量显著不为0。
可以看到Month、RecentVal4、RecentVal8都可以认为是在P为0.05的水平下显著不为0,通过显著性检验;Intercept的P值为0.26714,不显著。
这两个值,即R^{2},常称之为“拟合优度”和“修正的拟合优度”,指回归方程对样本的拟合程度几何,这里我们可以看到,修正的拟合优 度=0.8416,表示拟合程度良好,这个值当然是越高越好。
当然,提升拟合优度的方法很多,当达到某个程度,我们也就认为差不多了。
具体还有很复杂的判定内容,有兴趣的可以看看:http://baike.baidu.com/view/657906.htm
F-statistic,是我们常说的F统计量,也成为F检验,常常用于判断方程整体的显著性检验,其值越大越显著;其P值为p-value: < 2.2e-16,显然是<0.05的,可以认为方程在P=0.05的水平上还是通过显著性检验的。
T检验:检验解释变量的显著性;
R-squared:查看方程拟合程度;
F检验:是检验方程整体显著性。
如果是一元线性回归方程,T检验的值和F检验的检验效果是一样的,对应的值也是相同的。
补充:在R语言中显示美丽的数据摘要summary统计信息
## Skim summary statistics ## n obs: 150 ## n variables: 5 ## ## Variable type: factor ## variable missing complete n n_unique top_counts ## 1 Species 0 150 150 3 set: 50, ver: 50, vir: 50, NA: 0 ## ordered ## 1 FALSE ## ## Variable type: numeric ## variable missing complete n mean sd min p25 median p75 max ## 1 Petal.Length 0 150 150 3.76 1.77 1 1.6 4.35 5.1 6.9 ## 2 Petal.Width 0 150 150 1.2 0.76 0.1 0.3 1.3 1.8 2.5 ## 3 Sepal.Length 0 150 150 5.84 0.83 4.3 5.1 5.8 6.4 7.9 ## 4 Sepal.Width 0 150 150 3.06 0.44 2 2.8 3 3.3 4.4 ## hist ## 1 ▇▁▁▂▅▅▃▁ ## 2 ▇▁▁▅▃▃▂▂ ## 3 ▂▇▅▇▆▅▂▂ ## 4 ▁▂▅▇▃▂▁▁
## Skim summary statistics ## n obs: 150 ## n variables: 5 ## ## Variable type: numeric ## variable missing complete n mean sd min p25 median p75 max ## 1 Petal.Length 0 150 150 3.76 1.77 1 1.6 4.35 5.1 6.9 ## 2 Sepal.Length 0 150 150 5.84 0.83 4.3 5.1 5.8 6.4 7.9 ## hist ## 1 ▇▁▁▂▅▅▃▁ ## 2 ▂▇▅▇▆▅▂▂
可以处理已使用分组的数据dplyr::group_by。
## Skim summary statistics ## n obs: 150 ## n variables: 5 ## group variables: Species ## ## Variable type: numeric ## Species variable missing complete n mean sd min p25 median ## 1 setosa Petal.Length 0 50 50 1.46 0.17 1 1.4 1.5 ## 2 setosa Petal.Width 0 50 50 0.25 0.11 0.1 0.2 0.2 ## 3 setosa Sepal.Length 0 50 50 5.01 0.35 4.3 4.8 5 ## 4 setosa Sepal.Width 0 50 50 3.43 0.38 2.3 3.2 3.4 ## 5 versicolor Petal.Length 0 50 50 4.26 0.47 3 4 4.35 ## 6 versicolor Petal.Width 0 50 50 1.33 0.2 1 1.2 1.3 ## 7 versicolor Sepal.Length 0 50 50 5.94 0.52 4.9 5.6 5.9 ## 8 versicolor Sepal.Width 0 50 50 2.77 0.31 2 2.52 2.8 ## 9 virginica Petal.Length 0 50 50 5.55 0.55 4.5 5.1 5.55 ## 10 virginica Petal.Width 0 50 50 2.03 0.27 1.4 1.8 2 ## 11 virginica Sepal.Length 0 50 50 6.59 0.64 4.9 6.23 6.5 ## 12 virginica Sepal.Width 0 50 50 2.97 0.32 2.2 2.8 3 ## p75 max hist ## 1 1.58 1.9 ▁▁▅▇▇▅▂▁ ## 2 0.3 0.6 ▂▇▁▂▂▁▁▁ ## 3 5.2 5.8 ▂▃▅▇▇▃▁▂ ## 4 3.68 4.4 ▁▁▃▅▇▃▂▁ ## 5 4.6 5.1 ▁▃▂▆▆▇▇▃ ## 6 1.5 1.8 ▆▃▇▅▆▂▁▁ ## 7 6.3 7 ▃▂▇▇▇▃▅▂ ## 8 3 3.4 ▁▂▃▅▃▇▃▁ ## 9 5.88 6.9 ▂▇▃▇▅▂▁▂ ## 10 2.3 2.5 ▂▁▇▃▃▆▅▃ ## 11 6.9 7.9 ▁▁▃▇▅▃▂▃ ## 12 3.18 3.8 ▁▃▇▇▅▃▁▂
可以用户使用与该skim_with()功能组合的列表来指定自己的统计信息。
## Skim summary statistics ## n obs: 150 ## n variables: 5 ## ## Variable type: numeric ## variable iqr mad ## 1 Sepal.Length 1.3 1.04
上述内容就是怎么在R语言中使用summary()函数,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





