scrapydweb.herokuapp.com
访问 heroku.com 注册免费账号(注册页面需要调用 google recaptcha 人机验证,登录页面也需要科学地进行上网,访问 app 运行页面则没有该问题),免费账号最多可以创建和运行5个 app。
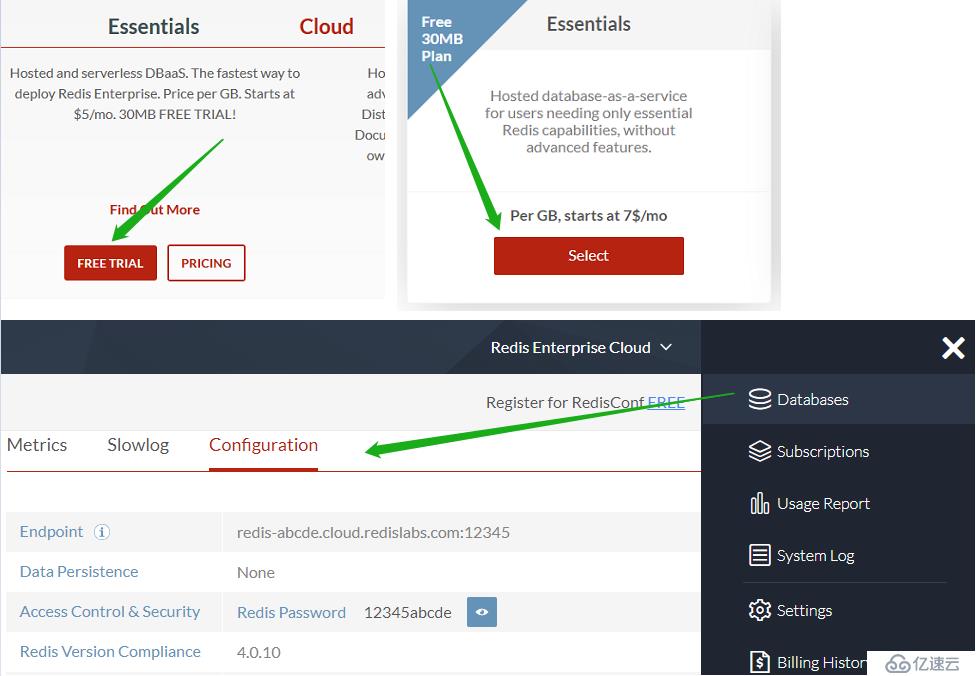
访问 redislabs.com 注册免费账号,提供30MB 存储空间,用于下文通过 scrapy-redis 实现分布式爬虫。
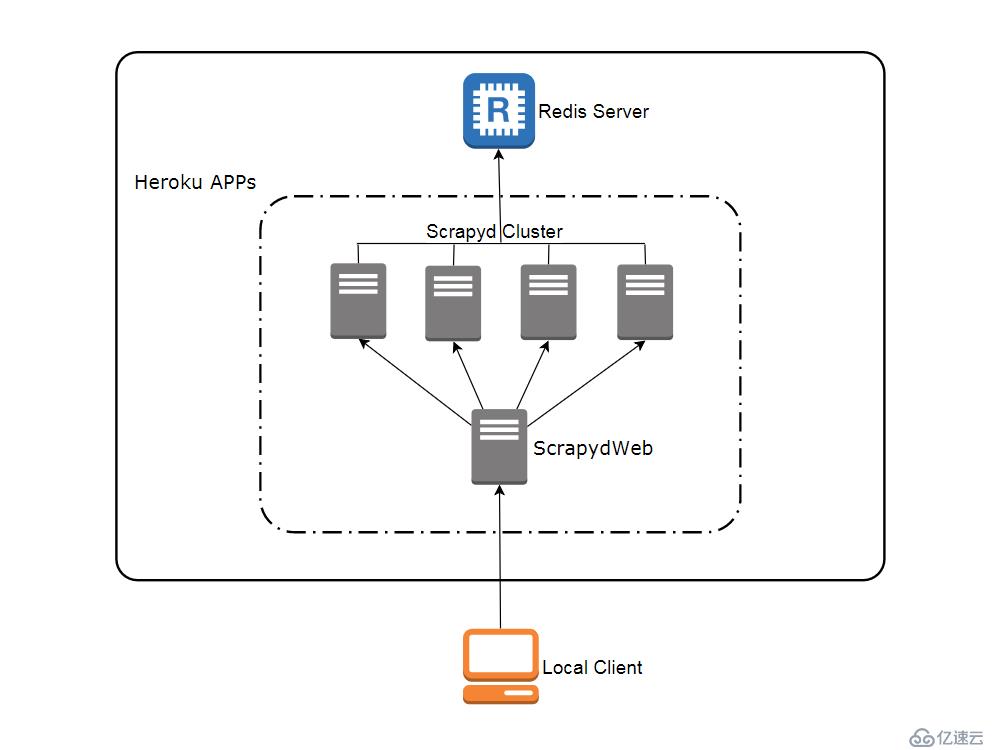
svr-1, svr-2, svr-3 和 svr-4myscrapydwebSCRAPYD_SERVER_2, VALUE 为 svr-2.herokuapp.com:80#group2pip install redis 命令即可。新开一个命令行提示符:
git clone https://github.com/my8100/scrapyd-cluster-on-heroku
cd scrapyd-cluster-on-herokuheroku login
# outputs:
# heroku: Press any key to open up the browser to login or q to exit:
# Opening browser to https://cli-auth.heroku.com/auth/browser/12345-abcde
# Logging in... done
# Logged in as username@gmail.com新建 Git 仓库
cd scrapyd
git init
# explore and update the files if needed
git status
git add .
git commit -a -m "first commit"
git status部署 Scrapyd app
heroku apps:create svr-1
heroku git:remote -a svr-1
git remote -v
git push heroku master
heroku logs --tail
# Press ctrl+c to stop logs outputting
# Visit https://svr-1.herokuapp.com添加环境变量
# python -c "import tzlocal; print(tzlocal.get_localzone())"
heroku config:set TZ=Asia/Shanghai
# heroku config:get TZheroku config:set REDIS_HOST=your-redis-host
heroku config:set REDIS_PORT=your-redis-port
heroku config:set REDIS_PASSWORD=your-redis-passwordsvr-2,svr-3 和 svr-4新建 Git 仓库
cd ..
cd scrapydweb
git init
# explore and update the files if needed
git status
git add .
git commit -a -m "first commit"
git status部署 ScrapydWeb app
heroku apps:create myscrapydweb
heroku git:remote -a myscrapydweb
git remote -v
git push heroku master添加环境变量
heroku config:set TZ=Asia/Shanghaiheroku config:set SCRAPYD_SERVER_1=svr-1.herokuapp.com:80
heroku config:set SCRAPYD_SERVER_2=svr-2.herokuapp.com:80#group1
heroku config:set SCRAPYD_SERVER_3=svr-3.herokuapp.com:80#group1
heroku config:set SCRAPYD_SERVER_4=svr-4.herokuapp.com:80#group2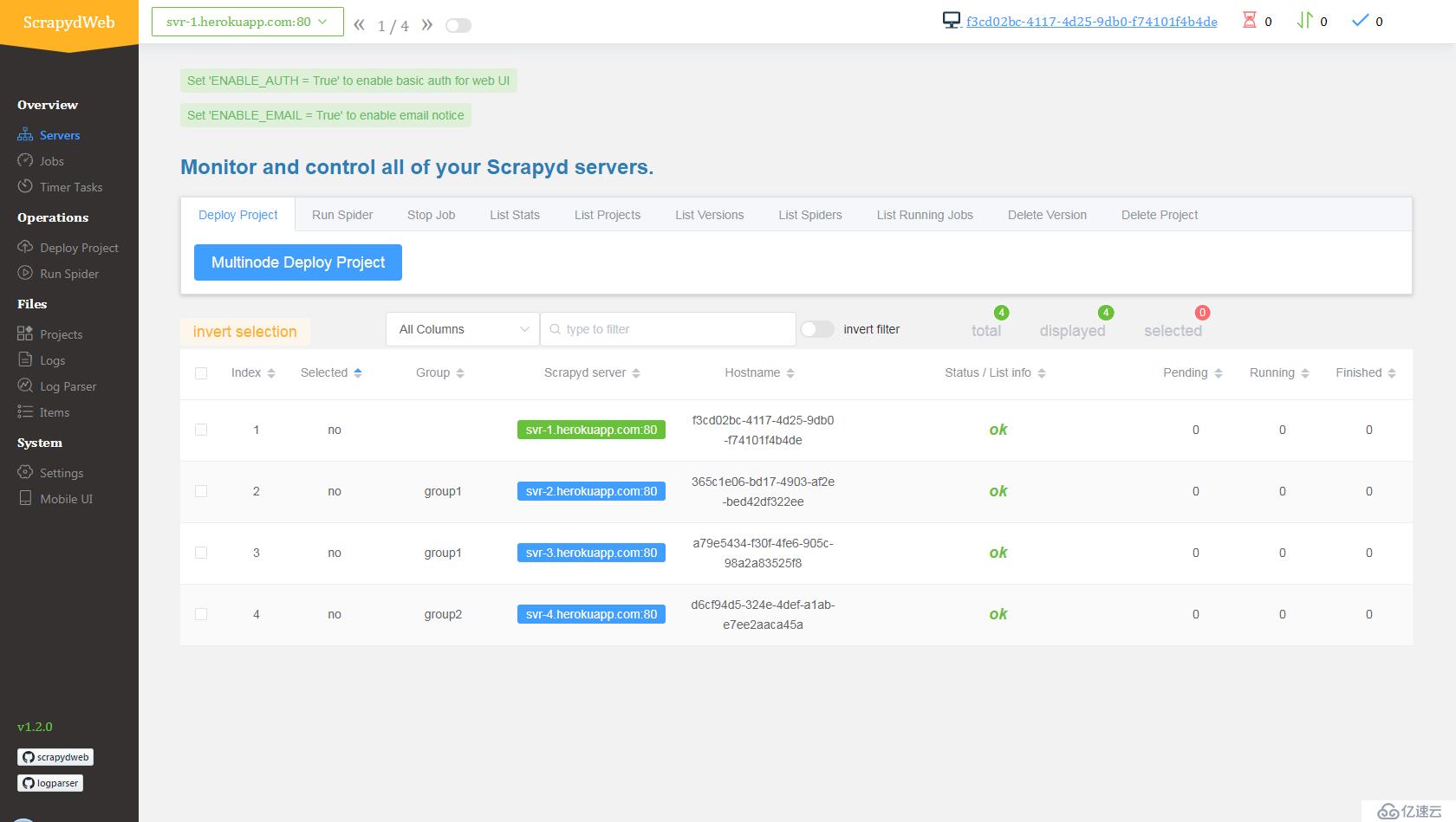
mycrawler:start_urls 触发爬虫并查看结果In [1]: import redis # pip install redis
In [2]: r = redis.Redis(host='your-redis-host', port=your-redis-port, password='your-redis-password')
In [3]: r.delete('mycrawler_redis:requests', 'mycrawler_redis:dupefilter', 'mycrawler_redis:items')
Out[3]: 0
In [4]: r.lpush('mycrawler:start_urls', 'http://books.toscrape.com', 'http://quotes.toscrape.com')
Out[4]: 2
# wait for a minute
In [5]: r.lrange('mycrawler_redis:items', 0, 1)
Out[5]:
[b'{"url": "http://quotes.toscrape.com/", "title": "Quotes to Scrape", "hostname": "d6cf94d5-324e-4def-a1ab-e7ee2aaca45a", "crawled": "2019-04-02 03:42:37", "spider": "mycrawler_redis"}',
b'{"url": "http://books.toscrape.com/index.html", "title": "All products | Books to Scrape - Sandbox", "hostname": "d6cf94d5-324e-4def-a1ab-e7ee2aaca45a", "crawled": "2019-04-02 03:42:37", "spider": "mycrawler_redis"}']
my8100/scrapyd-cluster-on-heroku
亿速云免费服务器限时活动,即开即用、新—代英特尔至强铂金CPU、SSD云盘,0元免费领,库存有限,领完即止! 点击查看>>点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



