如何在Python中使用Blending算法?相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
普通机器学习:从训练数据中学习一个假设。
集成方法:试图构建一组假设并将它们组合起来,集成学习是一种机器学习范式,多个学习器被训练来解决同一个问题。
集成方法分类为:
Bagging(并行训练):随机森林
Boosting(串行训练):Adaboost; GBDT; XgBoost
Stacking:
Blending:
或者分类为串行集成方法和并行集成方法
1.串行模型:通过基础模型之间的依赖,给错误分类样本一个较大的权重来提升模型的性能。
2.并行模型的原理:利用基础模型的独立性,然后通过平均能够较大地降低误差
训练数据划分为训练和验证集+新的训练数据集和新的测试集
将训练数据进行划分,划分之后的训练数据一部分训练基模型,一部分经模型预测后作为新的特征训练元模型。
测试数据同样经过基模型预测,形成新的测试数据。最后,元模型对新的测试数据进行预测。Blending框架图如下所示:
注意:其是在stacking的基础上加了划分数据
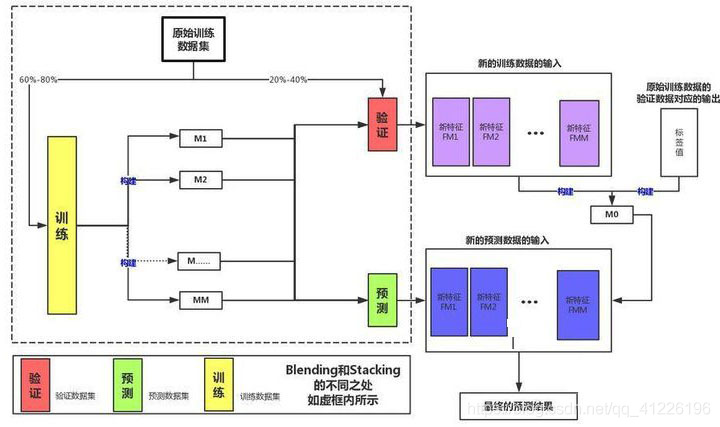
第一步:将原始训练数据划分为训练集和验证集。
第二步:使用训练集对训练T个不同的模型。
第三步:使用T个基模型,对验证集进行预测,结果作为新的训练数据。
第四步:使用新的训练数据,训练一个元模型。
第五步:使用T个基模型,对测试数据进行预测,结果作为新的测试数据。
第六步:使用元模型对新的测试数据进行预测,得到最终结果。

相关工具包加载
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use("ggplot")
%matplotlib inline
import seaborn as sns创建数据
from sklearn import datasets
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
data, target = make_blobs(n_samples=10000, centers=2, random_state=1, cluster_std=1.0 )
## 创建训练集和测试集
X_train1,X_test,y_train1,y_test = train_test_split(data, target, test_size=0.2, random_state=1)
## 创建训练集和验证集
X_train,X_val,y_train,y_val = train_test_split(X_train1, y_train1, test_size=0.3, random_state=1)
print("The shape of training X:",X_train.shape)
print("The shape of training y:",y_train.shape)
print("The shape of test X:",X_test.shape)
print("The shape of test y:",y_test.shape)
print("The shape of validation X:",X_val.shape)
print("The shape of validation y:",y_val.shape)设置第一层分类器
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifierclfs = [SVC(probability=True),RandomForestClassifier(n_estimators=5,n_jobs=-1,criterion='gini'),KNeighborsClassifier()]设置第二层分类器
from sklearn.linear_model import LinearRegression
lr = LinearRegression()第一层
val_features = np.zeros((X_val.shape[0],len(clfs)))
test_features = np.zeros((X_test.shape[0],len(clfs)))for i,clf in enumerate(clfs):
clf.fit(X_train,y_train)
val_feature = clf.predict_proba(X_val)[:,1]
test_feature = clf.predict_proba(X_test)[:,1]
val_features[:,i] = val_feature
test_features[:,i] = test_feature第二层
lr.fit(val_features,y_val)输出预测的结果
lr.fit(val_features,y_val)
from sklearn.model_selection import cross_val_score
cross_val_score(lr,test_features,y_test,cv=5)1、云计算,典型应用OpenStack。2、WEB前端开发,众多大型网站均为Python开发。3.人工智能应用,基于大数据分析和深度学习而发展出来的人工智能本质上已经无法离开python。4、系统运维工程项目,自动化运维的标配就是python+Django/flask。5、金融理财分析,量化交易,金融分析。6、大数据分析。
看完上述内容,你们掌握如何在Python中使用Blending算法的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



