这篇文章主要讲解了“Linux内存分配的详细过程”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Linux内存分配的详细过程”吧!
本文使用 Linux 2.6.32 版本代码
内存分区对象
在《你真的理解内存分配》一文中介绍过,Linux 会把进程虚拟内存空间划分为多个分区,在 Linux 内核中使用 vm_area_struct 对象来表示,其定义如下:
struct vm_area_struct { struct mm_struct *vm_mm; // 分区所属的内存管理对象 unsigned long vm_start; // 分区的开始地址 unsigned long vm_end; // 分区的结束地址 struct vm_area_struct *vm_next; // 通过这个指针把进程所有的内存分区连接成一个链表 ... struct rb_node vm_rb; // 红黑树的节点, 用于保存到内存分区红黑树中 ... };我们对 vm_area_struct 对象进行了简化,只保留了本文需要的字段。
内核就是使用 vm_area_struct 对象来记录一个内存分区(如 代码段、数据段 和 堆空间 等),下面介绍一下 vm_area_struct 对象各个字段的作用:
vm_mm:指定了当前内存分区所属的内存管理对象。
vm_start:内存分区的开始地址。
vm_end:内存分区的结束地址。
vm_next:通过这个指针把进程中所有的内存分区连接成一个链表。
vm_rb:另外,为了快速查找内存分区,内核还把进程的所有内存分区保存到一棵红黑树中。vm_rb 就是红黑树的节点,用于把内存分区保存到红黑树中。
假如进程 A 现在有 4 个内存分区,它们的范围如下:
代码段:00400000 ~ 00401000
数据段:00600000 ~ 00601000
堆空间:00983000 ~ 009a4000
栈空间:7f37ce866000 ~ 7f3fce867000
那么这 4 个内存分区在内核中的结构如 图1 所示:
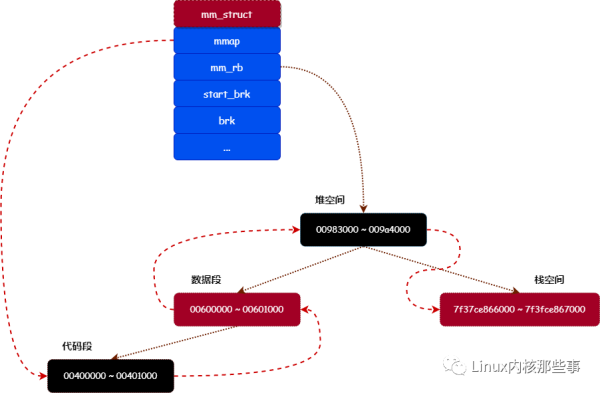
在 图1 中,我们可以看到有个 mm_struct 的对象,此对象每个进程都持有一个,是进程虚拟内存空间和物理内存空间的管理对象。我们简单介绍一下这个对象,其定义如下:
struct mm_struct { struct vm_area_struct *mmap; // 指向由进程内存分区连接成的链表 struct rb_root mm_rb; // 内核使用红黑树保存进程的所有内存分区, 这个是红黑树的根节点 unsigned long start_brk, brk; // 堆空间的开始地址和结束地址 ... };我们来介绍下 mm_struct 对象各个字段的作用:
mmap:指向由进程所有内存分区连接成的链表。
mm_rb:内核为了加快查找内存分区的速度,使用了红黑树保存所有内存分区,这个就是红黑树的根节点。
start_brk:堆空间的开始内存地址。
brk:堆空间的顶部内存地址。
我们来回顾一下进程虚拟内存空间的布局图,如 图2 所示:
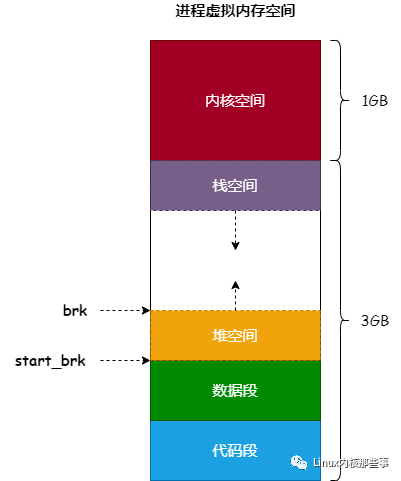
start_brk 和 brk 字段用来记录堆空间的范围, 如 图2 所示。一般来说,start_brk 是不会变的,而 brk 会随着分配内存和释放内存而变化。
虚拟内存分配
在《你真的理解内存分配》一文中说过,调用 malloc 申请内存时,最终会调用 brk 系统调用来从堆空间中分配内存。我们来分析一下 brk 系统调用的实现:
unsigned long sys_brk(unsigned long brk) { unsigned long rlim, retval; unsigned long newbrk, oldbrk; struct mm_struct *mm = current->mm; ... down_write(&mm->mmap_sem); // 对内存管理对象进行上锁 ... // 判断堆空间的大小是否超出限制, 如果超出限制, 就不进行处理 rlim = current->signal->rlim[RLIMIT_DATA].rlim_cur; if (rlim < RLIM_INFINITY && (brk - mm->start_brk) + (mm->end_data - mm->start_data) > rlim) goto out; newbrk = PAGE_ALIGN(brk); // 新的brk值 oldbrk = PAGE_ALIGN(mm->brk); // 旧的brk值 if (oldbrk == newbrk) // 如果新旧的位置都一样, 就不需要进行处理 goto set_brk; ... // 调用 do_brk 函数进行下一步处理 if (do_brk(oldbrk, newbrk-oldbrk) != oldbrk) goto out; set_brk: mm->brk = brk; // 设置堆空间的顶部位置(brk指针) out: retval = mm->brk; up_write(&mm->mmap_sem); return retval; }总结上面的代码,主要有以下几个步骤:
1、判断堆空间的大小是否超出限制,如果超出限制,就不作任何处理,直接返回旧的 brk 值。
2、如果新的 brk 值跟旧的 brk 值一致,那么也不用作任何处理。
3、如果新的 brk 值发生变化,那么就调用 do_brk 函数进行下一步处理。
4、设置进程的 brk 指针(堆空间顶部)为新的 brk 的值。
我们看到第 3 步调用了 do_brk 函数来处理,do_brk 函数的实现有点小复杂,所以这里介绍一下大概处理流程:
鸿蒙官方战略合作共建——HarmonyOS技术社区
通过堆空间的起始地址 start_brk 从进程内存分区红黑树中找到其对应的内存分区对象(也就是 vm_area_struct)。
把堆空间的内存分区对象的 vm_end 字段设置为新的 brk 值。
至此,brk 系统调用的工作就完成了(上面没有分析释放内存的情况),总结来说,brk 系统调用的工作主要有两部分:
把进程的 brk 指针设置为新的 brk 值。
把堆空间的内存分区对象的 vm_end 字段设置为新的 brk 值。
物理内存分配
从上面的分析知道,brk 系统调用申请的是 虚拟内存,但存储数据只能使用 物理内存。所以,虚拟内存必须映射到物理内存才能被使用。
那么什么时候才进行内存映射呢?
在《你真的理解内存分配》一文中介绍过,当对没有映射的虚拟内存地址进行读写操作时,CPU 将会触发 缺页异常。内核接收到 缺页异常 后, 会调用 do_page_fault 函数进行修复。
我们来分析一下 do_page_fault 函数的实现(精简后):
void do_page_fault(struct pt_regs *regs, unsigned long error_code) { struct vm_area_struct *vma; struct task_struct *tsk; unsigned long address; struct mm_struct *mm; int write; int fault; tsk = current; mm = tsk->mm; address = read_cr2(); // 获取导致页缺失异常的虚拟内存地址 ... vma = find_vma(mm, address); // 通过虚拟内存地址从进程内存分区中查找对应的内存分区对象 ... if (likely(vma->vm_start <= address)) // 如果找到内存分区对象 goto good_area; ... good_area: write = error_code & PF_WRITE; ... // 调用 handle_mm_fault 函数对虚拟内存地址进行映射操作 fault = handle_mm_fault(mm, vma, address, write ? FAULT_FLAG_WRITE : 0); ... }do_page_fault 函数主要完成以下操作:
获取导致页缺失异常的虚拟内存地址,保存到 address 变量中。
调用 find_vma 函数从进程内存分区中查找异常的虚拟内存地址对应的内存分区对象。
如果找到内存分区对象,那么调用 handle_mm_fault 函数对虚拟内存地址进行映射操作。
从上面的分析可知,对虚拟内存进行映射操作是通过 handle_mm_fault 函数完成的,而 handle_mm_fault 函数的主要工作就是完成对进程 页表 的填充。
我们通过 图3 来理解内存映射的原理,可以参考文章《一文读懂 HugePages的原理》:
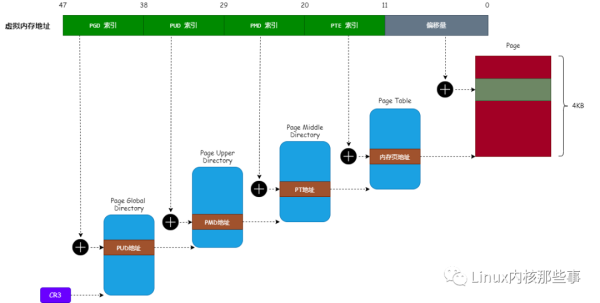
下面我们来分析一下 handle_mm_fault 的实现,代码如下:
int handle_mm_fault(struct mm_struct *mm, struct vm_area_struct *vma, unsigned long address, unsigned int flags) { pgd_t *pgd; // 页全局目录项 pud_t *pud; // 页上级目录项 pmd_t *pmd; // 页中间目录项 pte_t *pte; // 页表项 ... pgd = pgd_offset(mm, address); // 获取虚拟内存地址对应的页全局目录项 pud = pud_alloc(mm, pgd, address); // 获取虚拟内存地址对应的页上级目录项 ... pmd = pmd_alloc(mm, pud, address); // 获取虚拟内存地址对应的页中间目录项 ... pte = pte_alloc_map(mm, pmd, address); // 获取虚拟内存地址对应的页表项 ... // 对页表项进行映射 return handle_pte_fault(mm, vma, address, pte, pmd, flags); 18}handle_mm_fault 函数主要对每一级的页表进行映射(对照 图3 就容易理解),最终调用 handle_pte_fault 函数对 页表项 进行映射。
我们继续来分析 handle_pte_fault 函数的实现,代码如下:
static inline int handle_pte_fault(struct mm_struct *mm, struct vm_area_struct *vma, unsigned long address, pte_t *pte, pmd_t *pmd, unsigned int flags) { pte_t entry; entry = *pte; if (!pte_present(entry)) { // 还没有映射到物理内存 if (pte_none(entry)) { ... // 调用 do_anonymous_page 函数进行匿名页映射(堆空间就是使用匿名页) return do_anonymous_page(mm, vma, address, pte, pmd, flags); } ... } ... }上面代码简化了很多与本文无关的逻辑。从上面代码可以看出,handle_pte_fault 函数最终会调用 do_anonymous_page 来完成内存映射操作,我们接着来分析下 do_anonymous_page 函数的实现:
static int do_anonymous_page(struct mm_struct *mm, struct vm_area_struct *vma, unsigned long address, pte_t *page_table, pmd_t *pmd, unsigned int flags) { struct page *page; spinlock_t *ptl; pte_t entry; if (!(flags & FAULT_FLAG_WRITE)) { // 如果是读操作导致的异常 // 使用 `零页` 进行映射 entry = pte_mkspecial(pfn_pte(my_zero_pfn(address), vma->vm_page_prot)); ... goto setpte; } ... // 如果是写操作导致的异常 // 申请一块新的物理内存页 page = alloc_zeroed_user_highpage_movable(vma, address); ... // 根据物理内存页的地址生成映射关系 entry = mk_pte(page, vma->vm_page_prot); if (vma->vm_flags & VM_WRITE) entry = pte_mkwrite(pte_mkdirty(entry)); ... setpte: set_pte_at(mm, address, page_table, entry); // 设置页表项为新的映射关系 ... return 0; }do_anonymous_page 函数的实现比较有趣,它会根据 缺页异常 是由读操作还是写操作导致的,分为两个不同的处理逻辑,如下:
如果是读操作导致的,那么将会使用 零页 进行映射(零页 是 Linux 内核中一个比较特殊的内存页,所有读操作引起的 缺页异常 都会指向此页,从而可以减少物理内存的消耗),并且设置其为只读(因为 零页 是不能进行写操作)。如果下次对此页进行写操作,将会触发写操作的 缺页异常,从而进入下面步骤。
如果是写操作导致的,就申请一块新的物理内存页,然后根据物理内存页的地址生成映射关系,再对页表项进行填充(映射)。
感谢各位的阅读,以上就是“Linux内存分配的详细过程”的内容了,经过本文的学习后,相信大家对Linux内存分配的详细过程这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://mp.weixin.qq.com/s/mphzuIqqBYecry0psTsbxQ



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



