这篇文章主要讲解了“如何用Python爬取百度搜索结果并保存”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“如何用Python爬取百度搜索结果并保存”吧!
一、前言
众所周知,百度上直接搜索关键字会出来一大堆东西,时常还会伴随有广告出现,不小心就点进去了,还得花时间退出来,有些费劲。
最近群里有个小伙伴提出一个需求,需要获取百度上关于粮食的相关讲话文章标题和链接。正好小编最近在学习爬虫,就想着拿这个需求来练练手。我们都知道,对Python来说,有大量可用的库,实现起来并不难,动手吧。
二、项目目标
爬取百度上关键字为“粮食”的搜索结果,并保存,提交给客户,用于进一步分析我国粮食政策。
三、项目准备
软件:PyCharm
需要的库:json, requests,etree
四、项目分析
1)如何进行关键词搜索?
利用response库,直接Get网址获得搜索结果。网址如下:
https://www.baidu.com/s?wd=粮食
2)如何获取标题和链接?
利用etree对原代码进行规范梳理后,通过Xpath定位到文章标题和href,获取标题和文章链接。
3)如何保存搜索结果?
新建txt文件,对搜索结果循环写入,保存即可。
五、项目实现
1、第一步导入需要的库
import json import requests from lxml import etree2、第二步用requests进行请求搜索
headers = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36" } response = requests.get('https://www.baidu.com/s?wd=粮食&lm=1', headers=headers)3、第三步对获取的源代码进行整理分析,通过Xpath定位需要的资源
r = response.text html = etree.HTML(r, etree.HTMLParser()) r1 = html.xpath('//h4') r2 = html.xpath('//*[@class="c-abstract"]') r3 = html.xpath('//*[@class="t"]/a/@href')4、第四步把有用资源循环读取保存
for i in range(10): r11 = r1[i].xpath('string(.)') r22 = r2[i].xpath('string(.)') r33 = r3[i] with open('ok.txt', 'a', encoding='utf-8') as c: c.write(json.dumps(r11,ensure_ascii=False) + '\n') c.write(json.dumps(r22, ensure_ascii=False) + '\n') c.write(json.dumps(r33, ensure_ascii=False) + '\n') print(r11, end='\n') print('------------------------') print(r22, end='\n') print(r33)六、效果展示
1、程序运行结果,如下图所示:
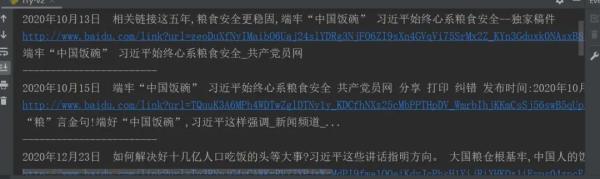
2、保存为txt的文件最终结果如下图所示:

七、总结
本文介绍了如何利用Python对百度搜索结果进行爬取、保存,是一个小爬虫,这也是Python好玩的地方,有大量免费的库可用,能帮你实现各种需求。工作量大,学会用Python!
感谢各位的阅读,以上就是“如何用Python爬取百度搜索结果并保存”的内容了,经过本文的学习后,相信大家对如何用Python爬取百度搜索结果并保存这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务


