本篇内容主要讲解“怎么使用Python自然语言处理NLP创建摘要”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“怎么使用Python自然语言处理NLP创建摘要”吧!
应该使用哪种总结方法
我使用提取摘要,因为我可以将此方法应用于许多文档,而不必执行大量(令人畏惧)的机器学习模型训练任务。
此外,提取摘要法比抽象摘要具有更好的总结效果,因为抽象摘要必须从原文中生成新的句子,这是一种比数据驱动的方法提取重要句子更困难的方法。
如何创建自己的文本摘要器
我们将使用单词直方图来对句子的重要性进行排序,然后创建一个总结。这样做的好处是,你不需要训练你的模型来将其用于文档。
文本摘要工作流
下面是我们将要遵循的工作流…
导入文本>>>>清理文本并拆分成句子>>删除停用词>>构建单词直方图>>排名句子>>选择前N个句子进行提取摘要
(1) 示例文本
我用了一篇新闻文章的文本,标题是苹果以5000万美元收购AI初创公司,以推进其应用程序。你可以在这里找到原始的新闻文章:https://analyticsindiamag.com/apple-acquires-ai-startup-for-50-million-to-advance-its-apps/
你还可以从Github下载文本文档:https://github.com/louisteo9/personal-text-summarizer
(2) 导入库
# 自然语言工具包(NLTK) import nltk nltk.download('stopwords') # 文本预处理的正则表达式 import re # 队列算法求首句 import heapq # 数值计算的NumPy import numpy as np # 用于创建数据帧的pandas import pandas as pd # matplotlib绘图 from matplotlib import pyplot as plt %matplotlib inline(3) 导入文本并执行预处理
有很多方法可以做到。这里的目标是有一个干净的文本,我们可以输入到我们的模型中。
# 加载文本文件 with open('Apple_Acquires_AI_Startup.txt', 'r') as f: file_data = f.read()这里,我们使用正则表达式来进行文本预处理。我们将
(A)用空格(如果有的话…)替换参考编号,即[1]、[10]、[20],
(B)用单个空格替换一个或多个空格。
text = file_data # 如果有,请用空格替换 text = re.sub(r'\[[0-9]*\]',' ',text) # 用单个空格替换一个或多个空格 text = re.sub(r'\s+',' ',text)然后,我们用小写(不带特殊字符、数字和额外空格)形成一个干净的文本,并将其分割成单个单词,用于词组分数计算和构词直方图。
形成一个干净文本的原因是,算法不会把“理解”和“理解”作为两个不同的词来处理。
# 将所有大写字符转换为小写字符 clean_text = text.lower() # 用空格替换[a-zA-Z0-9]以外的字符 clean_text = re.sub(r'\W',' ',clean_text) # 用空格替换数字 clean_text = re.sub(r'\d',' ',clean_text) # 用单个空格替换一个或多个空格 clean_text = re.sub(r'\s+',' ',clean_text)(4) 将文本拆分为句子
我们使用NLTK sent_tokenize方法将文本拆分为句子。我们将评估每一句话的重要性,然后决定是否应该将每一句都包含在总结中。
sentences = nltk.sent_tokenize(text)(5) 删除停用词
停用词是指不给句子增加太多意义的英语单词。他们可以安全地被忽略,而不牺牲句子的意义。我们已经下载了一个文件,其中包含英文停用词
这里,我们将得到停用词的列表,并将它们存储在stop_word 变量中。
# 获取停用词列表 stop_words = nltk.corpus.stopwords.words('english')(6) 构建直方图
让我们根据每个单词在整个文本中出现的次数来评估每个单词的重要性。
我们将通过(1)将单词拆分为干净的文本,(2)删除停用词,然后(3)检查文本中每个单词的频率。
# 创建空字典以容纳单词计数 word_count = {} # 循环遍历标记化的单词,删除停用单词并将单词计数保存到字典中 for word in nltk.word_tokenize(clean_text): # remove stop words if word not in stop_words: # 将字数保存到词典 if word not in word_count.keys(): word_count[word] = 1 else: word_count[word] += 1让我们绘制单词直方图并查看结果。
plt.figure(figsize=(16,10)) plt.xticks(rotation = 90) plt.bar(word_count.keys(), word_count.values()) plt.show()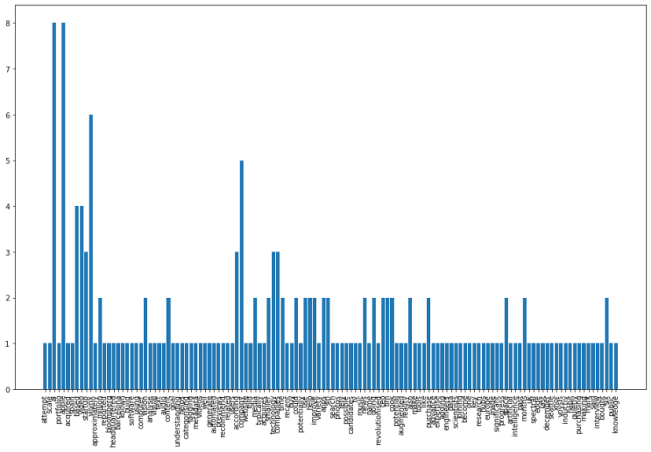
让我们把它转换成横条图,只显示前20个单词,下面有一个helper函数。
# helper 函数,用于绘制最上面的单词。 def plot_top_words(word_count_dict, show_top_n=20): word_count_table = pd.DataFrame.from_dict(word_count_dict, orient = 'index').rename(columns={0: 'score'}) word_count_table.sort_values(by='score').tail(show_top_n).plot(kind='barh', figsize=(10,10)) plt.show()让我们展示前20个单词。
plot_top_words(word_count, 20)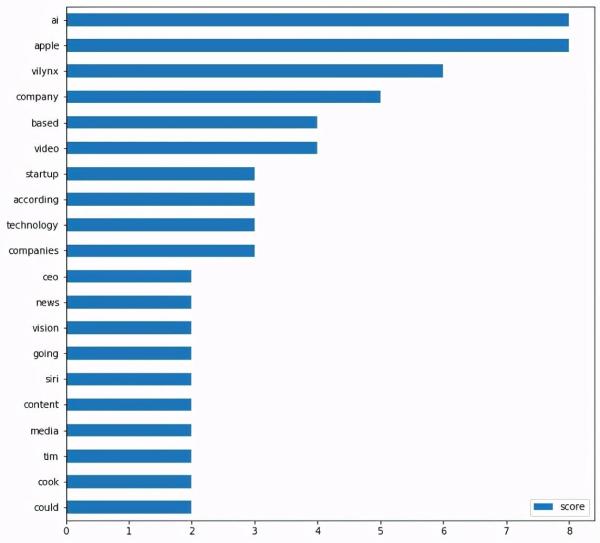
从上面的图中,我们可以看到“ai”和“apple”两个词出现在顶部。这是有道理的,因为这篇文章是关于苹果收购一家人工智能初创公司的。
(7) 根据分数排列句子
现在,我们将根据句子得分对每个句子的重要性进行排序。我们将:
删除超过30个单词的句子,认识到长句未必总是有意义的;
然后,从构成句子的每个单词中加上分数,形成句子分数。
高分的句子将排在前面。前面的句子将形成我们的总结。
注意:根据我的经验,任何25到30个单词都可以给你一个很好的总结。
# 创建空字典来存储句子分数 sentence_score = {} # 循环通过标记化的句子,只取少于30个单词的句子,然后加上单词分数来形成句子分数 for sentence in sentences: # 检查句子中的单词是否在字数字典中 for word in nltk.word_tokenize(sentence.lower()): if word in word_count.keys(): # 只接受少于30个单词的句子 if len(sentence.split(' ')) < 30: # 把单词分数加到句子分数上 if sentence not in sentence_score.keys(): sentence_score[sentence] = word_count[word] else: sentence_score[sentence] += word_count[word]我们将句子-分数字典转换成一个数据框,并显示sentence_score。
注意:字典不允许根据分数对句子进行排序,因此需要将字典中存储的数据转换为DataFrame。
df_sentence_score = pd.DataFrame.from_dict(sentence_score, orient = 'index').rename(columns={0: 'score'}) df_sentence_score.sort_values(by='score', ascending = False)
(8) 选择前面的句子作为摘要
我们使用堆队列算法来选择前3个句子,并将它们存储在best_quences变量中。
通常3-5句话就足够了。根据文档的长度,可以随意更改要显示的最上面的句子数。
在本例中,我选择了3,因为我们的文本相对较短。
# 展示最好的三句话作为总结 best_sentences = heapq.nlargest(3, sentence_score, key=sentence_score.get)让我们使用print和for loop函数显示摘要文本。
print('SUMMARY') print('------------------------') # 根据原文中的句子顺序显示最上面的句子 for sentence in sentences: if sentence in best_sentences: print (sentence)到此,相信大家对“怎么使用Python自然语言处理NLP创建摘要”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://www.toutiao.com/a6893880620808667660/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



