本篇文章为大家展示了Python中怎么利用seaborn实现数据可视化,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
本文目标图表是这样:
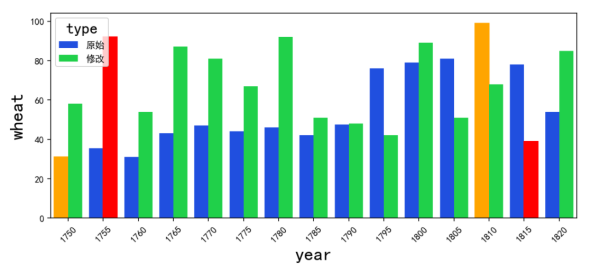
2个系列。每个系列找出最小最大的柱子,标记成不同的颜色
本文所需要的库如下:

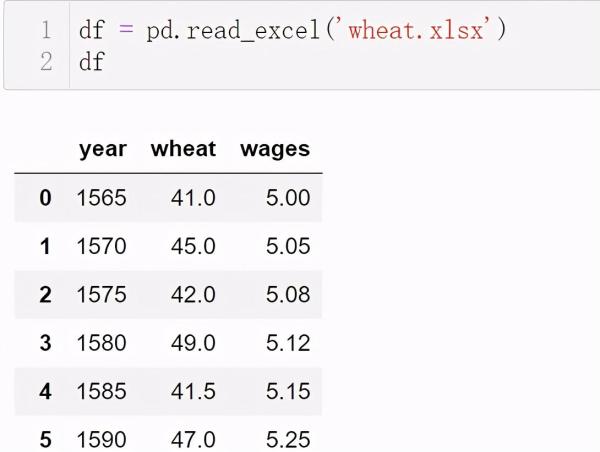
数据是这样子:
上一节做的事情如下:
设置 x 轴标签的旋转角度
设置某个指定柱状图的柱子颜色
简单把这些事情包装成函数:

使用 seaborn 的代码,实际与上一节直接使用 matplotlib 差不多:

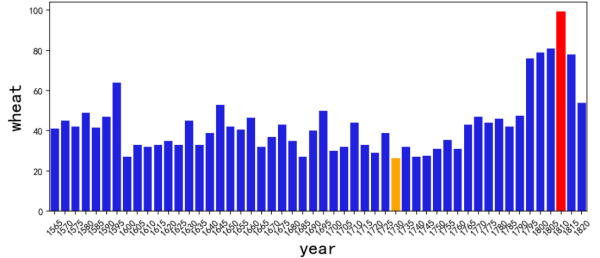
看起来 seaborn 没有特别的地方!
这是因为我们只有一个系列(上图只涉及2个维度:wheat 与 year)
多系列
稍微修改一下数据,

行3、4、5:复制一份数据,小麦产量随机生成
行7、8:新增一个列"type",把数据划分成2类:"原始" 、"修改"
行10:合并成一份数据
行12:避免数据太多,图表不利于阅读,我只保留1750年以后的数据
现在数据成这样:
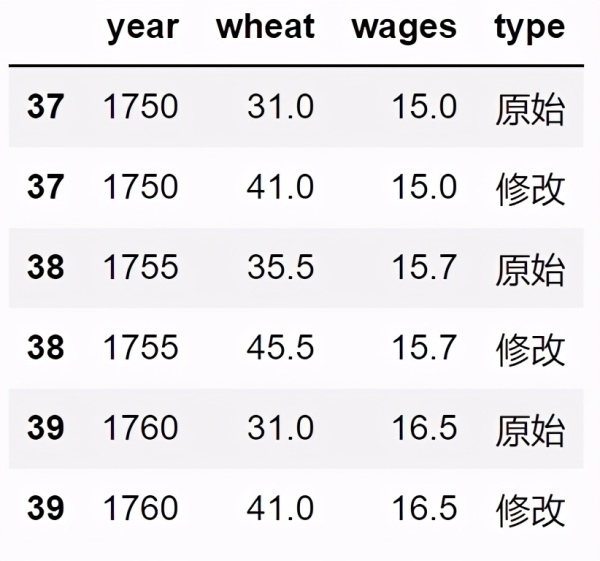
每个年份都有2行记录,字段"type"可以区分他们
使用 seaborn 可以非常方便映射多个维度的数据:

行1:hue 是类别映射,通常如果有一个列数据是文本,就可以映射上去。这里把数据中的"type"字段映射
图表成这样子:
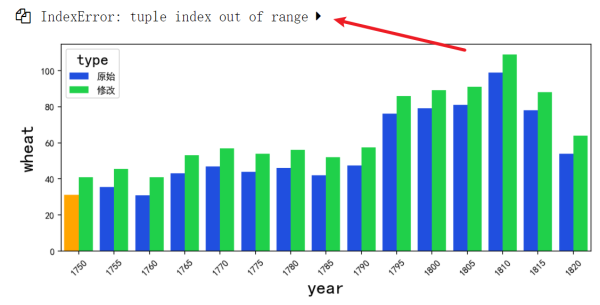
显然没有标记出最大值的柱子
同时也提示执行有错误
如果我们查看图表的容器就能看出关键:

原来,seaborn 柱子分成2组。这是非常合理的
但数据范围索引,却是在整个数据共27行中查找
显然,我们需要是2组的范围索引:

语义非常清晰直白
但是,怎么准确从图表容器中找到需要的 BarContainer:
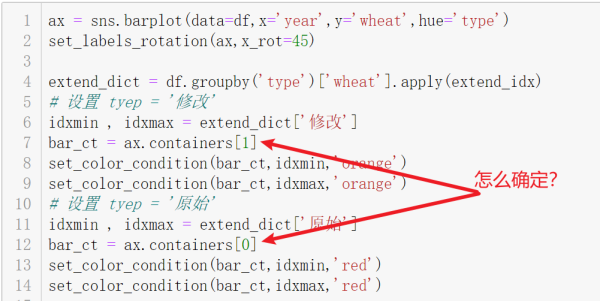
行7与行12:里面的 0 和 1 都是猜测的
原来,seaborn 在生成这些容器时,给容器的 label 属性写入了对应的数据值(就是我们数据的"type"字段):

注意,你不能使用 key 索引方式获取,比如写: axcontainers['修改'] ,这会报错
万事俱备,定义如下函数:

现在调用变得非常简单:

图表成这样子:
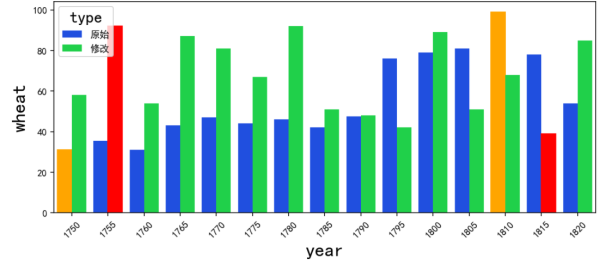
上述内容就是Python中怎么利用seaborn实现数据可视化,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://www.toutiao.com/a6889264224233751043/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



