本篇内容主要讲解“怎么从无序链表中移除重复项”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“怎么从无序链表中移除重复项”吧!
顺序删除
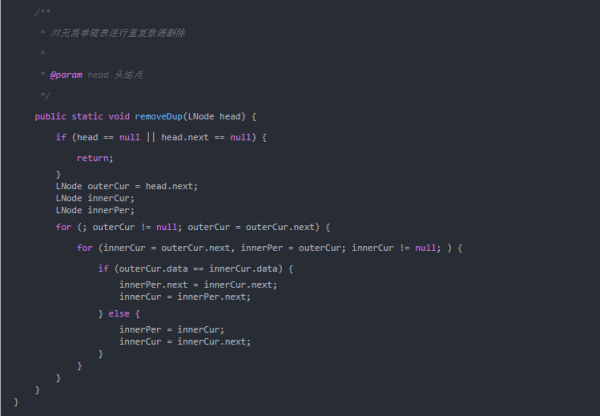
通过双重循环直接在链表上执行删除操作。外层循环用一个指针从第一个结点开始遍历整个链表,然后内层循环用另外一个指针遍历其余结点,将与外层循环遍历到的指针所指结点的数据域相同的结点删除,如下图所示。
假设外层循环从outerCur开始遍历,当内层循环指针innerCur遍历到上图实线所示的位置(outerCur.data==innerCur.data)时,此时需要把innerCur指向的结点删除。
具体步骤如下:
用tmp记录待删除的结点的地址。
为了能够在删除tmp结点后继续遍历链表中其余的结点,使innerCur指针指向它的后继结点:innerCur=innerCur.next。
从链表中删除tmp结点。
实现代码如下:

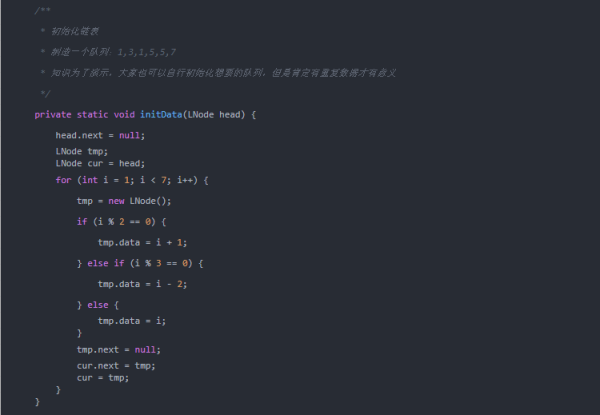
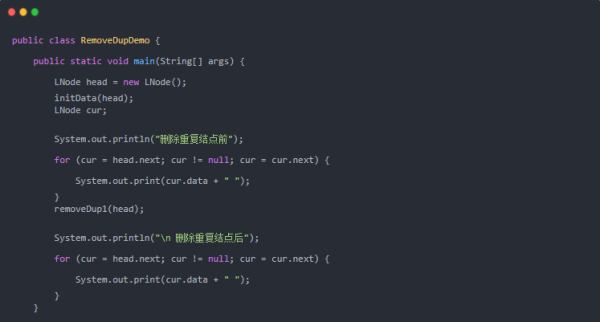
运行结果:
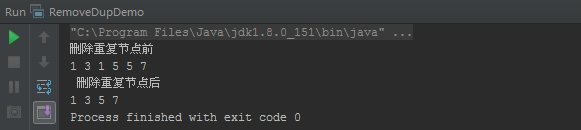
算法性能分析
由于这种方法采用双重循环对链表进行遍历,因此,时间复杂度为O(N^2)。其中,N为链表的长度。在遍历链表的过程中,使用了常量个额外的指针变量来保存当前遍历的结点、前驱结点和被删除的结点,因此,空间复杂度为O(1)。
递归法
主要思路为:对于结点cur,首先递归地删除以cur.next为首的子链表中重复的结点,接着从以cur.next为首的子链表中找出与cur有着相同数据域的结点并删除。
实现代码如下:

算法性能分析
这种方法与方法一类似,从本质上而言,由于这种方法需要对链表进行双重遍历,因此,时间复杂度为O(N^2)。其中,N为链表的长度。由于递归法会增加许多额外的函数调用,因此,从理论上讲,该方法效率比前面的方法低。
空间换时间
通常情况下,为了降低时间复杂度,往往在条件允许的情况下,通过使用辅助空间实现。
具体而言,主要思路如下。
建立一个HashSet,HashSet中的内容为已经遍历过的结点内容,并将其初始化为空。
从头开始遍历链表中的所以结点,存在以下两种可能性:
如果结点内容已经在HashSet中,则删除此结点,继续向后遍历。
如果结点内容不在HashSet中,则保留此结点,将此结点内容添加到HashSet中,继续向后遍历。
「引申:如何从有序链表中移除重复项?」
如链表:1,3、5、5、7、7、8、9
去重后:1,3、5、7、8、9
分析与解答
上述介绍的方法也适用于链表有序的情况,但是由于以上方法没有充分利用到链表有序这个条件,因此,算法的性能肯定不是最优的。本题中,由于链表具有有序性,因此,不需要对链表进行两次遍历。所以,有如下思路:用cur 指向链表第一个结点,此时需要分为以下两种情况讨论。
如果cur.data==cur.next.data,那么删除cur.next结点。
如果cur.data!=cur.next.data,那么cur=cur.next,继续遍历其余结点。
到此,相信大家对“怎么从无序链表中移除重复项”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://mp.weixin.qq.com/s/jmDNAtMYBUvj7H40NhMeuQ



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



