本篇文章给大家分享的是有关怎么理解Linux的Cache和Buffer,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
首先说明,本文讨论的cache指的是Linux中的page cache,buffer指的是buffer cache,也即cat /proc/meminfo中显示的cache和buffer。
我们知道,Linux下频繁存取文件或单个大文件时物理内存会很快被用光,当程序结束后内存不会被正常释放而是一直作为cahce占着内存。因此系统经常会因为这点导致OOM产生,尤其在等大压力场景下概率较高,此时,第一时间查看cache和buffer内存是非常高的。此类问题目前尚未有一个很好的解决方案,以往遇到大多会做规避处理,因此本案尝试给出一个分析和解决的思路。
解决该问题的关键是理解什么是cache和buffer,什么时候消耗在哪里以及如何控制cache和buffer,所以本问主要围绕这几点展开。整个讨论过程尽量先从内核源码分析入手,然后提炼APP相关接口并进行实际操作验证,最后总结给出应用程序的编程建议。
可以通过free或者cat /proc/meminfo查看到系统的buffer和cache情况。
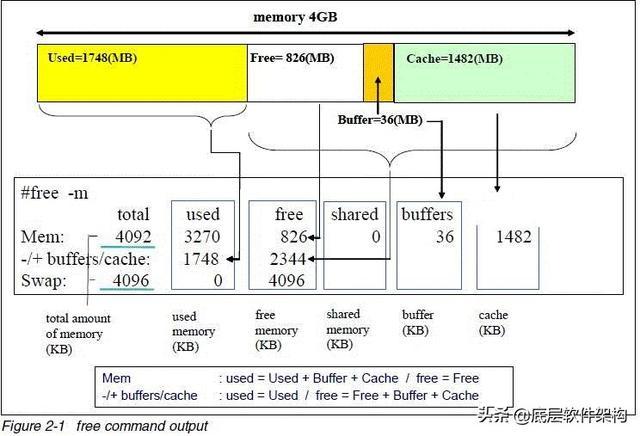
free命令的全解析
1. Cache和Buffer分析
从cat /proc/meminfo入手,先看看该接口的实现:
static int meminfo_proc_show(struct seq_file *m, void *v) { …… cached = global_page_state(NR_FILE_PAGES) - total_swapcache_pages() - i.bufferram; if (cached < 0) cached = 0; …… seq_printf(m, "MemTotal: %8lu kB\n" "MemFree: %8lu kB\n" "Buffers: %8lu kB\n" "Cached: %8lu kB\n" …… , K(i.totalram), K(i.freeram), K(i.bufferram), K(cached), …… ); …… }其中,内核中以页框为单位,通过宏K转化成以KB为单位输出。这些值是通过si_meminfo来获取的:
void si_meminfo(struct sysinfo *val) { val->totalram = totalram_pages; val->sharedram = 0; val->freeram = global_page_state(NR_FREE_PAGES); val->bufferram = nr_blockdev_pages(); val->totalhigh = totalhigh_pages; val->freehigh = nr_free_highpages(); val->mem_unit = PAGE_SIZE; }其中bufferram来自于nr_blockdev_pages(),该函数计算块设备使用的页框数,遍历所有块设备,将使用的页框数相加。而不包含普通文件使用的页框数。
long nr_blockdev_pages(void) { struct block_device *bdev; long ret = 0; spin_lock(&bdev_lock); list_for_each_entry(bdev, &all_bdevs, bd_list) { ret += bdev->bd_inode->i_mapping->nrpages; } spin_unlock(&bdev_lock); return ret; }从以上得出meminfo中cache和buffer的来源:
Buffer就是块设备占用的页框数量;
Cache的大小为内核总的page cache减去swap cache和块设备占用的页框数量,实际上cache即为普通文件的占用的page cache。
通过内核代码分析(这里略过复杂的内核代码分析),虽然两者在实现上差别不是很大,都是通过address_space对象进行管理的,但是page cache是对文件数据的缓存而buffer cache是对块设备数据的缓存。对于每个块设备都会分配一个def_blk_ops的文件操作方法,这是设备的操作方法,在每个块设备的inode(bdev伪文件系统的inode)下面会存在一个radix tree,这个radix tree下面将会放置缓存数据的page页。这个page的数量将会在cat /proc/meminfobuffer一栏中显示。也就是在没有文件系统的情况下,采用dd等工具直接对块设备进行操作的数据会缓存到buffer cache中。如果块设备做了文件系统,那么文件系统中的文件都有一个inode,这个inode会分配ext3_ops之类的操作方法,这些方法是文件系统的方法,在这个inode下面同样存在一个radix tree,这里也会缓存文件的page页,缓存页的数量在cat /proc/meminfo的cache一栏进行统计。此时对文件操作,那么数据大多会缓存到page cache,不多的是文件系统文件的元数据会缓存到buffer cache。
这里,我们使用cp命令拷贝一个50MB的文件操作,内存会发生什么变化:
[root nfs_dir] # ll -h file_50MB.bin -rw-rw-r-- 1 4104 4106 50.0M Feb 24 2016 file_50MB.bin [root nfs_dir] # cat /proc/meminfo MemTotal: 90532 kB MemFree: 65696 kB Buffers: 0 kB Cached: 8148 kB …… [root@test nfs_dir] # cp file_50MB.bin / [root@test nfs_dir] # cat /proc/meminfo MemTotal: 90532 kB MemFree: 13012 kB Buffers: 0 kB Cached: 60488 kB
可以看到cp命令前后,MemFree从65696 kB减少为13012 kB,Cached从8148 kB增大为60488 kB,而Buffers却不变。那么过一段时间,Linux会自动释放掉所用的cache内存吗?一个小时后查看proc/meminfo显示cache仍然没有变化。
接着,我们看下使用dd命令对块设备写操作前后的内存变化:
[0225_19:10:44:10s][root@test nfs_dir] # cat /proc/meminfo [0225_19:10:44:10s]MemTotal: 90532 kB [0225_19:10:44:10s]MemFree: 58988 kB [0225_19:10:44:10s]Buffers: 0 kB [0225_19:10:44:10s]Cached: 4144 kB ...... ...... [0225_19:11:13:11s][root@test nfs_dir] # dd if=/dev/zero of=/dev/h_sda bs=10M count=2000 & [0225_19:11:17:11s][root@test nfs_dir] # cat /proc/meminfo [0225_19:11:17:11s]MemTotal: 90532 kB [0225_19:11:17:11s]MemFree: 11852 kB [0225_19:11:17:11s]Buffers: 36224 kB [0225_19:11:17:11s]Cached: 4148 kB ...... ...... [0225_19:11:21:11s][root@test nfs_dir] # cat /proc/meminfo [0225_19:11:21:11s]MemTotal: 90532 kB [0225_19:11:21:11s]MemFree: 11356 kB [0225_19:11:21:11s]Buffers: 36732 kB [0225_19:11:21:11s]Cached: 4148kB ...... ...... [0225_19:11:41:11s][root@test nfs_dir] # cat /proc/meminfo [0225_19:11:41:11s]MemTotal: 90532 kB [0225_19:11:41:11s]MemFree: 11864 kB [0225_19:11:41:11s]Buffers: 36264 kB [0225_19:11:41:11s]Cached: 4148 kB ….. ……
裸写块设备前Buffs为0,裸写硬盘过程中每隔一段时间查看内存信息发现Buffers一直在增加,空闲内存越来越少,而Cached数量一直保持不变。
总结:
通过代码分析及实际操作,我们理解了buffer cache和page cache都会占用内存,但也看到了两者的差别。page cache针对文件的cache,buffer是针对块设备数据的cache。Linux在可用内存充裕的情况下,不会主动释放page cache和buffer cache。
2. 使用posix_fadvise控制Cache
在Linux中文件的读写一般是通过buffer io方式,以便充分利用到page cache。
Buffer IO的特点是读的时候,先检查页缓存里面是否有需要的数据,如果没有就从设备读取,返回给用户的同时,加到缓存一份;写的时候,直接写到缓存去,再由后台的进程定期刷到磁盘去。这样的机制看起来非常的好,实际也能提高文件读写的效率。
但是当系统的IO比较密集时,就会出问题。当系统写的很多,超过了内存的某个上限时,后台的回写线程就会出来回收页面,但是一旦回收的速度小于写入的速度,就会触发OOM。最关键的是整个过程由内核参与,用户不好控制。
那么到底如何才能有效的控制cache呢?
目前主要由两种方法来规避风险:
走direct io;
走buffer io,但是定期清除无用page cache;
这里当然讨论的是第二种方式,即在buffer io方式下如何有效控制page cache。
在程序中只要知道文件的句柄,就能用:
int posix_fadvise(int fd, off_t offset, off_t len, int advice);
POSIX_FADV_DONTNEED (该文件在接下来不会再被访问),但是曾有开发人员反馈怀疑该接口的有效性。那么该接口确实有效吗?首先,我们查看mm/fadvise.c内核代码来看posix_fadvise是如何实现的:
/* * POSIX_FADV_WILLNEED could set PG_Referenced, and POSIX_FADV_NOREUSE could * deactivate the pages and clear PG_Referenced. */ SYSCALL_DEFINE4(fadvise64_64, int, fd, loff_t, offset, loff_t, len, int, advice) { … … … … /* => 将指定范围内的数据从page cache中换出 */ case POSIX_FADV_DONTNEED: /* => 如果后备设备不忙的话,先调用__filemap_fdatawrite_range把脏页面刷掉 */ if (!bdi_write_congested(mapping->backing_dev_info)) /* => WB_SYNC_NONE: 不是同步等待页面刷新完成,只是提交了 */ /* => 而fsync和fdatasync是用WB_SYNC_ALL参数等到完成才返回的 */ __filemap_fdatawrite_range(mapping, offset, endbyte, WB_SYNC_NONE); /* First and last FULL page! */ start_index = (offset+(PAGE_CACHE_SIZE-1)) >> PAGE_CACHE_SHIFT; end_index = (endbyte >> PAGE_CACHE_SHIFT); /* => 接下来清除页面缓存 */ if (end_index >= start_index) { unsigned long count = invalidate_mapping_pages(mapping, start_index, end_index); /* * If fewer pages were invalidated than expected then * it is possible that some of the pages were on * a per-cpu pagevec for a remote CPU. Drain all * pagevecs and try again. */ if (count < (end_index - start_index + 1)) { lru_add_drain_all(); invalidate_mapping_pages(mapping, start_index, end_index); } } break; … … … … }我们可以看到如果后台系统不忙的话,会先调用__filemap_fdatawrite_range把脏页面刷掉,刷页面用的参数是是 WB_SYNC_NONE,也就是说不是同步等待页面刷新完成,提交完写脏页后立即返回了。
然后再调invalidate_mapping_pages清除页面,回收内存:
/* => 清除缓存页(除了脏页、上锁的、正在回写的或映射在页表中的)*/ unsigned long invalidate_mapping_pages(struct address_space *mapping, pgoff_t start, pgoff_t end) { struct pagevec pvec; pgoff_t index = start; unsigned long ret; unsigned long count = 0; int i; /* * Note: this function may get called on a shmem/tmpfs mapping: * pagevec_lookup() might then return 0 prematurely (because it * got a gangful of swap entries); but it's hardly worth worrying * about - it can rarely have anything to free from such a mapping * (most pages are dirty), and already skips over any difficulties. */ pagevec_init(&pvec, 0); while (index <= end && pagevec_lookup(&pvec, mapping, index, min(end - index, (pgoff_t)PAGEVEC_SIZE - 1) + 1)) { mem_cgroup_uncharge_start(); for (i = 0; i < pagevec_count(&pvec); i++) { struct page *page = pvec.pages[i]; /* We rely upon deletion not changing page->index */ index = page->index; if (index > end) break; if (!trylock_page(page)) continue; WARN_ON(page->index != index); /* => 无效一个文件的缓存 */ ret = invalidate_inode_page(page); unlock_page(page); /* * Invalidation is a hint that the page is no longer * of interest and try to speed up its reclaim. */ if (!ret) deactivate_page(page); count += ret; } pagevec_release(&pvec); mem_cgroup_uncharge_end(); cond_resched(); index++; } return count; } /* * Safely invalidate one page from its pagecache mapping. * It only drops clean, unused pages. The page must be locked. * * Returns 1 if the page is successfully invalidated, otherwise 0. */ /* => 无效一个文件的缓存 */ int invalidate_inode_page(struct page *page) { struct address_space *mapping = page_mapping(page); if (!mapping) return 0; /* => 若当前页是脏页或正在写回的页,直接返回 */ if (PageDirty(page) || PageWriteback(page)) return 0; /* => 若已经被映射到页表了,则直接返回 */ if (page_mapped(page)) return 0; /* => 如果满足了以上条件就调用invalidate_complete_page继续 */ return invalidate_complete_page(mapping, page); } 从上面的代码可以看到清除相关的页面要满足二个条件: 1. 不脏且没在回写; 2. 未被使用。如果满足了这二个条件就调用invalidate_complete_page继续: /* => 无效一个完整的页 */ static int invalidate_complete_page(struct address_space *mapping, struct page *page) { int ret; if (page->mapping != mapping) return 0; if (page_has_private(page) && !try_to_release_page(page, 0)) return 0; /* => 若满足以上更多条件,则从地址空间中解除该页 */ ret = remove_mapping(mapping, page); return ret; } /* * Attempt to detach a locked page from its ->mapping. If it is dirty or if * someone else has a ref on the page, abort and return 0. If it was * successfully detached, return 1. Assumes the caller has a single ref on * this page. */ /* => 从地址空间中解除该页 */ int remove_mapping(struct address_space *mapping, struct page *page) { if (__remove_mapping(mapping, page)) { /* * Unfreezing the refcount with 1 rather than 2 effectively * drops the pagecache ref for us without requiring another * atomic operation. */ page_unfreeze_refs(page, 1); return 1; } return 0; } /* * Same as remove_mapping, but if the page is removed from the mapping, it * gets returned with a refcount of 0. */ /* => 从地址空间中解除该页 */ static int __remove_mapping(struct address_space *mapping, struct page *page) { BUG_ON(!PageLocked(page)); BUG_ON(mapping != page_mapping(page)); spin_lock_irq(&mapping->tree_lock); /* * The non racy check for a busy page. * * Must be careful with the order of the tests. When someone has * a ref to the page, it may be possible that they dirty it then * drop the reference. So if PageDirty is tested before page_count * here, then the following race may occur: * * get_user_pages(&page); * [user mapping goes away] * write_to(page); * !PageDirty(page) [good] * SetPageDirty(page); * put_page(page); * !page_count(page) [good, discard it] * * [oops, our write_to data is lost] * * Reversing the order of the tests ensures such a situation cannot * escape unnoticed. The smp_rmb is needed to ensure the page->flags * load is not satisfied before that of page->_count. * * Note that if SetPageDirty is always performed via set_page_dirty, * and thus under tree_lock, then this ordering is not required. */ if (!page_freeze_refs(page, 2)) goto cannot_free; /* note: atomic_cmpxchg in page_freeze_refs provides the smp_rmb */ if (unlikely(PageDirty(page))) { page_unfreeze_refs(page, 2); goto cannot_free; } if (PageSwapCache(page)) { swp_entry_t swap = { .val = page_private(page) }; __delete_from_swap_cache(page); spin_unlock_irq(&mapping->tree_lock); swapcache_free(swap, page); } else { void (*freepage)(struct page *); freepage = mapping->a_ops->freepage; /* => 从页缓存中删除和释放该页 */ __delete_from_page_cache(page); spin_unlock_irq(&mapping->tree_lock); mem_cgroup_uncharge_cache_page(page); if (freepage != NULL) freepage(page); } return 1; cannot_free: spin_unlock_irq(&mapping->tree_lock); return 0; } /* * Delete a page from the page cache and free it. Caller has to make * sure the page is locked and that nobody else uses it - or that usage * is safe. The caller must hold the mapping's tree_lock. */ /* => 从页缓存中删除和释放该页 */ void __delete_from_page_cache(struct page *page) { struct address_space *mapping = page->mapping; trace_mm_filemap_delete_from_page_cache(page); /* * if we're uptodate, flush out into the cleancache, otherwise * invalidate any existing cleancache entries. We can't leave * stale data around in the cleancache once our page is gone */ if (PageUptodate(page) && PageMappedToDisk(page)) cleancache_put_page(page); else cleancache_invalidate_page(mapping, page); radix_tree_delete(&mapping->page_tree, page->index); /* => 解除与之绑定的地址空间结构 */ page->mapping = NULL; /* Leave page->index set: truncation lookup relies upon it */ /* => 减少地址空间中的页计数 */ mapping->nrpages--; __dec_zone_page_state(page, NR_FILE_PAGES); if (PageSwapBacked(page)) __dec_zone_page_state(page, NR_SHMEM); BUG_ON(page_mapped(page)); /* * Some filesystems seem to re-dirty the page even after * the VM has canceled the dirty bit (eg ext3 journaling). * * Fix it up by doing a final dirty accounting check after * having removed the page entirely. */ if (PageDirty(page) && mapping_cap_account_dirty(mapping)) { dec_zone_page_state(page, NR_FILE_DIRTY); dec_bdi_stat(mapping->backing_dev_info, BDI_RECLAIMABLE); } }看到这里我们就明白了:为什么使用了posix_fadvise后相关的内存没有被释放出来:页面还脏是最关键的因素。
但是我们如何保证页面全部不脏呢?fdatasync或者fsync都是选择,或者Linux下新系统调用sync_file_range都是可用的,这几个都是使用WB_SYNC_ALL模式强制要求回写完毕才返回的。所以应该这样做:
fdatasync(fd); posix_fadvise(fd, 0, 0, POSIX_FADV_DONTNEED);
总结:
使用posix_fadvise可以有效的清除page cache,作用范围为文件级。下面给出应用程序编程建议:
用于测试I/O的效率时,可以用posix_fadvise来消除cache的影响;
当确认访问的文件在接下来一段时间不再被访问时,很有必要调用posix_fadvise来避免占用不必要的可用内存空间。
若当前系统内存十分紧张时,且在读写一个很大的文件时,为避免OOM风险,可以分段边读写边清cache,但也直接导致性能的下降,毕竟空间和时间是一对矛盾体。
3. 使用vmtouch控制Cache
vmtouch是一个可移植的文件系统cahce诊断和控制工具。近来该工具被广泛使用,最典型的例子是:移动应用Instagram(照片墙)后台服务端使用了vmtouch管理控制page cache。了解vmtouch原理及使用可以为我们后续后端设备所用。
快速安装指南:
$ git clone https://github.com/hoytech/vmtouch.git $ cd vmtouch $ make $ sudo make install
vmtouch用途:
查看一个文件(或者目录)哪些部分在内存中;
把文件调入内存;
把文件清除出内存,即释放page cache;
把文件锁住在内存中而不被换出到磁盘上;
……
vmtouch实现:
其核心分别是两个系统调用,mincore和posix_fadvise。两者具体使用方法使用man帮助都有详细的说明。posix_fadvise已在上文提到,用法在此不作说明。简单说下mincore:
NAME mincore - determine whether pages are resident in memory SYNOPSIS #include <unistd.h> #include <sys/mman.h> int mincore(void *addr, size_t length, unsigned char *vec); Feature Test Macro Requirements for glibc (see feature_test_macros(7)): mincore(): _BSD_SOURCE || _SVID_SOURCE
mincore需要调用者传入文件的地址(通常由mmap()返回),它会把文件在内存中的情况写在vec中。
vmtouch工具用法:
Usage:vmtouch [OPTIONS] ... FILES OR DIRECTORIES ...
Options:
-t touch pages into memory
-e evict pages from memory
-l lock pages in physical memory with mlock(2)
-L lock pages in physical memory with mlockall(2)
-d daemon mode
-m
-p
-f follow symbolic links
-h also count hardlinked copies
-w wait until all pages are locked (only useful together with -d)
-v verbose
-q quiet
用法举例:
例1、 获取当前/mnt/usb目录下cache占用量
[root@test nfs_dir] # mkdir /mnt/usb && mount /dev/msc /mnt/usb/ [root@test usb] # vmtouch . Files: 57 Directories: 2 Resident Pages: 0/278786 0/1G 0% Elapsed: 0.023126 seconds
例2、 当前test.bin文件的cache占用量?
[root@test usb] # vmtouch -v test.bin test.bin [ ] 0/25600 Files: 1 Directories: 0 Resident Pages: 0/25600 0/100M 0% Elapsed: 0.001867 seconds
这时使用tail命令将部分文件读取到内存中:
[root@test usb] # busybox_v400 tail -n 10 test.bin > /dev/null
现在再来看一下:
[root@test usb] # vmtouch -v test.bin test.bin [ o] 240/25600 Files: 1 Directories: 0 Resident Pages: 240/25600 960K/100M 0.938% Elapsed: 0.002019 seconds
可知目前文件test.bin的最后240个page驻留在内存中。
例3、 最后使用-t选项将剩下的test.bin文件全部读入内存:
[root@test usb] # vmtouch -vt test.bin test.bin [OOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOO] 25600/25600 Files: 1 Directories: 0 Touched Pages: 25600 (100M) Elapsed: 39.049 seconds
例4、 再把test.bin占用的cachae全部释放:
[root@test usb] # vmtouch -ev test.bin Evicting test.bin Files: 1 Directories: 0 Evicted Pages: 25600 (100M) Elapsed: 0.01461 seconds
这时候再来看下是否真的被释放了:
[root@test usb] # vmtouch -v test.bin test.bin [ ] 0/25600 Files: 1 Directories: 0 Resident Pages: 0/25600 0/100M 0% Elapsed: 0.001867 seconds
以上通过代码分析及实际操作总结了vmtouch工具的使用,建议APP组后续集成或借鉴vmtouch工具并灵活应用到后端设备中,必能达到有效管理和控制page cache的目的。
4. 使用BLKFLSBUF清Buffer
通过走读块设备驱动IOCTL命令实现,发现该命令能有效的清除整个块设备所占用的buffer。
int blkdev_ioctl(struct block_device *bdev, fmode_t mode, unsigned cmd, unsigned long arg) { struct gendisk *disk = bdev->bd_disk; struct backing_dev_info *bdi; loff_t size; int ret, n; switch(cmd) { case BLKFLSBUF: if (!capable(CAP_SYS_ADMIN)) return -EACCES; ret = __blkdev_driver_ioctl(bdev, mode, cmd, arg); if (!is_unrecognized_ioctl(ret)) return ret; fsync_bdev(bdev); invalidate_bdev(bdev); return 0; case ……: ………… } /* Invalidate clean unused buffers and pagecache. */ void invalidate_bdev(struct block_device *bdev) { struct address_space *mapping = bdev->bd_inode->i_mapping; if (mapping->nrpages == 0) return; invalidate_bh_lrus(); lru_add_drain_all(); /* make sure all lru add caches are flushed */ invalidate_mapping_pages(mapping, 0, -1); /* 99% of the time, we don't need to flush the cleancache on the bdev. * But, for the strange corners, lets be cautious */ cleancache_invalidate_inode(mapping); } EXPORT_SYMBOL(invalidate_bdev);光代码不够,现在让我们看下对/dev/h_sda这个块设备执行BLKFLSBUF的IOCTL命令前后的实际内存变化:
[0225_19:10:25:10s][root@test nfs_dir] # cat /proc/meminfo [0225_19:10:25:10s]MemTotal: 90532 kB [0225_19:10:25:10s]MemFree: 12296 kB [0225_19:10:25:10s]Buffers: 46076 kB [0225_19:10:25:10s]Cached: 4136 kB ………… [0225_19:10:42:10s][root@test nfs_dir] # /mnt/nfs_dir/a.out [0225_19:10:42:10s]ioctl cmd BLKFLSBUF ok! [0225_19:10:44:10s][root@test nfs_dir] # cat /proc/meminfo [0225_19:10:44:10s]MemTotal: 90532 kB [0225_19:10:44:10s]MemFree: 58988 kB [0225_19:10:44:10s]Buffers: 0 kB ………… [0225_19:10:44:10s]Cached: 4144 kB
执行的效果如代码中看到的,Buffers已被全部清除了,MemFree一下增长了约46MB,可以知道原先的Buffer已被回收并转化为可用的内存。整个过程Cache几乎没有变化,仅增加的8K cache内存可以推断用于a.out本身及其他库文件的加载。
上述a.out的示例如下:
#include <stdio.h> #include <fcntl.h> #include <errno.h> #include <sys/ioctl.h> #define BLKFLSBUF _IO(0x12, 97) int main(int argc, char* argv[]) { int fd = -1; fd = open("/dev/h_sda", O_RDWR); if (fd < 0) { return -1; } if (ioctl(fd, BLKFLSBUF, 0)) { printf("ioctl cmd BLKFLSBUF failed, errno:%d\n", errno); } close(fd); printf("ioctl cmd BLKFLSBUF ok!\n"); return 0; }综上,使用块设备命令BLKFLSBUF能有效的清除块设备上的所有buffer,且清除后的buffer能立即被释放变为可用内存。
利用这一点,联系后端业务场景,给出应用程序编程建议:
每次关闭一个块设备文件描述符前,必须要调用BLKFLSBUF命令,确保buffer中的脏数据及时刷入块设备,避免意外断电导致数据丢失,同时也起到及时释放回收buffer的目的。
当操作一个较大的块设备时,必要时可以调用BLKFLSBUF命令。怎样算较大的块设备?一般理解为当前Linux系统可用的物理内存小于操作的块设备大小。
5. 使用drop_caches控制Cache和Buffer
/proc是一个虚拟文件系统,我们可以通过对它的读写操作作为与kernel实体间进行通信的一种手段.也就是说可以通过修改/proc中的文件来对当前kernel的行为做出调整。关于Cache和Buffer的控制,我们可以通过echo 1 > /proc/sys/vm/drop_caches进行操作。
首先来看下内核源码实现:
int drop_caches_sysctl_handler(ctl_table *table, int write, void __user *buffer, size_t *length, loff_t *ppos) { int ret; ret = proc_dointvec_minmax(table, write, buffer, length, ppos); if (ret) return ret; if (write) { /* => echo 1 > /proc/sys/vm/drop_caches 清理页缓存 */ if (sysctl_drop_caches & 1) /* => 遍历所有的超级块,清理所有的缓存 */ iterate_supers(drop_pagecache_sb, NULL); if (sysctl_drop_caches & 2) drop_slab(); } return 0; } /** * iterate_supers - call function for all active superblocks * @f: function to call * @arg: argument to pass to it * * Scans the superblock list and calls given function, passing it * locked superblock and given argument. */ void iterate_supers(void (*f)(struct super_block *, void *), void *arg) { struct super_block *sb, *p = NULL; spin_lock(&sb_lock); list_for_each_entry(sb, &super_blocks, s_list) { if (hlist_unhashed(&sb->s_instances)) continue; sb->s_count++; spin_unlock(&sb_lock); down_read(&sb->s_umount); if (sb->s_root && (sb->s_flags & MS_BORN)) f(sb, arg); up_read(&sb->s_umount); spin_lock(&sb_lock); if (p) __put_super(p); p = sb; } if (p) __put_super(p); spin_unlock(&sb_lock); } /* => 清理文件系统(包括bdev伪文件系统)的页缓存 */ static void drop_pagecache_sb(struct super_block *sb, void *unused) { struct inode *inode, *toput_inode = NULL; spin_lock(&inode_sb_list_lock); /* => 遍历所有的inode */ list_for_each_entry(inode, &sb->s_inodes, i_sb_list) { spin_lock(&inode->i_lock); /* * => 若当前状态为(I_FREEING|I_WILL_FREE|I_NEW) 或 * => 若没有缓存页 * => 则跳过 */ if ((inode->i_state & (I_FREEING|I_WILL_FREE|I_NEW)) || (inode->i_mapping->nrpages == 0)) { spin_unlock(&inode->i_lock); continue; } __iget(inode); spin_unlock(&inode->i_lock); spin_unlock(&inode_sb_list_lock); /* => 清除缓存页(除了脏页、上锁的、正在回写的或映射在页表中的)*/ invalidate_mapping_pages(inode->i_mapping, 0, -1); iput(toput_inode); toput_inode = inode; spin_lock(&inode_sb_list_lock); } spin_unlock(&inode_sb_list_lock); iput(toput_inode); }综上,echo 1 > /proc/sys/vm/drop_caches会清除所有inode的缓存页,这里的inode包括VFS的inode、所有文件系统inode(也包括bdev伪文件系统块设备的inode的缓存页)。所以该命令执行后,就会将整个系统的page cache和buffer cache全部清除,当然前提是这些cache都是非脏的、没有正被使用的。
接下来看下实际效果:
[root@test usb] # cat /proc/meminfo MemTotal: 90516 kB MemFree: 12396 kB Buffers: 96 kB Cached: 60756 kB [root@test usb] # busybox_v400 sync [root@test usb] # busybox_v400 sync [root@test usb] # busybox_v400 sync [root@test usb] # echo 1 > /proc/sys/vm/drop_caches [root@test usb] # cat /proc/meminfo MemTotal: 90516 kB MemFree: 68820 kB Buffers: 12 kB Cached: 4464 kB
可以看到Buffers和Cached都降了下来,在drop_caches前建议执行sync命令,以确保数据的完整性。sync 命令会将所有未写的系统缓冲区写到磁盘中,包含已修改的 i-node、已延迟的块 I/O 和读写映射文件等。
上面的设置虽然简单但是比较粗暴,使cache的作用基本无法发挥,尤其在系统压力比较大时进行drop cache处理容易产生问题。因为drop_cache是全局在清内存,清的过程会加页面锁,导致有些进程等页面锁时超时,导致问题发生。因此,需要根据系统的状况进行适当的调节寻找最佳的方案。
6. 经验总结
分别讨论了Cache和Buffer分别从哪里来?什么时候消耗在哪里?如何分别控制Cache和Buffer这三个问题。最后还介绍了vmtouch工具的使用。
要深入理解Linux的Cache和Buffer牵涉大量内核核心机制(VFS、内存管理、块设备驱动、页高速缓存、文件访问、页框回写),需要制定计划在后续工作中不断理解和消化。
以上就是怎么理解Linux的Cache和Buffer,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





