这篇文章将为大家详细讲解有关如何使用Scrapy网络爬虫框架,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
scrapy 介绍
标准介绍
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍。所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性的项目模板。对于框架的学习,重点是要学习其框架的特性、各个功能的用法即可。
说人话就是
只要是搞爬虫的,用这个就van事了,因为里面集成了一些很棒的工具,并且爬取性能很高,预留有很多钩子方便扩展,实在是居家爬虫的不二之选。
windows下安装scrapy
命令
pip install scrapy
默认情况下,直接pip install scrapy可能会失败,如果没有换源,加上临时源安装试试,这里使用的是清华源,常见安装问题可以参考这个文章:Windows下安装Scrapy方法及常见安装问题总结——Scrapy安装教程。
命令
pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple
scrapy创建爬虫项目
命令
scrapy startproject <项目名称>示例:创建一个糗事百科的爬虫项目(记得cd到一个干净的目录哈)
scrapy startproject qiushibaike
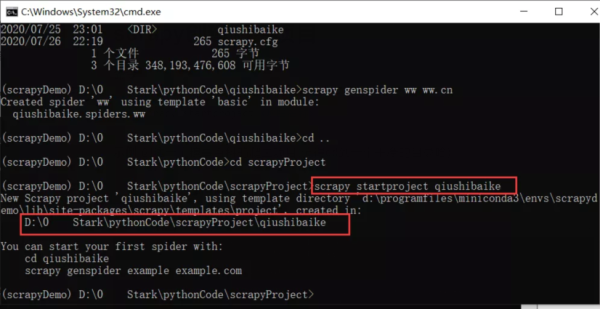
注:此时,我们已经创建好了一个爬虫项目,但是爬虫项目是一个文件夹
进入爬虫项目
如果想要进入这个项目,就要cd进这个目录,如上上图所示,先cd <项目>,再创建蜘蛛

项目目录结构解析
此时,我们就已经进入了项目,结构如下,有一个和项目名同名的文件夹和一个scrapy.cfg文件
scrapy.cfg # scrapy配置,特殊情况使用此配置 qiushibaike # 项目名同名的文件夹 items.py # 数据存储模板,定制要保存的字段 middlewares.py # 爬虫中间件 pipelines.py # 编写数据持久化代码 settings.py # 配置文件,例如:控制爬取速度,多大并发量,等 __init__.py spiders # 爬虫目录,一个个爬虫文件,编写数据解析代码 __init__.py呃,可能此时你并不能懂这么些目录什么意思,不过不要慌,使用一下可能就懂了,别慌。
创建蜘蛛
通过上述的操作,假设你已经成功的安装好了scrapy,并且进入了创建的项目
那么,我们就创建一个蜘蛛,对糗事百科的段子进行爬取。
创建蜘蛛命令
scrapy genspider <蜘蛛名称> <网页的起始url>示例:创建糗事百科的段子蜘蛛
scrapy genspider duanzi ww.com

注:网页的起始url可以随便写,可以随便改,但是必须有
此时在spider文件夹下,会多一个duanzi.py文件
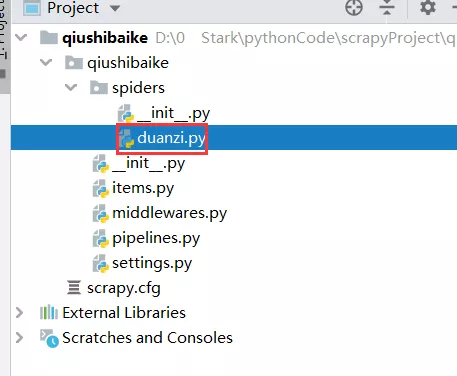
代码解释如下
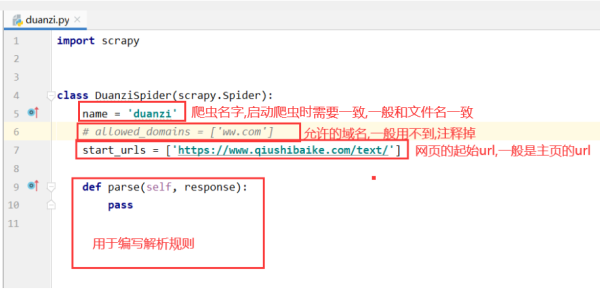
爬取数据前准备
创建好蜘蛛之后,需要在配置一些东西的,不能直接就爬的,默认是爬取不了的,需要简单配置一下
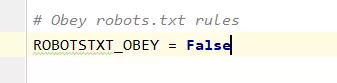
打开settings.py文件,找到ROBOTSTXT_OBEY和USER_AGENT变量
ROBOTSTXT_OBEY配置
等于False不遵守robot协议,默认只有搜索引擎网站才会允许爬取,例如百度,必应等,个人爬取需要忽略这个,否则爬取不了
USER_AGENT配置
User-Agent是一个最基本的请求必须带的参数,如果这个带的不是正常的,必定爬取不了。
User-Agent
Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36 
小试牛刀之获取糗事百科段子段子链接
准备工作做好了,那就开始吧!!!
此处我们需要有xpath的语法基础,其实挺简单的,没有基础的记得百度一下,其实不百度也没关系,跟着学,大概能看懂
实现功能
通过xpath获取每个段子下的a标签连接
注:审查元素和按住crtl+f搜索内容和写xpath这里不再啰嗦
分析页面规则
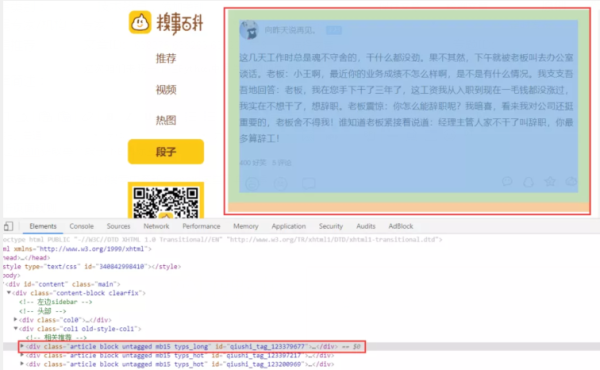
通过审查工具,我们可以看到,class包含article的标签就是一个个的文章,可能你想到xpath可能可以这样写
xpath代码
//div[@class='article']但是你会发现一个都查不出来,因为是包含的关系,所以需要用contains关键字
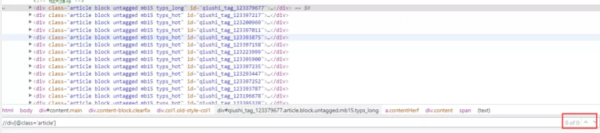
我们需要这样写
xpath代码
//div[contains(@class,"article")] 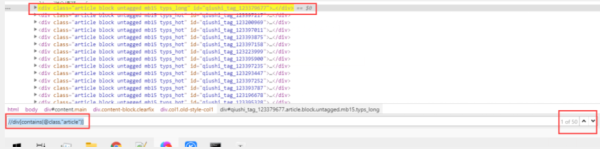
但是会发现,这定位的太多了,并不是每个段子的div,所以我们要多包含几个,这样,就是每个段子的div了
//div[contains(@class,"article") and contains(@class,"block")] 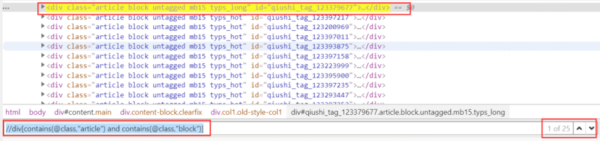
上述已经成功定位了一个个的段子,下面在此基础上,定位到每个段子下的a标签
根据审查元素,发现每个段子下class="contentHerf"的a标签,就是每个段子的详情页
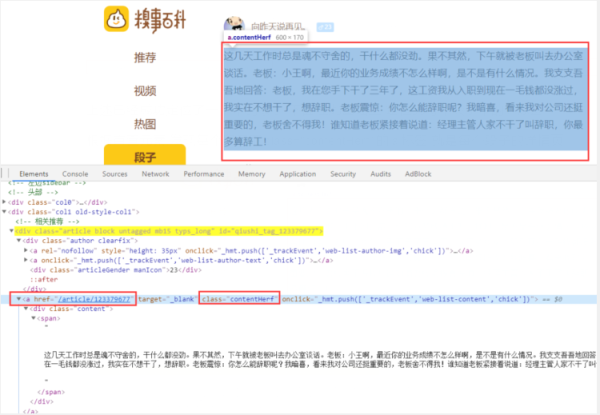
详情页,要定位的a标签的href确实是详情页的url
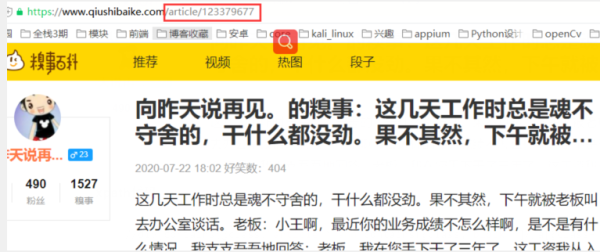
xpath代码
//div[contains(@class,"article") and contains(@class,"block")]//a[@class="contentHerf"] 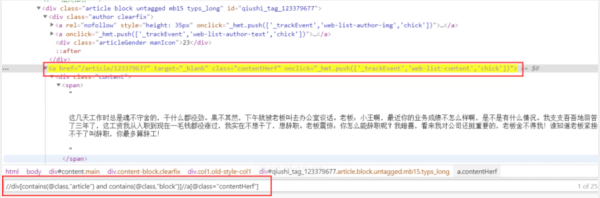
这样,我们就定位了一个个a标签,只至少在控制台操作是没问题的,那么,我们使用Python代码操作一下吧
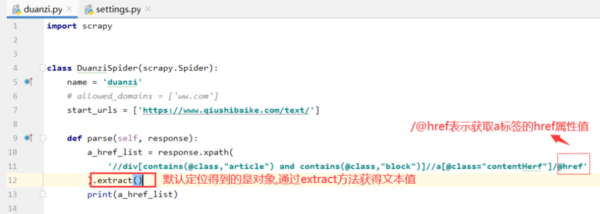
代码
def parse(self, response): a_href_list = response.xpath('//div[contains(@class,"article") and contains(@class,"block")]//a[@class="contentHerf"]/@href' ).extract() print(a_href_list)启动蜘蛛命令
scrapy crawl <爬虫名> [--nolog]注:--nolog参数不加表示一系列日志,一般用于调试,加此参数表示只输入print内容
示例:启动段子命令
scrapy crawl duanzi --nolog 
成功拿到每一个链接。
获取详情页内容
在上述,我们成功的获取到了每个段子的链接,但是会发现有的段子是不全的,需要进入进入详情页才能看到所以段子内容,那我们就使用爬虫来操作一下吧。
我们定义一下标题和内容。

根据元素审查,标题的定位xpath是:
//h2[@class="article-title"] 
内容的xpath是:
//div[@class="content"] 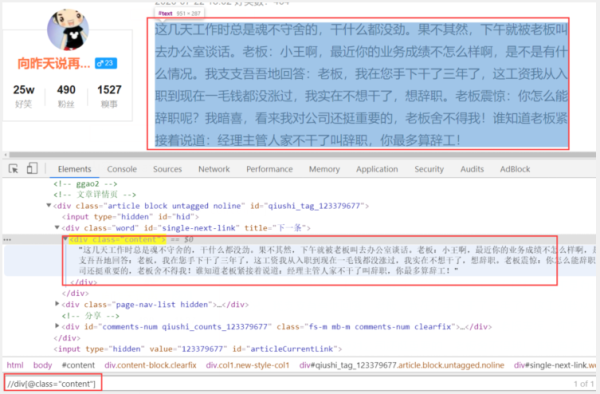
确定标题和内容的xpath定位之后,我们在python代码中实现一下。
注:但是先解决一个问题,详情页属于第二次调用了,所以我们也需要进行调用第二次,再编写代码

代码
# 详情页 def detail(self, response): title = response.xpath('//h2[@class="article-title"]/text()').extract() content = response.xpath('//div[@class="content"]//text()').extract() print("标题:" ) print(title) print("内容") print(content) def parse(self, response): a_href_list = response.xpath( '//div[contains(@class,"article") and contains(@class,"block")]//a[@class="contentHerf"]/@href' ).extract() print(a_href_list) base_url = "https://www.qiushibaike.com" for a_href in a_href_list: url = f"{base_url}{a_href}" yield scrapy.Request(url=url, callback=self.detail)结果
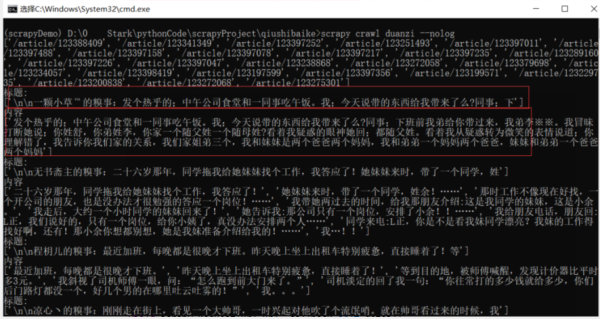
但是会发现啊,似乎每个都是列表形式,这似乎不太行呐,我们稍微修改一下代码,这样我们拿到的就是正常的文本了,如下图所示:
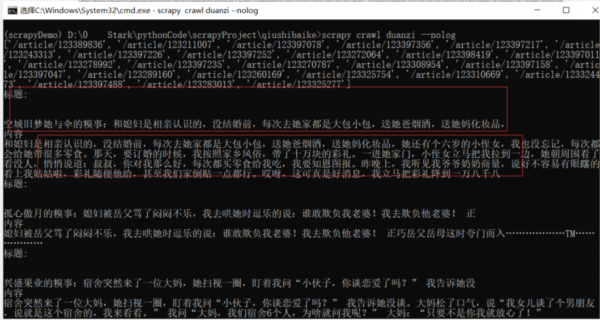
上述命令总结
创建爬虫项目
scrapy startproject <项目名称>创建蜘蛛
scrapy genspider <蜘蛛名称> <网页的起始url>启动爬虫,--nolog参数不加表示一系列日志,一般用于调试,加此参数表示只输入print内容
scrapy crawl <爬虫名> [--nolog]关于“如何使用Scrapy网络爬虫框架”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://mp.weixin.qq.com/s/eClixDQzLKmckHPNG66WVw



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



