Python中怎么利用DBSCAN实现一个密度聚类算法,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
基于密度这点有什么好处呢?
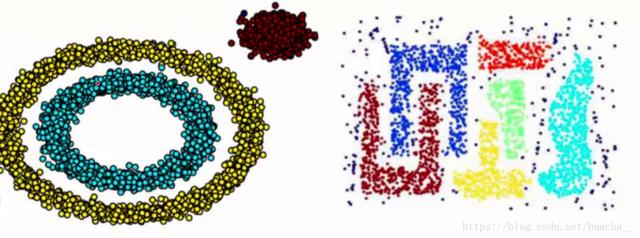
我们知道kmeans聚类算法只能处理球形的簇,也就是一个聚成实心的团(这是因为算法本身计算平均距离的局限)。但往往现实中还会有各种形状,比如下面两张图,环形和不规则形,这个时候,那些传统的聚类算法显然就悲剧了。
于是就思考,样本密度大的成一类呗,这就是DBSCAN聚类算法。
三、参数选择
上面提到了红色圆圈滚啊滚的过程,这个过程就包括了DBSCAN算法的两个参数,这两个参数比较难指定,公认的指定方法简单说一下:
半径:半径是最难指定的 ,大了,圈住的就多了,簇的个数就少了;反之,簇的个数就多了,这对我们最后的结果是有影响的。我们这个时候K距离可以帮助我们来设定半径r,也就是要找到突变点,比如: 以上虽然是一个可取的方式,但是有时候比较麻烦 ,大部分还是都试一试进行观察,用k距离需要做大量实验来观察,很难一次性把这些值都选准。
MinPts:这个参数就是圈住的点的个数,也相当于是一个密度,一般这个值都是偏小一些,然后进行多次尝试
四、DBSCAN算法迭代可视化展示
国外有一个特别有意思的网站,它可以把我们DBSCAN的迭代过程动态图画出来。
网址:naftaliharris[1]
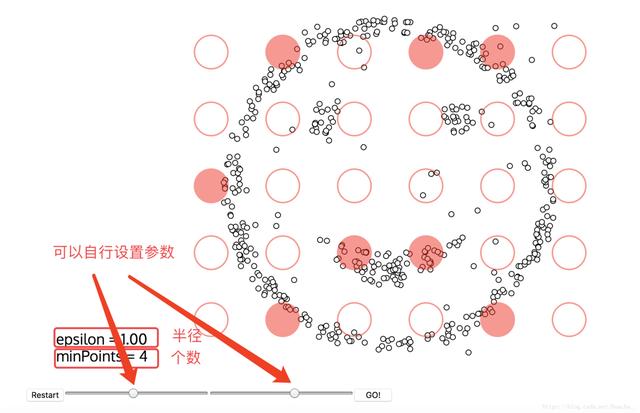
设置好参数,点击GO! 就开始聚类了!
五、常用评估方法:轮廓系数
这里提一下聚类算法中最常用的评估方法——轮廓系数(Silhouette Coefficient):
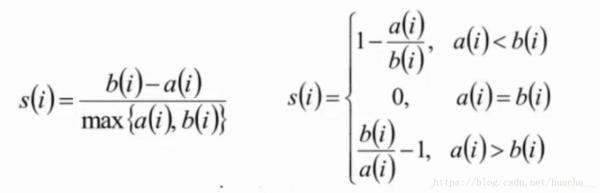
计算样本i到同簇其它样本到平均距离ai,ai越小,说明样本i越应该被聚类到该簇(将ai称为样本i到簇内不相似度);
计算样本i到其它某簇Cj的所有样本的平均距离bij,称为样本i与簇Cj的不相似度。定义为样本i的簇间不相似度:bi=min(bi1,bi2,...,bik2);
说明:
si接近1,则说明样本i聚类合理;
si接近-1,则说明样本i更应该分类到另外的簇;
若si近似为0,则说明样本i在两个簇的边界上;
六、用Python实现DBSCAN聚类算法
导入数据:
import pandas as pd from sklearn.datasets import load_iris # 导入数据,sklearn自带鸢尾花数据集 iris = load_iris().data print(iris)输出:

使用DBSCAN算法:
from sklearn.cluster import DBSCAN iris_db = DBSCAN(eps=0.6,min_samples=4).fit_predict(iris) # 设置半径为0.6,最小样本量为2,建模 db = DBSCAN(eps=10, min_samples=2).fit(iris) # 统计每一类的数量 counts = pd.value_counts(iris_db,sort=True) print(counts)
可视化:
import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = [u'Microsoft YaHei'] fig,ax = plt.subplots(1,2,figsize=(12,12)) # 画聚类后的结果 ax1 = ax[0] ax1.scatter(x=iris[:,0],y=iris[:,1],s=250,c=iris_db) ax1.set_title('DBSCAN聚类结果',fontsize=20) # 画真实数据结果 ax2 = ax[1] ax2.scatter(x=iris[:,0],y=iris[:,1],s=250,c=load_iris().target) ax2.set_title('真实分类',fontsize=20) plt.show()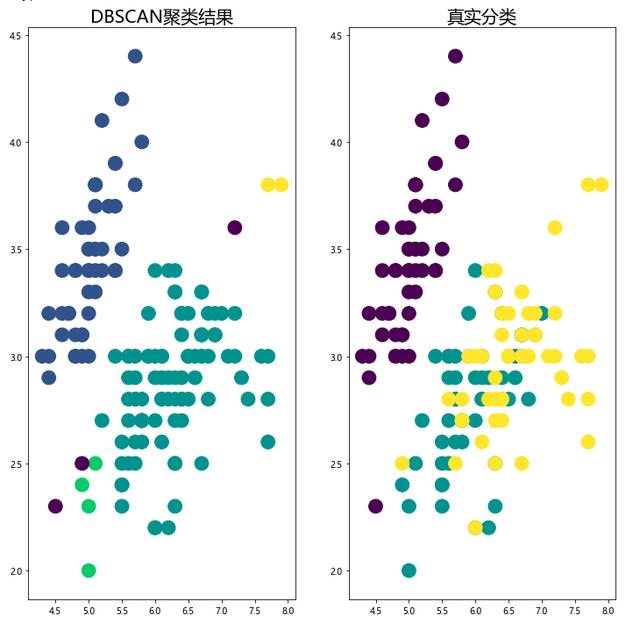
我们可以从上面这个图里观察聚类效果的好坏,但是当数据量很大,或者指标很多的时候,观察起来就会非常麻烦。
这时候可以使用轮廓系数来判定结果好坏,聚类结果的轮廓系数,定义为S,是该聚类是否合理、有效的度量。
聚类结果的轮廓系数的取值在[-1,1]之间,值越大,说明同类样本相距越近,不同样本相距越远,则聚类效果越好。
轮廓系数以及其他的评价函数都定义在sklearn.metrics模块中,在sklearn中函数silhouette_score()计算所有点的平均轮廓系数。
from sklearn import metrics # 就是下面这个函数可以计算轮廓系数(sklearn真是一个强大的包) score = metrics.silhouette_score(iris,iris_db) score结果: 0.364
看完上述内容,你们掌握Python中怎么利用DBSCAN实现一个密度聚类算法的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://www.toutiao.com/a6847342521194906115/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



