本篇内容主要讲解“如何使用分布式锁”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“如何使用分布式锁”吧!
什么是分布式锁?分布式锁又可以解决哪些问题呢?
在我们的系统还没有使用分布式架构的时候,我们可以用同步锁或者Lock锁,来保证多线程并发的时候,同一时间只有一个线程修改共享变量或者执行代码块,但是当我们现在大部分系统都是分布式集群部署的,单纯的同步锁和Lock锁只能保证单个实例上的数据一致性,多实例就失去了作用。
这个时候就需要使用分布式锁来保证共享资源的原子性,比如我们电商系统里面的扣减库存,当单量小的时候问题不大,如果单量很大,同一时间多个实例都在并发处理扣减库存的业务的时候,就可能存在超卖的问题。
分布式锁的实现?
常见的分布式锁有数据库实现分布式锁、Zookeeper实现分布式锁、Redis实现分布式锁、Redisson实现。其中数据库实现分布式锁比较简单,也很容易理解,直接基于数据库实现就可以了,在一些分布式的业务中也经常使用,但是这种方式也是效率最低的,一般是不使用的,我们就着重介绍一下其他三种方式的实现。
Zookeeper实现分布式锁
使用Zookeeper来实现分布式锁就比较常见,比如很多项目就使用Zookeeper作为分布式注册中心,就喜欢用Zookeeper来实现分布式锁,这主要是借助于Zookeeper的两大特性:顺序临时节点、Watch机制。
顺序临时节点:熟悉Zookeeper的同学都知道,Zookeeper提供了多层级的节点命名空间,每个节点都是用斜杠分隔的路径来表示,类似于我们的文件夹。节点又分为持久节点和临时节点,节点还可以标记为有序,当节点被标记为有序性,这个节点就具有顺序自增的特点,我们就可以借助这个特点来创建我们所需的节点。
Watch机制:Watch机制是Zookeeper另一个重要的特性,我们可以在指定节点上注册一些Watcher,在一些特定的事情触发的时候,通知用户这个事件。
Zookeeper实现分布式锁的过程
我们先创建一个持久节点作为父节点,每当需要访问创建分布式锁的时候,就在这个父节点下创建相应的临时的顺序子节点,以临时节点名称、父节点名称和顺序号组成特点的名称。在建立子节点后,对父节点下以这个这个子节点名称开头的子节点进行排序,判断刚建立的节点顺序号是不是最小的,如果是最小的则获取锁,如果不是最小节点,则阻塞等待锁,并且在获取该节点的上一顺序节点注册Watcher,等待节点对应的操作获得锁。
当业务处理完之后,删除该节点,关闭zk,进而触发Watcher,释放该锁。
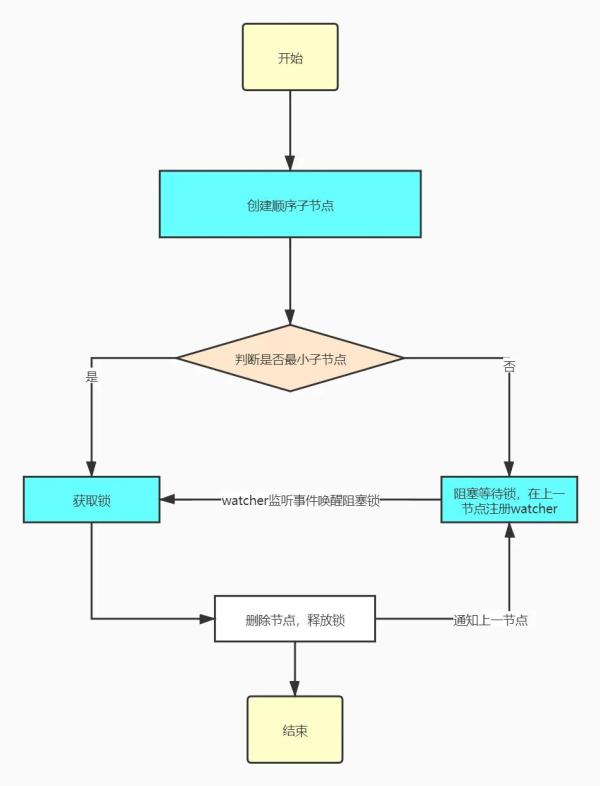
上图就是就是严格按照顺序访问的分布式锁实现,更多的时候我们引入一些框架来帮助我们实现,比如最常用的Curator框架,代码如下:
InterProcessMutex lock = new InterProcessMutex(client, lockPath); if ( lock.acquire(maxWait, waitUnit) ) { try { // 业务处理 } finally{ lock.release(); } }Zookeeper来实现分布式锁天然的优势就是,Zookeeper是集群实现的,我们生产环境一般也是集群部署的,可以避免单点问题,稳定性较好,能保证每次操作都可以释放锁。
缺点就是,频繁的创建删除节点,加上注册watch事件,对于zookeeper集群的压力比较大,性能这一块也比不上Redis实现的分布式锁。
Redis实现分布式锁
Redis实现的分布式锁,最为复杂,但是性能确是最佳的,所以在对性能要求更高的系统里,我们都选择使用Redis来实现分布式锁。利用Redis实现分布式锁,一般都是使用SETNX实现,举个简单的例子:
public static boolean getDistributedLock(Jedis jedis, String lockKey, String requestId, int expireTime) { String result = jedis.set(lockKey, requestId, SET_IF_NOT_EXIST, SET_WITH_EXPIRE_TIME, expireTime); if ("OK".equals(result)) { return true; } return false; }SETNX方法保证设置锁和锁过期时间的原子性,但是对于锁的过期时间设置我们要注意,如果执行业务
时间比较长,我们设置的过期时间又比较短的情况下就会造成,业务还没执行完,锁已释放的问题。所以我们需要根据实际业务处理来评估设置锁的过期时间,来保证业务可以正常的处理完。
Redisson实现分布式锁
Redisson是架设在Redis基础上的一个Java驻内存数据网格。Redisson在基于NIO的Netty框架上,充分的利用了Redis键值数据库提供的一系列优势,在Java实用工具包中常用接口的基础上,为使用者提供了一系列具有分布式特性的常用工具类。性能也比我们常用的jedis好一些。
Redisson不管是单节点模式还是集群模式,都很好的实现了分布式锁,一般用的多的都是集群模式,在集群模式下,Redisson使用RedLock算法,很好的处理了Master节点宕机时切换到另外一个Master节点过程中多个应用获得锁。
Redisson集群模式获取锁的实现就是,在不同节点上获取锁,每个节点上获取锁都有超时时间,如果获取锁超时就认为这个节点不可用,当成功获取锁的个数超过Redis节点的半数,且获取锁消耗的时间还没超过锁过期时间,则认为获取锁成功。获取锁成功后重新计算锁释放时间,由原来的锁释放时间减去获取锁消耗的时间,如果最终获取锁失败,已经获取锁成功的节点也会释放锁。
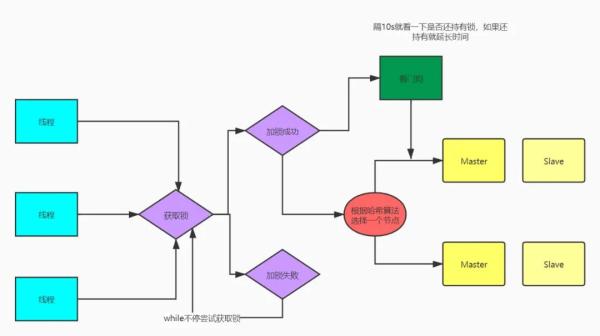
具体的代码实现:
引入依赖
<dependency> <groupId>org.redisson</groupId> <artifactId>redisson</artifactId> <version>3.13.1</version> </dependency>Redisson配置文件:
@Bean public RedissonClient redissonClient() { Config config = new Config(); config.useClusterServers() .setScanInterval(3000) // 集群状态扫描间隔时间,单位是毫秒 .addNodeAddress("redis://192.168.0.1:6379).setPassword("666") .addNodeAddress("redis://192.168.0.2:6379").setPassword("666") .addNodeAddress("redis://192.168.0.3:6379") .setPassword("666"); return Redisson.create(config); }获取锁操作:
long waitTimeout = 10; long leaseTime = 1; RLock lock1 = redissonClient1.getLock("lock1"); RLock lock2 = redissonClient2.getLock("lock2"); RLock lock3 = redissonClient3.getLock("lock3"); RedissonRedLock redLock = new RedissonRedLock(lock1, lock2, lock3); redLock.trylock(waitTimeout,leaseTime,TimeUnit.SECONDS); try{ //... }finally{ redLock.unlock(); }总结
实现分布式锁的方式不止这三种,最简单的就是数据库实现,Zookeeper实现也相对比较简单,但是性能最好的还是Redis实现,但是可靠性方面,Zookeeper基于分布式集群,具有天然的优势,可靠性相对更高。如果业务场景对性能要求不是很高的时候,优先使用Zookeeper实现分布式锁。
到此,相信大家对“如何使用分布式锁”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://mp.weixin.qq.com/s/QOYUPiJCkruk6IHrO2QonA



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



