еҰӮдҪ•з”ЁPythonзҗҶи§Јдәәе·ҘжҷәиғҪдјҳеҢ–з®—жі•
иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶д»Ӣз»ҚеҰӮдҪ•з”ЁPythonзҗҶи§Јдәәе·ҘжҷәиғҪдјҳеҢ–з®—жі•пјҢеҶ…е®№йқһеёёиҜҰз»ҶпјҢж„ҹе…ҙи¶Јзҡ„е°Ҹдјҷдјҙ们еҸҜд»ҘеҸӮиҖғеҖҹйүҙпјҢеёҢжңӣеҜ№еӨ§е®¶иғҪжңүжүҖеё®еҠ©гҖӮ
жҰӮиҝ°
жўҜеәҰдёӢйҷҚжҳҜзҘһз»ҸзҪ‘з»ңдёӯжөҒиЎҢзҡ„дјҳеҢ–з®—жі•д№ӢдёҖгҖӮдёҖиҲ¬жқҘиҜҙпјҢжҲ‘们жғіиҰҒжүҫеҲ°жңҖе°ҸеҢ–иҜҜе·®еҮҪж•°зҡ„жқғйҮҚе’ҢеҒҸе·®гҖӮжўҜеәҰдёӢйҷҚз®—жі•иҝӯд»Јең°жӣҙж–°еҸӮж•°пјҢд»ҘдҪҝж•ҙдҪ“зҪ‘з»ңзҡ„иҜҜе·®жңҖе°ҸеҢ–гҖӮ
жўҜеәҰдёӢйҷҚжҳҜиҝӯд»Јжі•зҡ„дёҖз§Қ,еҸҜд»Ҙз”ЁдәҺжұӮи§ЈжңҖе°ҸдәҢд№ҳй—®йўҳ(зәҝжҖ§е’ҢйқһзәҝжҖ§йғҪеҸҜд»Ҙ)гҖӮеңЁжұӮи§ЈжңәеҷЁеӯҰд№ з®—жі•зҡ„жЁЎеһӢеҸӮж•°пјҢеҚіж— зәҰжқҹдјҳеҢ–й—®йўҳж—¶пјҢжўҜеәҰдёӢйҷҚ(Gradient Descent)жҳҜжңҖеёёйҮҮз”Ёзҡ„ж–№жі•д№ӢдёҖпјҢеҸҰдёҖз§Қеёёз”Ёзҡ„ж–№жі•жҳҜжңҖе°ҸдәҢд№ҳжі•гҖӮеңЁжұӮи§ЈжҚҹеӨұеҮҪж•°зҡ„жңҖе°ҸеҖјж—¶пјҢеҸҜд»ҘйҖҡиҝҮжўҜеәҰдёӢйҷҚжі•жқҘдёҖжӯҘжӯҘзҡ„иҝӯд»ЈжұӮи§ЈпјҢеҫ—еҲ°жңҖе°ҸеҢ–зҡ„жҚҹеӨұеҮҪж•°е’ҢжЁЎеһӢеҸӮж•°еҖјгҖӮеҸҚиҝҮжқҘпјҢеҰӮжһңжҲ‘们йңҖиҰҒжұӮи§ЈжҚҹеӨұеҮҪж•°зҡ„жңҖеӨ§еҖјпјҢиҝҷж—¶е°ұйңҖиҰҒз”ЁжўҜеәҰдёҠеҚҮжі•жқҘиҝӯд»ЈдәҶгҖӮеңЁжңәеҷЁеӯҰд№ дёӯпјҢеҹәдәҺеҹәжң¬зҡ„жўҜеәҰдёӢйҷҚжі•еҸ‘еұ•дәҶдёӨз§ҚжўҜеәҰдёӢйҷҚж–№жі•пјҢеҲҶеҲ«дёәйҡҸжңәжўҜеәҰдёӢйҷҚжі•е’Ңжү№йҮҸжўҜеәҰдёӢйҷҚжі•гҖӮ
иҜҘз®—жі•еңЁжҚҹеӨұеҮҪж•°зҡ„жўҜеәҰдёҠиҝӯд»Јең°жӣҙж–°жқғйҮҚеҸӮж•°пјҢзӣҙиҮіиҫҫеҲ°жңҖе°ҸеҖјгҖӮжҚўеҸҘиҜқиҜҙпјҢжҲ‘们жІҝзқҖжҚҹеӨұеҮҪж•°зҡ„ж–ңеқЎж–№еҗ‘дёӢеқЎпјҢзӣҙиҮіеҲ°иҫҫеұұи°·гҖӮеҹәжң¬жҖқжғіеӨ§иҮҙеҰӮеӣҫ3.8жүҖзӨәгҖӮеҰӮжһңеҒҸеҜјж•°дёәиҙҹпјҢеҲҷжқғйҮҚеўһеҠ (еӣҫзҡ„е·Ұдҫ§йғЁеҲҶ)пјҢеҰӮжһңеҒҸеҜјж•°дёәжӯЈпјҢеҲҷжқғйҮҚеҮҸе°Ҹ(еӣҫдёӯеҸіеҚҠйғЁеҲҶ) еӯҰд№ йҖҹзҺҮеҸӮж•°еҶіе®ҡдәҶиҫҫеҲ°жңҖе°ҸеҖјжүҖйңҖжӯҘж•°зҡ„еӨ§е°ҸгҖӮ
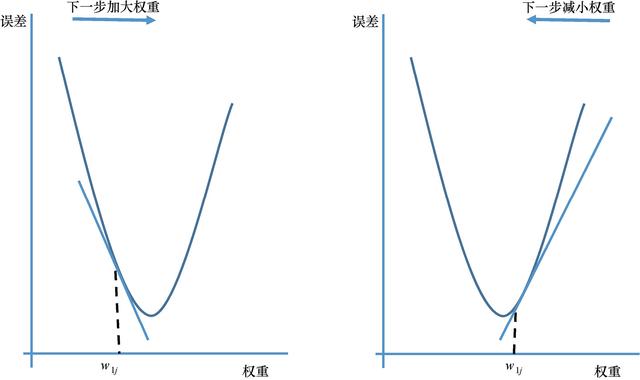
еӣҫ3.8гҖҖйҡҸжңәжўҜеәҰжңҖе°ҸеҢ–зҡ„еҹәжң¬жҖқжғі
иҜҜе·®жӣІйқў
еҜ»жүҫе…ЁеұҖжңҖдҪіж–№жЎҲзҡ„еҗҢж—¶йҒҝе…ҚеұҖйғЁжһҒе°ҸеҖјжҳҜдёҖ件еҫҲжңүжҢ‘жҲҳзҡ„дәӢжғ…гҖӮиҝҷжҳҜеӣ дёәиҜҜе·®жӣІйқўжңүеҫҲеӨҡзҡ„еі°е’Ңи°·пјҢеҰӮеӣҫ3.9жүҖзӨәгҖӮиҜҜе·®жӣІйқўеңЁдёҖдәӣж–№еҗ‘дёҠеҸҜиғҪжҳҜй«ҳеәҰејҜжӣІзҡ„пјҢдҪҶеңЁе…¶д»–ж–№еҗ‘жҳҜе№іеқҰзҡ„гҖӮиҝҷдҪҝеҫ—дјҳеҢ–иҝҮзЁӢйқһеёёеӨҚжқӮгҖӮдёәдәҶйҒҝе…ҚзҪ‘з»ңйҷ·е…ҘеұҖйғЁжһҒе°ҸеҖјзҡ„еўғең°пјҢйҖҡеёёиҰҒжҢҮе®ҡдёҖдёӘеҶІйҮҸ(momentum)еҸӮж•°гҖӮ
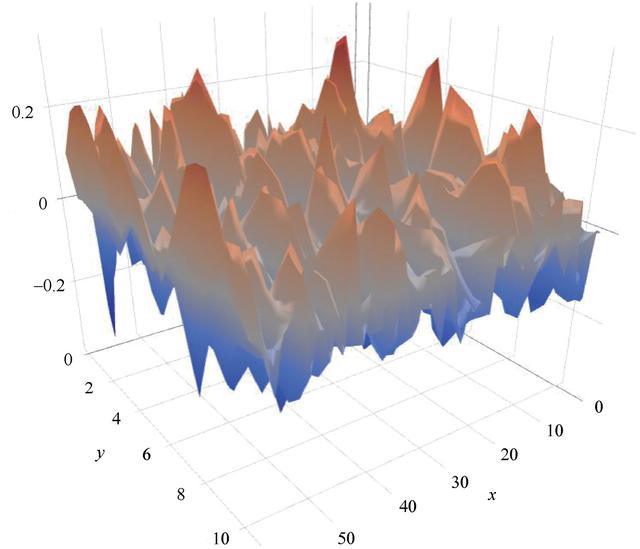
еӣҫ3.9гҖҖе…ёеһӢдјҳеҢ–й—®йўҳзҡ„еӨҚжқӮиҜҜе·®жӣІйқў
жҲ‘еҫҲж—©е°ұеҸ‘зҺ°пјҢдҪҝз”ЁжўҜеәҰдёӢйҷҚзҡ„еҸҚеҗ‘дј ж’ӯйҖҡ常收ж•ӣеҫ—йқһеёёзј“ж…ўпјҢжҲ–иҖ…ж №жң¬дёҚ收ж•ӣгҖӮеңЁзј–еҶҷ第дёҖдёӘзҘһз»ҸзҪ‘з»ңж—¶пјҢжҲ‘дҪҝз”ЁдәҶеҸҚеҗ‘дј ж’ӯз®—жі•пјҢиҜҘзҪ‘з»ңеҢ…еҗ«дёҖдёӘеҫҲе°Ҹзҡ„ж•°жҚ®йӣҶгҖӮзҪ‘з»ңз”ЁдәҶ3еӨ©еӨҡзҡ„ж—¶й—ҙжүҚ收ж•ӣеҲ°дёҖдёӘи§ЈеҶіж–№жЎҲгҖӮе№ёдәҸжҲ‘йҮҮеҸ–дёҖдәӣжҺӘж–ҪеҠ еҝ«дәҶеӨ„зҗҶиҝҮзЁӢгҖӮ
иҜҙжҳҺ иҷҪ然еҸҚеҗ‘дј ж’ӯзӣёе…ізҡ„еӯҰд№ йҖҹзҺҮзӣёеҜ№иҫғж…ўпјҢдҪҶдҪңдёәеүҚйҰҲз®—жі•пјҢе…¶еңЁйў„жөӢжҲ–иҖ…еҲҶзұ»йҳ¶ж®өжҳҜзӣёеҪ“еҝ«йҖҹзҡ„гҖӮ
йҡҸжңәжўҜеәҰдёӢйҷҚ
дј з»ҹзҡ„жўҜеәҰдёӢйҷҚз®—жі•дҪҝз”Ёж•ҙдёӘж•°жҚ®йӣҶжқҘи®Ўз®—жҜҸж¬Ўиҝӯд»Јзҡ„жўҜеәҰгҖӮеҜ№дәҺеӨ§еһӢж•°жҚ®йӣҶпјҢиҝҷдјҡеҜјиҮҙеҶ—дҪҷи®Ўз®—пјҢеӣ дёәеңЁжҜҸдёӘеҸӮж•°жӣҙж–°д№ӢеүҚпјҢйқһеёёзӣёдјјзҡ„ж ·жң¬зҡ„жўҜеәҰдјҡиў«йҮҚж–°и®Ўз®—гҖӮйҡҸжңәжўҜеәҰдёӢйҷҚ(SGD)жҳҜзңҹе®һжўҜеәҰзҡ„иҝ‘дјјеҖјгҖӮеңЁжҜҸж¬Ўиҝӯд»ЈдёӯпјҢе®ғйҡҸжңәйҖүжӢ©дёҖдёӘж ·жң¬жқҘжӣҙж–°еҸӮж•°пјҢ并еңЁиҜҘж ·жң¬зҡ„зӣёе…іжўҜеәҰдёҠ移еҠЁгҖӮеӣ жӯӨпјҢе®ғйҒөеҫӘдёҖжқЎжӣІжҠҳзҡ„йҖҡеҫҖжһҒе°ҸеҖјзҡ„жўҜеәҰи·Ҝеҫ„гҖӮеңЁжҹҗз§ҚзЁӢеәҰдёҠпјҢз”ұдәҺе…¶зјәд№ҸеҶ—дҪҷпјҢе®ғеҫҖеҫҖиғҪжҜ”дј з»ҹжўҜеәҰдёӢйҷҚжӣҙеҝ«ең°ж”¶ж•ӣеҲ°и§ЈеҶіж–№жЎҲгҖӮ
иҜҙжҳҺ йҡҸжңәжўҜеәҰдёӢйҷҚзҡ„дёҖдёӘйқһеёёеҘҪзҡ„зҗҶи®әзү№жҖ§жҳҜпјҢеҰӮжһңжҚҹеӨұеҮҪж•°жҳҜеҮёзҡ„ 43 пјҢйӮЈд№ҲдҝқиҜҒиғҪжүҫеҲ°е…ЁеұҖжңҖе°ҸеҖјгҖӮ
д»Јз Ғе®һи·ө
зҗҶи®әе·Із»Ҹи¶іеӨҹеӨҡдәҶпјҢжҺҘдёӢжқҘж•ІдёҖж•Іе®һеңЁзҡ„д»Јз Ғеҗ§гҖӮ
дёҖз»ҙй—®йўҳ
еҒҮи®ҫжҲ‘们йңҖиҰҒжұӮи§Јзҡ„зӣ®ж ҮеҮҪж•°жҳҜпјҡ
()=2+1f(x)=x2+1
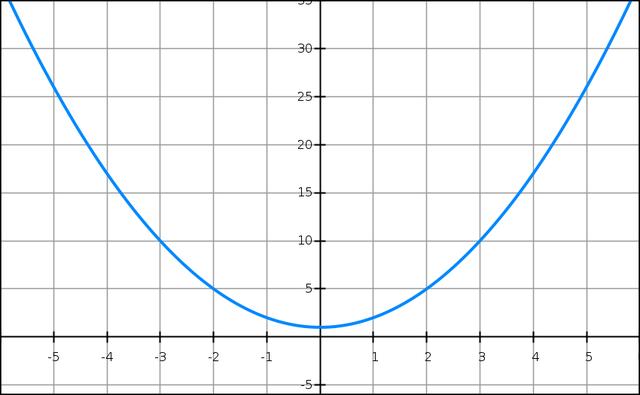
жҳҫ然дёҖзңје°ұзҹҘйҒ“е®ғзҡ„жңҖе°ҸеҖјжҳҜ =0x=0 еӨ„пјҢдҪҶжҳҜиҝҷйҮҢжҲ‘们йңҖиҰҒз”ЁжўҜеәҰдёӢйҷҚжі•зҡ„ Python д»Јз ҒжқҘе®һзҺ°гҖӮ
#!/usr/bin/env python # -*- coding: utf-8 -*- """ дёҖз»ҙй—®йўҳзҡ„жўҜеәҰдёӢйҷҚжі•зӨәдҫӢ """ def func_1d(x): """ зӣ®ж ҮеҮҪж•° :param x: иҮӘеҸҳйҮҸпјҢж ҮйҮҸ :return: еӣ еҸҳйҮҸпјҢж ҮйҮҸ """ return x ** 2 + 1 def grad_1d(x): """ зӣ®ж ҮеҮҪж•°зҡ„жўҜеәҰ :param x: иҮӘеҸҳйҮҸпјҢж ҮйҮҸ :return: еӣ еҸҳйҮҸпјҢж ҮйҮҸ """ return x * 2 def gradient_descent_1d(grad, cur_x=0.1, learning_rate=0.01, precision=0.0001, max_iters=10000): """ дёҖз»ҙй—®йўҳзҡ„жўҜеәҰдёӢйҷҚжі• :param grad: зӣ®ж ҮеҮҪж•°зҡ„жўҜеәҰ :param cur_x: еҪ“еүҚ x еҖјпјҢйҖҡиҝҮеҸӮж•°еҸҜд»ҘжҸҗдҫӣеҲқе§ӢеҖј :param learning_rate: еӯҰд№ зҺҮпјҢд№ҹзӣёеҪ“дәҺи®ҫзҪ®зҡ„жӯҘй•ҝ :param precision: и®ҫзҪ®ж”¶ж•ӣзІҫеәҰ :param max_iters: жңҖеӨ§иҝӯд»Јж¬Ўж•° :return: еұҖйғЁжңҖе°ҸеҖј x* """ for i in range(max_iters): grad_cur = grad(cur_x) if abs(grad_cur) < precision: break # еҪ“жўҜеәҰи¶Ӣиҝ‘дёә 0 ж—¶пјҢи§Ҷдёә收ж•ӣ cur_x = cur_x - grad_cur * learning_rate print("第", i, "ж¬Ўиҝӯд»Јпјҡx еҖјдёә ", cur_x) print("еұҖйғЁжңҖе°ҸеҖј x =", cur_x) return cur_x if __name__ == '__main__': gradient_descent_1d(grad_1d, cur_x=10, learning_rate=0.2, precision=0.000001, max_iters=10000)е…ідәҺеҰӮдҪ•з”ЁPythonзҗҶи§Јдәәе·ҘжҷәиғҪдјҳеҢ–з®—жі•е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ





