本篇内容介绍了“Python数据分析的方法是什么”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
TGI计算公式中,有三个关键点需要进一步拆解:某一特征,总体,目标群体。
随便举个栗子,假设我们要研究A公司脱发TGI指数:
某一特征,就是我们想要分析的某种行为或者状态,这里是脱发(或者说受脱发困扰)
总体,是我们研究的所有对象,即A公司所有人
目标群体,是总体中我们感兴趣的一个分组,假设我们关注的分组是数据部,那目标群体就是数据部
于是乎,公式中分子“目标群体中具有某一特征的群体所占比例”可以理解为“数据部脱发人数占数据部的比例”,假设数据部有15个人,有9个人受脱发困扰,那数据部脱发人数占比就是9/15,等于60%。
而分母“总体中具有相同特征的群体所占比例”,等同于“全公司受脱发困扰人数占公司总人数的比例”,假设公司一共500人,有120人受脱发困扰,那这个比例是24%。
所以,数据部脱发TGI指数,可以用60% / 24% * 100 = 250,其他部门脱发TGI指数计算逻辑是一样的,用本部门脱发人数占比 / 公司脱发人数占比 * 100即可。
TGI指数大于100,代表着某类用户更具有相应的倾向或者偏好,数值越大则倾向和偏好越强;小于100,则说明该类用户相关倾向较弱(和平均相比);而等于100则表示在平均水平。
刚才的例子中,我们瞎掰的数据部脱发TGI指数是250,远远高于100,看来搞数据的脱发风险极高,数据才是真正的发际线推手。
下面,我们通过一个案例来巩固概念理解,顺便和潘大师(Pandas)过过招。
项目背景
BOSS抛来一份订单明细,“小Z啊,我们最近要推出一款客单比较高的产品,打算在一些城市先试销,你看看这个数据,哪些城市的人有高客单偏好,帮我筛选5个吧”。
小Z赶紧打开表格,看看数据到底长什么样子:
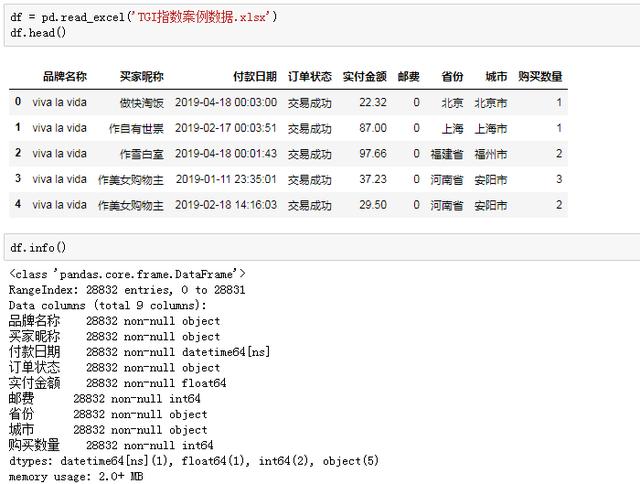
订单数据包括品牌名、买家姓名、付款时间、订单状态和地域等字段,一共28832条数据,没有空值。
粗略看了几眼源数据,小Z赶紧明确数据需求:“领导,那客单比较高的定义是什么?”
“就我们产品线和历史数据来看,单次购买大于50元就算高客单的客户了”。
确认了高客单之后,我们的目标非常明确:按照高客单偏好给城市做个排序。这里的偏好,可以用TGI指数来衡量,我们再次复习下TGI三个核心点:
特征,高客单,即客户单次购买超过50元
目标群体,就是各个城市,这里我们可以分别计算出所有城市客户的高客单偏好
至于总体,就非常直白了,计算所涉及到的所有客户即为总体
解题的关键在于,计算出不同城市,高客单人数及所占的比例。
单个用户打标
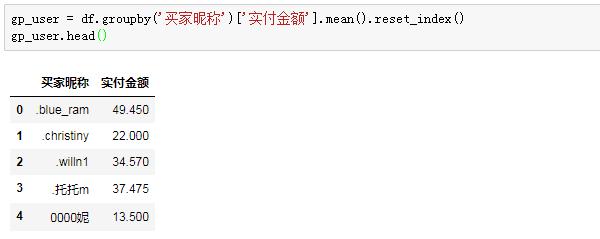
第一步,我们先判断每个用户是否属于高客单的人群,所以先按用户昵称进行分组,看每位用户的平均支付金额。这里用平均,是因为有的客户多次购买,而每次下单金额也不一样,故平均之。
接着,定义一个判断函数,如果单个用户平均支付金额大于50,就打上“高客单”的类别,否则为低客单,再用apply函数调用:
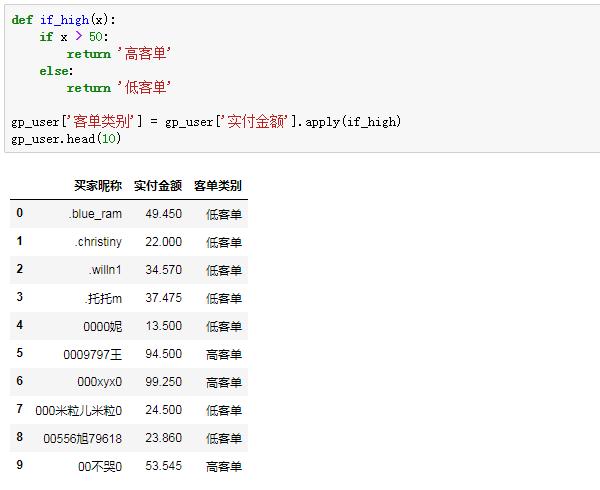
到这里基于高低客单的用户初步打标已经完成。
匹配城市
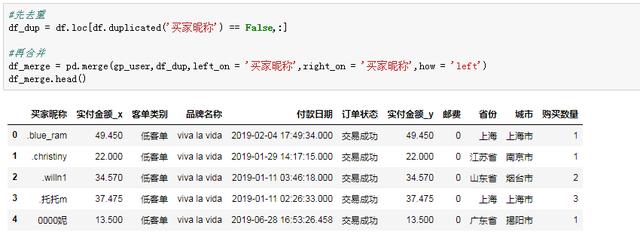
单个用户的金额和客单标签已经搞定,下一步就是补充每个用户的地域字段,一句pd.merge函数就能搞定。由于源数据是未去重的,我们得先按昵称去重,不然匹配的结果会有许多重复的数据:
高客单TGI指数计算
要计算每个城市高客单TGI指数,需要得到每个城市高客单、低客单的人数分别是多少。如果用EXCEL的数据透视表处理起来就很简单,直接把省份和城市拖拽到行的位置,客单类别拖到列的位置,值随便选一个字段,只要是统计就好。
不要慌,这一套操作,Python实现起来也灰常容易,pivot_table透视表函数一行就搞定:
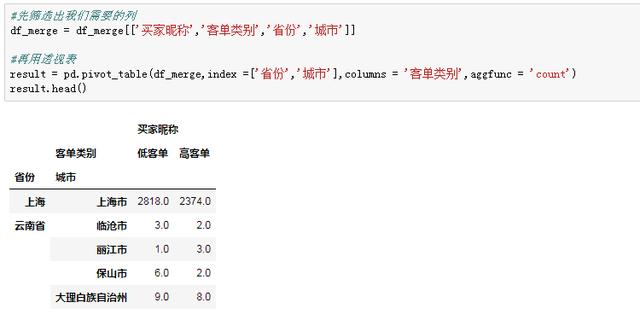
这样得到的结果包含了层次化索引,受篇幅限制就不展开讲,我们只要知道要索引得到“高客单”列,需要先索引“买家昵称”,再索引“高客单”:
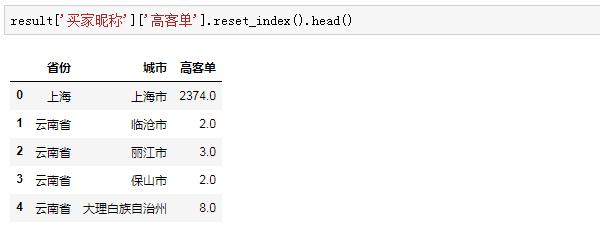
这样,拿到了每个省市的高客单人数,然后再拿到低客单的人数,进行横向合并:
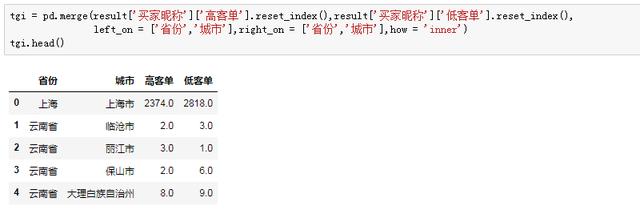
我们再看看每个城市总人数以及高客单人数占比,来完成“目标群体中具有某一特征的群体所占比例”这个分子的计算:
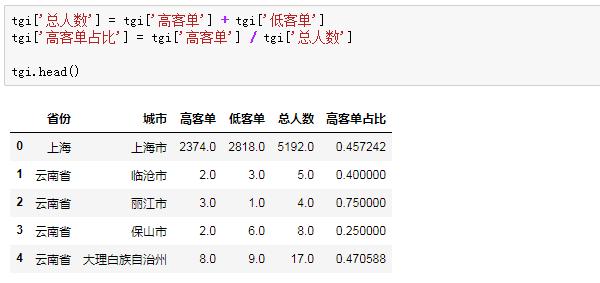
有些非常小众的城市,高客单或者低客单人数等于1甚至没有,而这些值尤其是空值会影响结果的计算,我们要提前检核数据:
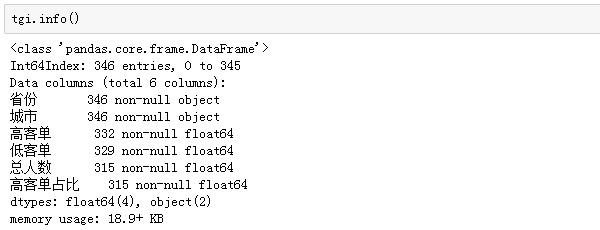
果然,高客单和低客单都有空值(可以理解为0),从而导致总人数也存在空值,而TGI指数对于空值来说意义不大,所以我们剔除掉存在空值的行:

接着统计总人数中,高客单人群的比例,来对标公式中的分母“总体中具有相同特征的群体所占比例”:

最后一步,就是TGI指数的计算,顺便排个序:
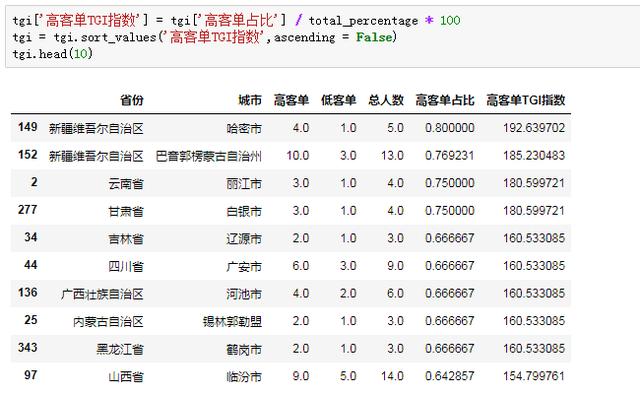
出了结果,小Z兴致勃勃的打算第一时间报告老板,说时迟那时快,在按下回车之前又扫了一眼数据,发现了一个严重的问题:高客单TGI指数排名靠前的城市,总客户数几乎不超过10人,这样的高客单人口占比,完全没有说服力。
TGI指数能够显示偏好的强弱,但很容易让人忽略具体的样本量大小,这个是需要格外注意的。
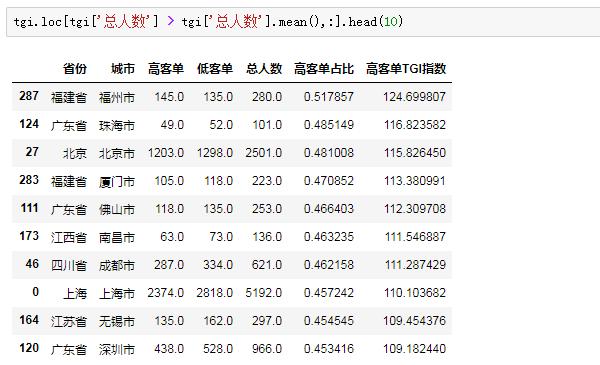
怎么办呢?为了加强数据整体的信度,小Z决定先对总人数进行筛选,用总人数的平均值作为阈值,只保留总人数大于平均值的城市:
“Python数据分析的方法是什么”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://www.toutiao.com/a6755695391489917454/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



