本篇内容介绍了“如何测试Linux内核入口代码”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
通用寄存器+delta状态
到目前为止,我们尚未涉及的一件事是将其他通用寄存器也设置为随机值。入口代码在工作过程中确实会用到某些通用寄存器,如果我们真的在某个地方遇到了问题,那么它很可能因随机值而崩溃。
我们可能还想找出更细微的漏洞——虽然这些漏洞不会使得内核彻底崩溃,但可能会将内核地址泄漏到用户空间从未见过的某个寄存器中。一种检查内核是否正确,是否保存了我们的寄存器/标志等的方法是在从内核模式返回后写出寄存器的状态。这并不难实现,因为我们可以将所有(或者至少是大部分)寄存器的值存放到固定的地址中(例如,在我们已经用于其他用途的数据页中)。这里的难点在于如何将其与在一个子进程中运行多个进入尝试(entry attempts)/系统调用结合起来,因为需要将健全性检查与进入尝试交织在一起,这可能会非常麻烦。
最大限度地降低崩溃的概率
我们在第二篇文章中已经提到,令子进程崩溃的代价相当高,因为这意味着要启动一个全新的子进程。因此,尽可能避免崩溃(并在同一个子进程中运行尽可能多的进入尝试)可能是提高fuzzer性能的可行策略。这包括两个主要部分:
· 保存/恢复行内所需的状态,例如,你要保存和恢复%rsp,以便后续的pushf/popf指令能够继续工作。
· 从信号处理程序中恢复,例如通过安装处理程序,可以将进程恢复到已知的良好状态。
检查生成的汇编代码
虽然代码很容易在生成汇编代码的时候出错,但人们却很难注意到,因为程序都崩溃了,你也看不出你得到的是一个意外的结果。我曾经遇到过类似的问题,但是在2年的时间里一直没有觉察到:我在编码ljmp操作数的地址时,不小心用错了字节顺序,所以在32位兼容模式下,它实际上从来没有运行过任何东西!
一种检查汇编代码的简便方法是使用像udis86这样的反汇编库,然后通过手动方式验证生成的代码。
#include ... ud_t u; ud_init(&u); ud_set_vendor(&u, UD_VENDOR_INTEL); ud_set_mode(&u, 64); ud_set_pc(&u, (uint64_t) mem); ud_set_input_buffer(&u, (unsigned char *) mem, (char *) out - (char *) mem); ud_set_syntax(&u, UD_SYN_ATT); while (ud_disassemble(&u)) fprintf(stderr, " %08lx %s\n", ud_insn_off(&u), ud_insn_asm(&u)); fprintf(stderr, "\n");KVM/Xen/Intel/AMD的交互
在一个案例中,我们看到了与KVM的交互,其中启动任何KVM实例都会破坏GDTR(GDT寄存器)的大小,并允许fuzzer通过使用超出GDT预期大小的段而导致崩溃。事实证明,这个漏洞是可利用的,并能获得ring 0的执行权限。在另一个案例中,我们看到了在硬件加速的嵌套式客户机(客户机中的客户机)中运行时的交互。
通常,KVM需要模拟底层硬件的某些特性,这增加了相当多的复杂性。fuzzer很有可能在KVM或Xen等管理程序中发现漏洞,因此在不同的裸机CPU和多种管理程序下运行fuzzer是很有价值的。
要想以编程方式创建KVM实例,请参阅Serge Zaitsev撰写的KVM host in a few lines of code一文。
一个相关的有趣实验可能是为运行在x86上的Windows或其他操作系统编译fuzzer,看看它们的效果如何。我在WSL(Windows Subsystem for Linux)上简单地测试了Linux二进制文件,没有发生什么不良情况。
配置/启动选项
配置/启动选项会影响入口代码的具体操作。下面是我在最新的内核中发现的相关选项:
$ grep -o 'CONFIG_[A-Z0-9_]*' arch/x86/entry/entry_64*.S | sort | uniq CONFIG_DEBUG_ENTRY CONFIG_IA32_EMULATION CONFIG_PARAVIRT CONFIG_RETPOLINE CONFIG_STACKPROTECTOR CONFIG_X86_5LEVEL CONFIG_X86_ESPFIX64 CONFIG_X86_L1_CACHE_SHIFT CONFIG_XEN_PV其实,还有更多的选项,它们都隐藏在头文件中。通过这些选项的不同组合来构建多个内核,可以帮助揭示那些被破坏的组合,也许只有在由fuzzer触发的边缘情况下才会出现。
通过查看Documentation/admin-guide/kernel-parameters.txt,你还可以找到一些可能影响入口代码的选项。这里有一个Python脚本,它可以生成随机的配置选项组合,这对于用KVM传递内核命令行非常有用:
import random flags = """nopti nospectre_v1 nospectre_v2 spectre_v2_user=off spec_store_bypass_disable=off l1tf=off mds=off tsx_async_abort=off kvm.nx_huge_pages=off noapic noclflush nosmap nosmep noexec32 nofxsr nohugeiomap nosmt nosmt noxsave noxsaveopt noxsaves intremap=off nolapic nomce nopat nopcid norandmaps noreplace-smp nordrand nosep nosmp nox2apic""".split() print(' '.join(random.sample(flags, 5)), "nmi_watchdog=%u" % (random.randrange(2), ))ftrace
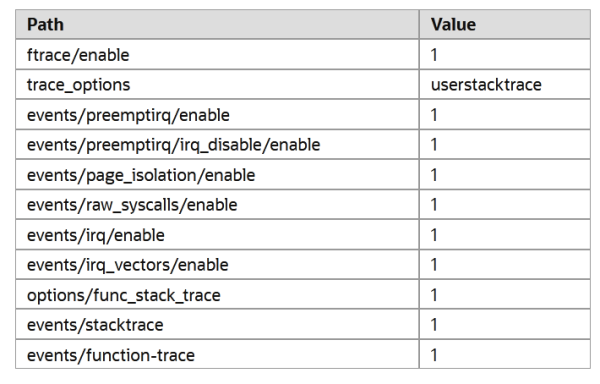
Ftrace启用时,会在入口代码中插入一些代码,例如用于系统调用和irqflags跟踪。这可能也非常值得进行测试,所以我建议在运行fuzzer之前,不妨调整一下这些文件(位于/sys/kernel/tracing路径下):
PTRACE_SYSCALL
我们已经看到,ptrace改变了处理系统调用进入/退出的方式(因为需要停止进程并通知跟踪器),所以最好在ptrace()下使用ptrace_syscall运行一部分进入尝试。当被ptrace停止时,尝试调整被跟踪的进程的一些/所有寄存器也可能很有趣。要完全正确地完成这个任务是非常困难的,所以这里就不多介绍了。
mkinitrd.sh
当我在VM中进行测试时,我更喜欢将程序绑定在initrd中,并以init(pid1)的形式运行,这样就不需要将其复制到文件系统映像上。您可以使用如下所示的脚本:
#! /bin/bash set -e set -x rm -rf initrd/ mkdir initrd/ g++ -static -Wall -std=c++14 -O2 -g -o initrd/init main.cc -lm (cd initrd/ && (find | cpio -o -H newc)) \ | gzip -c \ > initrd.entry-fuzz.gz如果你使用的是Qemu/KVM,只要传入-initrd initrd.entry-fuzz.gz,它就会在开机后立即运行fuzzer。
污点检查
如果fuzzer真的遇到了某种内核崩溃或漏洞,那么确保我们不会遗漏它们是很有用的。我个人喜欢在内核命令行中使用参数ops=panic panic_on_warn panic=-1,并将-no-reboot传递给Qemu/KVM;这将确保任何警告都会立即导致Qemu退出(将任何诊断程序留在终端上)。如果你正在使用专门的裸机运行fuzzer(例如,使用上面的initrd方法),可以令panic=0,这样只会挂起机器。
如果你在普通的工作站上进行测试,并且不想让整台机器挂掉,则可以检查内核是否被污染(每当出现警告或漏洞时都会被污染),然后直接地退出:
int tainted_fd = open("/proc/sys/kernel/tainted", O_RDONLY); if (tainted_fd == -1) error(EXIT_FAILURE, errno, "open()"); char tainted_orig_buf[16]; ssize_t tainted_orig_len = pread(tainted_fd, tainted_orig_buf, sizeof(tainted_orig_buf), 0); if (tainted_orig_len == -1) error(EXIT_FAILURE, errno, "pread()"); while (1) { // generate + run test case ... char tainted_buf[16]; ssize_t tainted_len = pread(tainted_fd, tainted_buf, sizeof(tainted_buf), 0); if (tainted_len == -1) error(EXIT_FAILURE, errno, "pread()"); if (tainted_len != tainted_orig_len || memcmp(tainted_buf, tainted_orig_buf, tainted_len)) { fprintf(stderr, "Kernel became tainted, stopping.\n"); // TODO: dump hex bytes or disassembly exit(EXIT_FAILURE); } }网络日志
如果内核崩溃了,并且不清楚问题出在哪里,那么将所有正在尝试的内容记录到网络中是非常有用的。我将给出一个UDP日志的简单框架:
int main(...) { int udp_socket = socket(AF_INET, SOCK_DGRAM, 0); if (udp_socket == -1) error(EXIT_FAILURE, errno, "socket(AF_INET, SOCK_DGRAM, 0)"); struct sockaddr_in remote_addr = {}; remote_addr.sin_family = AF_INET; remote_addr.sin_port = htons(21000); inet_pton(AF_INET, "10.5.0.1", &remote_addr.sin_addr.s_addr); if (connect(udp_socket, (const struct sockaddr *) &remote_addr, sizeof(remote_addr)) == -1) error(EXIT_FAILURE, errno, "connect()"); ... }然后,在生成了每个入口/出口的代码之后,您可以简单地将其转储到这个套接字上:
write(udp_socket, (char *) mem, out - (uint8_t *) mem);我们希望日志服务器最后接收到的数据(这里是10.5.0.1:21000)会包含导致崩溃的汇编代码。根据具体的用例,有时需要添加某种框架,以便可以轻松地判断出测试用例的具体开始和结束位置。
检查fuzzer是否能捕捉到已知的漏洞
多年来,人们已经在入口代码中找到了许多漏洞。因此,我们可以构建一些旧的、有漏洞的内核,并在它们上面运行fuzzer,以确保它确实能捕捉到这些已知的漏洞。我们也可以用寻找漏洞所花费的时间来衡量fuzzer的效率,但是,我们必须小心,不要过度优化,以防止它们只找到这些漏洞。
代码覆盖率/插桩技术反馈
插桩技术
AFL和syzkaller这样的fuzzer如此有效的原因之一是,它们使用代码复盖率来非常精确地衡量调整测试用例的各个二进制位的效果。这通常是通过使用一个特殊的编译器标志编译C代码来实现的,该标志发出额外的代码来收集覆盖率数据。对于汇编代码,尤其是入口代码,这是一个非常棘手的问题,因为如果不手动检查代码的每个指令,我们就无法知道CPU到底处于什么状态(以及我们可以破坏哪些寄存器/状态)。
但是,如果我们真的想要提高代码覆盖率,有一种方法可以做到:x86指令集包含一条指令,该指令同时接受一个立即数和一个立即数地址,并且不影响任何其他状态(例如标志):movb$value,(addr)。我们唯一需要注意的是:确保addr是一个编译时常量地址,它总是映射到某个物理内存,并在页表中标记为present,这样我们在访问它时就不会出现页面错误。幸运的是,Linux已经提供了一种机制:fixmaps,也就是“编译时虚拟内存分配”。这样,我们就可以静态地分配一个编译时常量虚拟地址,该地址指向所有任务和上下文的相同底层物理页面。由于它是在任务之间共享的,因此当在进程之间切换时,我们必须清除或以其他方式保存/恢复这些值。
通过组合使用C宏和汇编器宏,我们可以得到一个侵入性非常低的覆盖原语,你可以在入口代码中的任何地方加入这个原语,来记录所采用的代码路径。我已经编写了一个补丁,但还有一些边缘情况需要解决(例如,当SMAP被启用时,它并不完全有效)。此外,我怀疑x86的维护者是否会喜欢在入口代码中掺杂这些覆盖率注释。
在fuzzer方面,有一件事让插桩技术反馈变得更加复杂,那就是你需要一个完整的系统来跟踪测试用例、结果以及(可能的)你对每个测试用例应用了哪些突变。正因为如此,我选择暂时忽略代码覆盖率;无论如何,这都是一个宽泛的fuzzing话题,与x86或特别是入口代码没有太大关系。
性能计数器/硬件反馈
收集代码覆盖率的一种完全不同的方法是使用性能计数器。我知道最近有两个项目就是这样做的:
· Resmack Fuzz Test
· kAFL
这里最大的好处显然是不需要进行检测(修改内核)。最大的缺点在于性能计数器不是完全确定的(可能是由于硬件中断等外部因素所致)。也许它对入口代码也不起作用,因为在汇编代码上只花费了很短的时间。
“如何测试Linux内核入口代码”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://www.4hou.com/posts/vD1L



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



