写爬虫都需要些什么呢,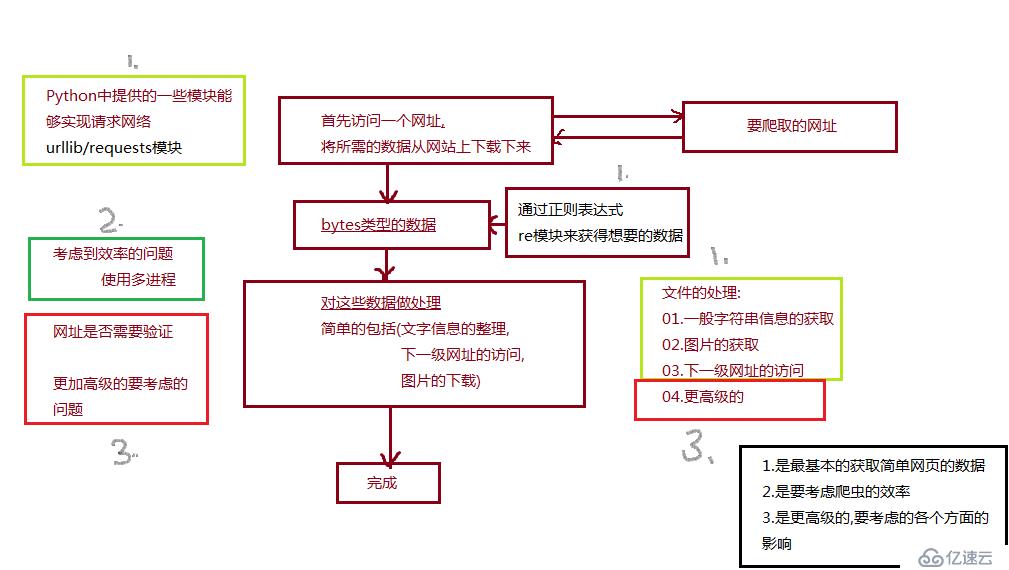
A 要爬取的网址难度的大小 (选择谷歌对要爬取的网址源代码进行分析)
B 借用Python中的模块urllib与requests 对网址进行请求与访问
以requests为例:(requests模块的导入见:https://blog.51cto.com/13747953/2321389)
a 下载图片
import requests
ret=requests.get('http://×××w.xiaohuar.com/d/file/20180724/40d83a6709eca21137dcdd80ee28c31b.jpg')
print(ret,type(ret))
print(ret.status_code)
print(ret.content)
with open(r'E:\text1\爬虫\text_png\p1.png','wb') as f:
f.write(ret.content)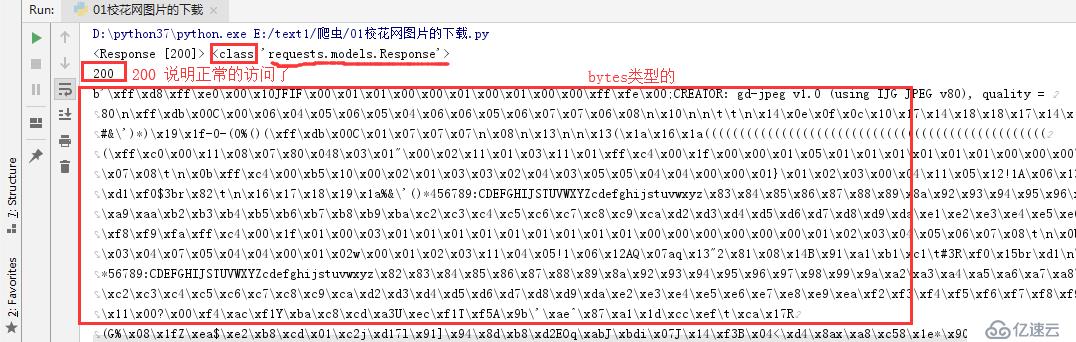
b 基本文字信息的获取
import requests
from urllib import request
# ret=requests.get('http://maoyan.com/board')
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
ret=request.Request('http://maoyan.com/board',headers=headers)
resp=request.urlopen(ret)
print(resp,type(resp))
print(resp.read().decode('utf-8'))这里不用requests 模块是因为在请求的过程中返回了403的错误
猜想可能的原因是:网址的反爬虫机制发现了来自pycharm的请求;
所以可以用urllib(Python自带的模块)提供的request模块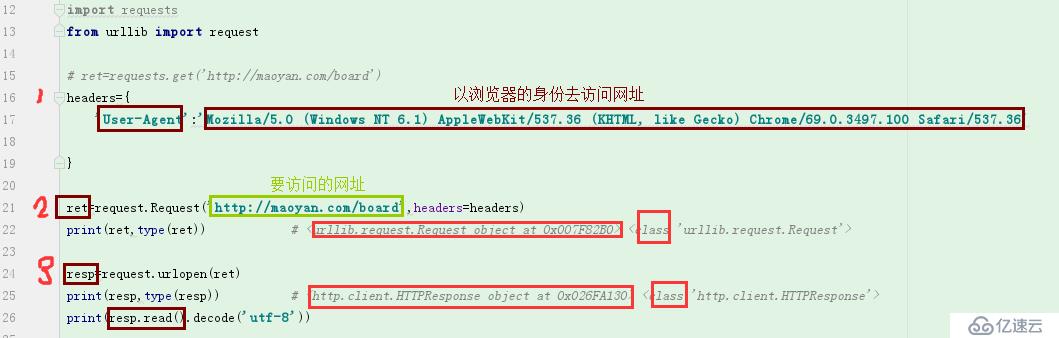
结果如下: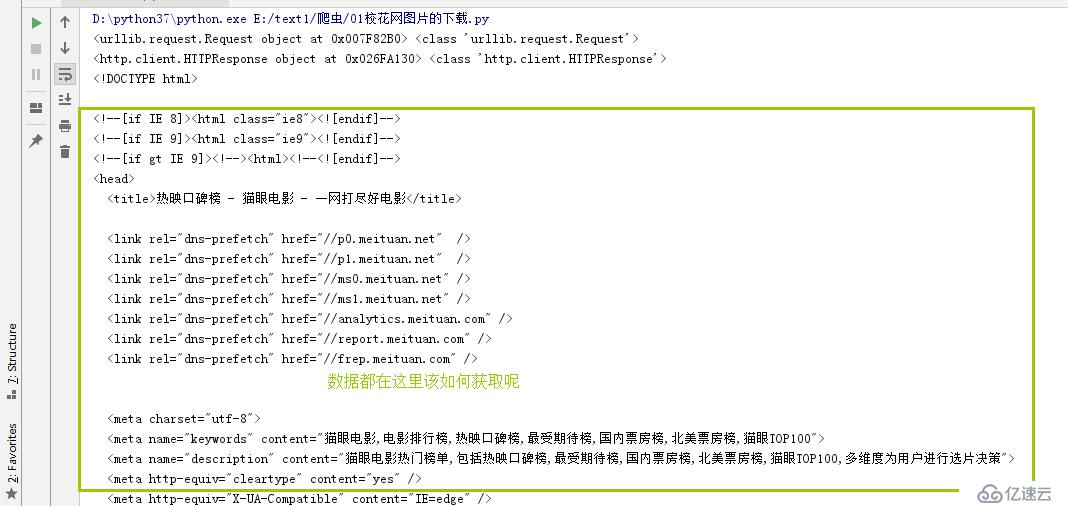
C 如何从B-b中获取的文字数据中提取出自己想要的数据呢
a 分析数据的相同点

b 利用正则表达式与re模块
'<div class="item_t">(?:.*?)src="(?P<png>.*?)"(?:.*?)<span class="price">(?P<name>.*?)</span>(?:.*?)'
'<a href="http://www.xiaohuar.com/" class="img_album_btn">(?P<place>.*?)</a>', re.S)'<div class="item_t"> # 匹配开始的标志
(?:.*?) # 匹配任意的字符,但用?取消了分组优先显示和贪婪匹配
src="(?P<png>.*?)" # 要获取的数据优先显示,并?P<名字>命名了
(?:.*?)
<span class="price">
(?P<name>.*?)
</span>
(?:.*?)
''<a href="http://www.xiaohuar.com/" class="img_album_btn">
(?P<place>.*?)
</a>'
,re.S # 声明 . 可以匹配任意的字符
)俩个实例:
1爬取简单的文字信息:https://blog.51cto.com/13747953/2321800
2爬取图片: https://blog.51cto.com/13747953/2321803
(程序猿很无聊多多指教交流)
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





