本篇文章给大家分享的是有关Python中怎么实现数据分析功能,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
1)数据获取
一般有数据分析师岗位需求的公司都会有自己的数据库,数据分析师可以通过SQL查询语句来获取数据库中想要数据。Python已经具有连接sql server、mysql、orcale等主流数据库的接口包,比如pymssql、pymysql、cx_Oracle等。
而获取外部数据主要有两种获取方式,一种是获取国内一些网站上公开的数据资料;一种是通过编写爬虫代码自动爬取数据。如果希望使用Python爬虫来获取数据,我们可以使用以下Python工具:
Requests-主要用于爬取数据时发出请求操作。
BeautifulSoup-用于爬取数据时读取XML和HTML类型的数据,解析为对象进而处理。
Scapy-一个处理交互式数据的包,可以解码大部分网络协议的数据包
2)数据存储
对于数据量不大的项目,可以使用excel来进行存储和处理,但对于数据量过万的项目,使用数据库来存储与管理会更高效便捷。
3)数据预处理
注释:加群943752371获取python入门20天完整学习笔记和100道基础练习题及答案以及入门书籍视频源码等资料
数据预处理也称数据清洗。大多数情况下,我们拿到手的数据是格式不一致,存在异常值、缺失值等问题的,而不同项目数据预处理步骤的方法也不一样。CDA数据分析师认为数据分析有80%的工作都在处理数据。如果选择Python作为数据清洗的工具的话,我们可以使用Numpy和Pandas这两个工具库:
Numpy - 用于Python中的科学计算。它非常适用于与线性代数,傅里叶变换和随机数相关的运算。它可以很好地处理多维数据,并兼容各种数据库。
Pandas –Pandas是基于Numpy扩展而来的,可以提供一系列函数来处理数据结构和运算,如时间序列等。
4)建模与分析
这一阶段首先要清楚数据的结构,结合项目需求来选取模型。
常见的数据挖掘模型有:
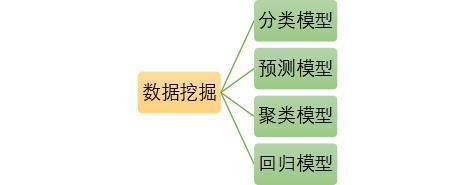
在这一阶段,Python也具有很好的工具库支持我们的建模工作:
scikit-learn-适用Python实现的机器学习算法库。scikit-learn可以实现数据预处理、分类、回归、降维、模型选择等常用的机器学习算法。
Tensorflow-适用于深度学习且数据处理需求不高的项目。这类项目往往数据量较大,且最终需要的精度更高。
5)可视化分析
数据分析最后一步是撰写数据分析报告,这也是数据可视化的一个过程。在数据可视化方面,Python目前主流的可视化工具有:
Matplotlib-主要用于二维绘图,它能让使用者很轻松地将数据图形化,并且提供多样化的输出格式。
Seaborn-是基于matplotlib产生的一个模块,专攻于统计可视化,可以和Pandas进行无缝链接。
按照这个流程,每个阶段所涉及的知识点可以细分如下:
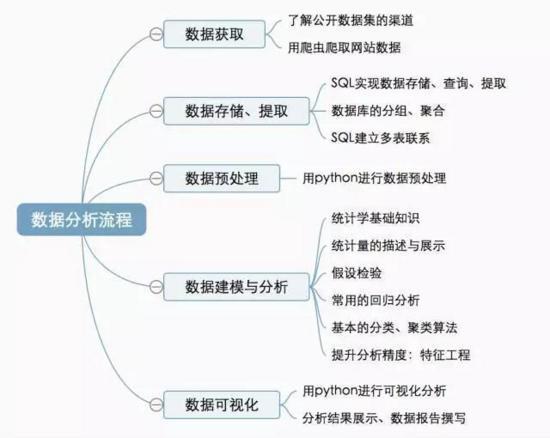
以上就是Python中怎么实现数据分析功能,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





