1. 字符在内存中都是以unicode类型存在。
2. 当数据要保存到磁盘或者网络传输时,会转为utf-8等编码再保存或传输。
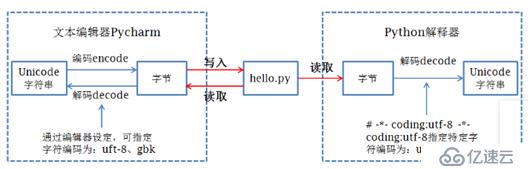
3. 在python文件第一行指定的编码方式用于向python解释器指出解码方式。
4. Python中字符的存储类型有bytes和unicode,在py2.x中被称为str和unicode, 在py3.x中被称为bytes和str.
5. Py2.x和py3.x中字符的类型都为str, 因此在py2.x中是bytes类型,在py3.x中是unicode类型。
6. py2.x中文件默认解码方式(即python文件第一行不指定时)为ASCII, py3.x中为UTF-8. 使用sys.getdefaultencoding()获得。
7. 编码、解码过程。
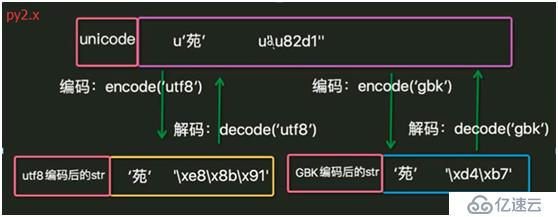
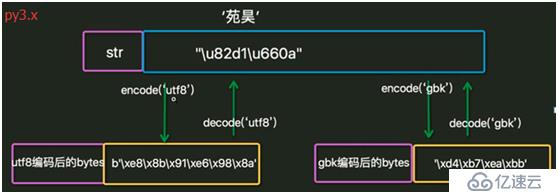
8. IDE在程序运行前先按文档属性设定的编码方式把数据保存到磁盘,然后python解释器按文件第一行的解码方式把磁盘中存储的二进制序列读取并解码为unicode加载到内存中。
编码:把人类发明的文字及符号转化为计算机能够识别的二进制序列的过程。
解码:把计算机内部存储的二进制序列转化为人类能够认识的文字及符号的过程。
ASCII: 占一个字节,保留最高位,其余7位组成了128个字符的字符集。
unicode: unicode编码了世界上所有的文字。
utf-8: 对unicode进行了压缩和优化。ASCII码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存。
GBK: 汉字的国标码,用2个字节保存。
1. 验证Py2.x中的字符类型。
Py2.x:
#coding:utf-8
s = '中国hello'
print s
print type(s)
print len(s)
print repr(s)
执行结果:
中国hello
<type 'str'>
11
'\xe4\xb8\xad\xe5\x9b\xbdhello'可见是str类型,即bytes类型。len()是占用的字节数。
Py2.x:
#coding:utf-8
s = u'中国hello'
print s
print type(s)
print len(s)
print repr(s)
执行结果:
中国hello
<type 'unicode'>
7
u'\u4e2d\u56fdhello'指定了使用unicode类型。 u4e2d是unicode字符集中字符“中”的代码。len()是字符的个数。
2. bytes和unicode的转换。
#coding:utf-8
s = '中国'
print type(s)
print len(s)
s2 = s.decode('utf-8')
type(s2)
print len(s2)
执行结果:
<type 'str'>
6
<type 'unicode'>
23. 不同编码类型的字符串拼接。
Py2.x:
#coding:utf-8
print 'cisco'+u'google'
执行结果:
ciscogoogle
之所以英文字符可以把两种类型的进行拼接,是因为在python2.x中,只要数据全部是 ASCII 的话,python解释器自动把 byte 转换为 unicode 。但是一旦一个非 ASCII 字符偷偷进入你的程序,那么默认的解码将会失效,从而造成 UnicodeDecodeError 的错误。python2.x编码让程序在处理 ASCII 的时候更加简单。你付出的代价就是在处理非 ASCII 的时候将会失败。
Py2.x:
#coding:utf-8
s = 'hello'+'china'
print s
print type(s)
print repr(s)
执行结果:
hellochina
<type 'str'>
'hellochina'
查看不同编码类型拼接后的存储类型:
Py2.x:
#coding:utf-8
s = 'hello'+u'china'
print s
print type(s)
print repr(s)
执行结果:
hellochina
<type 'unicode'>
u'hellochina'
可见Py2.x进行了自动转换。
Py2.x:
#coding:utf-8
print '中国'+'美国'
执行结果:
中国美国
Py2.x:
#coding:utf-8
print '中国'+u'美国'
执行结果:
Traceback (most recent call last):
File "E:\python\study\test\index.py", line 14, in <module>
print '中国'+u'美国'
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)Py3.x中即使都是ASCII范围内,也不能进行拼接:
#coding:utf-8
s1 = 'cisco'
print(type(s1))
s2 = b'google'
print(type(s2))
print(s1+s2)
执行结果:
<class 'str'>
<class 'bytes'>
Traceback (most recent call last):
File "E:\python\study\test\index.py", line 6, in <module>
print(s1+s2)
TypeError: can only concatenate str (not "bytes") to str1. 验证Py3.x中的字符类型。
#coding:utf-8
import json
s1 = '中国'
print(type(s1))
print(len(s1))
print(json.dumps(s1))
print(s1)
s2 = s1.encode('utf-8')
print(type(s2))
print(len(s2))
print(s2)
执行结果:
<class 'str'>
2
"\u4e2d\u56fd"
中国
<class 'bytes'>
6
b'\xe4\xb8\xad\xe5\x9b\xbd'#coding:utf-8
s = u'中'
print(s)
print(type(s))
print(len(s))
print(repr(s))
print(ord(s))
print(bin(ord(s)))
中
<class 'str'>
1
'中'
20013
0b1001110001011012. bytes和unicode的转换。除了encode和decode的转换方法,还可以:
#coding:utf-8
s1 = '中国'
print(type(s1))
s2 = bytes(s1,encoding='utf-8')
print(type(s2))
s3 = str(s2,encoding='utf-8')
print(type(s3))
执行结果:
<class 'str'>
<class 'bytes'>
<class 'str'>1. py2.x中默认的解码方式是ASCII, py3.x中默认的是utf-8, 当在py2.x中指定解码方式为utf-8时,py2.x和py3.x应该是没有区别,可为何在py2.x中默认的字符类型是bytes, 而在py3.x中确是unicode, 都是utf-8,不应该都是bytes吗?或者既然都加载在内存了,不该都是unicode吗?
答:python解释器从磁盘读取文件,以unicode编码方式把整个代码加载到内存中,然后逐条执行,当识别到字符串时,py2.x默认的str类型是bytes, 而py3.x默认的str类型是unicode, 但当有明确指定字符类型时,按指定的编码,如py2.x中的u'china', py3.x中的b'google'.
2. Py2.x中不指定utf-8编码方式时,print汉字会报错:
Py2.x:
s = '中国'
print s
结果:
File "E:\python\study\test\index.py", line 3
SyntaxError: Non-ASCII character '\xe4' in file E:\python\study\test\index.py on line 3, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details这是因为py2.x中默认的解码方式为ASCII, 而文件保存的编码方式为UTF-8, 两者不匹配,因此报错。
3. Py2.x中字符串s本来应该是字节类型,但为何print时却显示为明文了呢?
Py2.x中:
>>> s = '中国'
>>> s
'\xd6\xd0\xb9\xfa'
>>> print s
中国
>>>print '\xd6\xd0\xb9\xfa'
中国这是因为print在执行时调用了str函数,str函数执行了bytes到unicode的操作。但py3.x中不存在这种现象:
#coding:utf-8
import json
s1 = '中国'
print(type(s1))
print(len(s1))
print(json.dumps(s1))
print(s1)
s2 = s1.encode('utf-8')
print(type(s2))
print(len(s2))
print(s2)
执行结果:
<class 'str'>
2
"\u4e2d\u56fd"
中国
<class 'bytes'>
6
b'\xe4\xb8\xad\xe5\x9b\xbd'控制台中:
>>> s = '中国'
>>> print(type(s))
<class 'str'>
>>> s
'中国'
>>> print(s)
中国
>>> s1 = bytes(s,encoding='gbk')
>>> s1
b'\xd6\xd0\xb9\xfa'
>>> print(s1)
b'\xd6\xd0\xb9\xfa'
>>>4. 以utf-8保存文件,在windows中执行,输出不同:
#coding:utf-8
s = '中国'
print(s)
D:\Python37-32>python d:\index.py
中国
D:\Python27>python d:\index.py
涓浗因为py3.x中字符串被识别为unicode, 传给cmd.exe时被编码为GBK,再以GBK解码输出。但py2.x中字符串被识别为bytes, utf-8编码的两个汉字有6个字节,传给cmd.exe时按GBK解码,识别成为了3个乱码,再以GBK解码输出。
5. Py3.x使用open的r方法打开utf-8编码的文件时会报错:
#coding:utf-8
f = open('index.py','r')
print(f.read())
执行结果:
Traceback (most recent call last):
File "E:\python\study\test\test.py", line 5, in <module>
print(f.read())
UnicodeDecodeError: 'gbk' codec can't decode byte 0xad in position 2: illegal multibyte sequence
使用rb时输出:
b'\xe4\xb8\xad\xe5\x9b\xbd'py2.x中不会报错。open()方法打开文件时,read()读取的是str(py2.x中即是bytes),读取后需要使用正确的编码格式进行decode().
Py2.x:
f = open('index.py','r')
s = f.read()
print type(s)
print len(s)
print s
执行结果:
<type 'str'>
6
中国
可见,此处使用utf-8进行解码,如果指定为GBK呢?
#coding:gbk
f = open('index.py','r')
s = f.read()
print s
输出是涓浗,改为ASCII后同样报错。可查看py3.x使用的是GBK进行解码:
Py3.x:
>>> f = open('index.py','r')
>>> f
<_io.TextIOWrapper name='index.py' mode='r' encoding='cp936'>
但py2.x没有显示编码方式:
>>> f = open(r'e:\python\study\test\index.py','r')
>>> s = f.read()
>>> f
<open file 'e:\\python\\study\\test\\index.py', mode 'r' at 0x016BD1D8>可使用open('index.py','r',encoding='utf-8')指定编码方式。
https://www.cnblogs.com/OldJack/p/6658779.html
http://www.cnblogs.com/yuanchenqi/articles/5938733.html
https://www.cnblogs.com/shine-lee/p/4504559.html
https://blog.csdn.net/nyyjs/article/details/56667626
https://blog.csdn.net/nyyjs/article/details/56670080
https://www.jianshu.com/p/19c74e76ee0a
https://www.jb51.net/article/59599.htm
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



