本篇内容介绍了“Python性能优化分析”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
python为什么性能差:
当我们提到一门编程语言的效率时:通常有两层意思,***是开发效率,这是对程序员而言,完成编码所需要的时间;另一个是运行效率,这是对计算机而言,完成计算任务所需要的时间。编码效率和运行效率往往是鱼与熊掌的关系,是很难同时兼顾的。不同的语言会有不同的侧重,python语言毫无疑问更在乎编码效率,life is short,we use python。
虽然使用python的编程人员都应该接受其运行效率低的事实,但python在越多越来的领域都有广泛应用,比如科学计算 、web服务器等。程序员当然也希望python能够运算得更快,希望python可以更强大。
首先,python相比其他语言具体有多慢,这个不同场景和测试用例,结果肯定是不一样的。这个网址给出了不同语言在各种case下的性能对比,这一页是python3和C++的对比,下面是两个case:
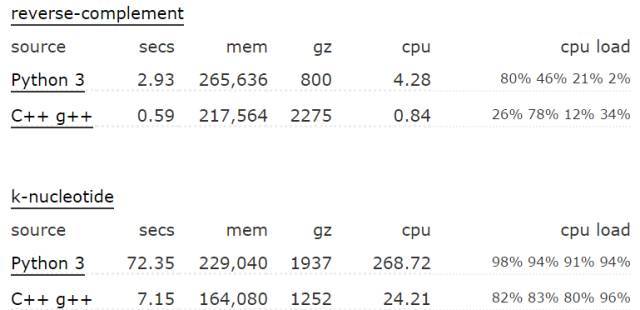
python运算效率低,具体是什么原因呢,下列罗列一些
***:python是动态语言
一个变量所指向对象的类型在运行时才确定,编译器做不了任何预测,也就无从优化。举一个简单的例子: r = a + b。 a和b相加,但a和b的类型在运行时才知道,对于加法操作,不同的类型有不同的处理,所以每次运行的时候都会去判断a和b的类型,然后执行对应的操作。而在静态语言如C++中,编译的时候就确定了运行时的代码。
第二:python是解释执行,但是不支持JIT(just in time compiler)。虽然大名鼎鼎的google曾经尝试Unladen Swallow 这个项目,但最终也折了。
第三:python中一切都是对象,每个对象都需要维护引用计数,增加了额外的工作。
第四:python GIL
GIL是Python最为诟病的一点,因为GIL,python中的多线程并不能真正的并发。如果是在IO bound的业务场景,这个问题并不大,但是在CPU BOUND的场景,这就很致命了。所以笔者在工作中使用python多线程的情况并不多,一般都是使用多进程(pre fork),或者在加上协程。即使在单线程,GIL也会带来很大的性能影响,因为python每执行100个opcode(默认,可以通过sys.setcheckinterval()设置)就会尝试线程的切换,具体的源代码在ceval.c::PyEval_EvalFrameEx。
第五:垃圾回收,这个可能是所有具有垃圾回收的编程语言的通病。python采用标记和分代的垃圾回收策略,每次垃圾回收的时候都会中断正在执行的程序,造成所谓的顿卡。infoq上有一篇文章,提到禁用Python的GC机制后,Instagram性能提升了10%。感兴趣的读者可以去细读。
Be pythonic
我们都知道 过早的优化是罪恶之源,一切优化都需要基于profile。但是,作为一个python开发者应该要pythonic,而且pythonic的代码往往比non-pythonic的代码效率高一些,比如:
使用迭代器iterator,for example:
dict的iteritems 而不是items(同itervalues,iterkeys)
使用generator,特别是在循环中可能提前break的情况
判断是否是同一个对象使用 is 而不是 ==
判断一个对象是否在一个集合中,使用set而不是list
利用短路求值特性,把“短路”概率过的逻辑表达式写在前面。其他的lazy ideas也是可以的
对于大量字符串的累加,使用join操作
使用for else(while else)语法
交换两个变量的值使用: a, b = b, a
基于profile的优化
即使我们的代码已经非常pythonic了,但可能运行效率还是不能满足预期。我们也知道80/20定律,绝大多数的时间都耗费在少量的代码片段里面了,优化的关键在于找出这些瓶颈代码。方式很多:到处加log打印时间戳、或者将怀疑的函数使用timeit进行单独测试,但最有效的是使用profile工具。
python profilers
对于python程序,比较出名的profile工具有三个:profile、cprofile和hotshot。其中profile是纯python语言实现的,Cprofile将profile的部分实现native化,hotshot也是C语言实现,hotshot与Cprofile的区别在于:hotshot对目标代码的运行影响较小,代价是更多的后处理时间,而且hotshot已经停止维护了。需要注意的是,profile(Cprofile hotshot)只适合单线程的python程序。
对于多线程,可以使用yappi,yappi不仅支持多线程,还可以精确到CPU时间
对于协程(greenlet),可以使用greenletprofiler,基于yappi修改,用greenlet context hook住thread context
下面给出一段编造的”效率低下“的代码,并使用Cprofile来说明profile的具体方法以及我们可能遇到的性能瓶颈。
# -*- coding: UTF-8 -*- from cProfile import Profile import math def foo(): return foo1() def foo1(): return foo2() def foo2(): return foo3() def foo3(): return foo4() def foo4(): return "this call tree seems ugly, but it always happen" def bar(): ret = 0 for i in xrange(10000): ret += i * i + math.sqrt(i) return ret def main(): for i in range(100000): if i % 10000 == 0: bar() else: foo() if __name__ == '__main__': prof = Profile() prof.runcall(main) prof.print_stats() #prof.dump_stats('test.prof') # dump profile result to test.prof code for profile运行结果如下:
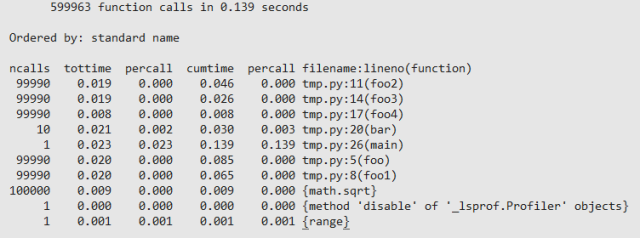
对于上面的的输出,每一个字段意义如下:
ncalls 函数总的调用次数
tottime 函数内部(不包括子函数)的占用时间
percall(***个) tottime/ncalls
cumtime 函数包括子函数所占用的时间
percall(第二个)cumtime/ncalls
filename:lineno(function) 文件:行号(函数)
代码中的输出非常简单,事实上可以利用pstat,让profile结果的输出多样化,具体可以参见官方文档python profiler。
profile GUI tools
虽然Cprofile的输出已经比较直观,但我们还是倾向于保存profile的结果,然后用图形化的工具来从不同的维度来分析,或者比较优化前后的代码。查看profile结果的工具也比较多,比如,visualpytune、qcachegrind、runsnakerun,本文用visualpytune做分析。对于上面的代码,按照注释生成修改后重新运行生成test.prof文件,用visualpytune直接打开就可以了,如下:
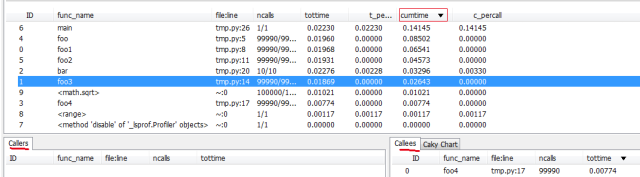
字段的意义与文本输出基本一致,不过便捷性可以点击字段名排序。左下方列出了当前函数的calller(调用者),右下方是当前函数内部与子函数的时间占用情况。上如是按照cumtime(即该函数内部及其子函数所占的时间和)排序的结果。
造成性能瓶颈的原因通常是高频调用的函数、单次消耗非常高的函数、或者二者的结合。在我们前面的例子中,foo就属于高频调用的情况,bar属于单次消耗非常高的情况,这都是我们需要优化的重点。
python-profiling-tools中介绍了qcachegrind和runsnakerun的使用方法,这两个colorful的工具比visualpytune强大得多。具体的使用方法请参考原文,下图给出test.prof用qcachegrind打开的结果。
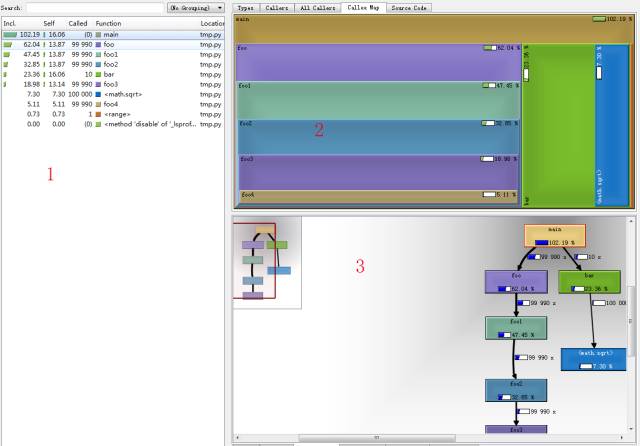
qcachegrind确实要比visualpytune强大。从上图可以看到,大致分为三部:。***部分同visualpytune类似,是每个函数占用的时间,其中Incl等同于cumtime, Self等同于tottime。第二部分和第三部分都有很多标签,不同的标签标示从不同的角度来看结果,如图上所以,第三部分的“call graph”展示了该函数的call tree并包含每个子函数的时间百分比,一目了然。
profile针对优化
知道了热点,就可以进行针对性的优化,而这个优化往往根具体的业务密切相关,没用***钥匙,具体问题,具体分析。个人经验而言,最有效的优化是找产品经理讨论需求,可能换一种方式也能满足需求,少者稍微折衷一下产品经理也能接受。次之是修改代码的实现,比如之前使用了一个比较通俗易懂但效率较低的算法,如果这个算法成为了性能瓶颈,那就考虑换一种效率更高但是可能难理解的算法、或者使用dirty Flag模式。对于这些同样的方法,需要结合具体的案例,本文不做赘述。
接下来结合python语言特性,介绍一些让python代码不那么pythonic,但可以提升性能的一些做法
***:减少函数的调用层次
每一层函数调用都会带来不小的开销,特别对于调用频率高,但单次消耗较小的calltree,多层的函数调用开销就很大,这个时候可以考虑将其展开。
对于之前调到的profile的代码,foo这个call tree非常简单,但频率高。修改代码,增加一个plain_foo()函数, 直接返回最终结果,关键输出如下:

跟之前的结果对比:
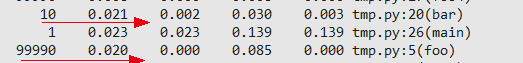
可以看到,优化了差不多3倍。
第二:优化属性查找
上面提到,python 的属性查找效率很低,如果在一段代码中频繁访问一个属性(比如for循环),那么可以考虑用局部变量代替对象的属性。
第三:关闭GC
在本文的***章节已经提到,关闭GC可以提升python的性能,GC带来的顿卡在实时性要求比较高的应用场景也是难以接受的。但关闭GC并不是一件容易的事情。我们知道python的引用计数只能应付没有循环引用的情况,有了循环引用就需要靠GC来处理。在python语言中, 写出循环引用非常容易。比如:
case 1: a, b = SomeClass(), SomeClass() a.b, b.a = b, a case 2: lst = [] lst.append(lst) case 3: self.handler = self.some_func当然,大家可能说,谁会这么傻,写出这样的代码,是的,上面的代码太明显,当中间多几个层级之后,就会出现“间接”的循环应用。在python的标准库 collections里面的OrderedDict就是case2:
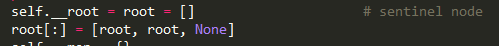
要解决循环引用,***个办法是使用弱引用(weakref),第二个是手动解循环引用。
第四:setcheckinterval
如果程序确定是单线程,那么修改checkinterval为一个更大的值,这里有介绍。
第五:使用__slots__
slots最主要的目的是用来节省内存,但是也能一定程度上提高性能。我们知道定义了__slots__的类,对某一个实例都会预留足够的空间,也就不会再自动创建__dict__。当然,使用__slots__也有许多注意事项,最重要的一点,继承链上的所有类都必须定义__slots__,python doc有详细的描述。下面看一个简单的测试例子:
class BaseSlots(object): __slots__ = ['e', 'f', 'g'] class Slots(BaseSlots): __slots__ = ['a', 'b', 'c', 'd'] def __init__(self): self.a = self.b = self.c = self.d = self.e = self.f = self.g = 0 class BaseNoSlots(object): pass class NoSlots(BaseNoSlots): def __init__(self): super(NoSlots,self).__init__() self.a = self.b = self.c = self.d = self.e = self.f = self.g = 0 def log_time(s): begin = time.time() for i in xrange(10000000): s.a,s.b,s.c,s.d, s.e, s.f, s.g return time.time() - begin if __name__ == '__main__': print 'Slots cost', log_time(Slots()) print 'NoSlots cost', log_time(NoSlots())输出结果:
Slots cost 3.12999987602 NoSlots cost 3.48100018501
python C扩展
也许通过profile,我们已经找到了性能热点,但这个热点就是要运行大量的计算,而且没法cache,没法省略。。。这个时候就该python的C扩展出马了,C扩展就是把部分python代码用C或者C++重新实现,然后编译成动态链接库,提供接口给其它python代码调用。由于C语言的效率远远高于python代码,所以使用C扩展是非常普遍的做法,比如我们前面提到的cProfile就是基于_lsprof.so的一层封装。python的大所属对性能有要求的库都使用或者提供了C扩展,如gevent、protobuff、bson。
笔者曾经测试过纯python版本的bson和cbson的效率,在综合的情况下,cbson快了差不多10倍!
python的C扩展也是一个非常复杂的问题,本文仅给出一些注意事项:
***:注意引用计数的正确管理
这是最难最复杂的一点。我们都知道python基于指针技术来管理对象的生命周期,如果在扩展中引用计数出了问题,那么要么是程序崩溃,要么是内存泄漏。更要命的是,引用计数导致的问题很难debug。。。
C扩展中关于引用计数最关键的三个词是:steal reference,borrowed reference,new reference。建议编写扩展代码之前细读python的官方文档。
第二:C扩展与多线程
这里的多线程是指在扩展中new出来的C语言线程,而不是python的多线程,出了python doc里面的介绍,也可以看看《python cookbook》的相关章节。
第三:C扩展应用场景
仅适合与业务代码的关系不那么紧密的逻辑,如果一段代码大量业务相关的对象 属性的话,是很难C扩展的
将C扩展封装成python代码可调用的接口的过程称之为binding,Cpython本身就提供了一套原生的API,虽然使用最为广泛,但该规范比较复杂。很多第三方库做了不同程度的封装,以便开发者使用,比如boost.python、cython、ctypes、cffi(同时支持pypy cpython),具体怎么使用可以google。
beyond CPython
尽管python的性能差强人意,但是其易学易用的特性还是赢得越来越多的使用者,业界大牛也从来没有放弃对python的优化。这里的优化是对python语言设计上、或者实现上的一些反思或者增强。这些优化项目一些已经夭折,一些还在进一步改善中,在这个章节介绍目前还不错的一些项目。
cython
前面提到cython可以用到binding c扩展,但是其作用远远不止这一点。
Cython的主要目的是加速python的运行效率,但是又不像上一章节提到的C扩展那么复杂。在Cython中,写C扩展和写python代码的复杂度差不多(多亏了Pyrex)。Cython是python语言的超集,增加了对C语言函数调用和类型声明的支持。从这个角度来看,cython将动态的python代码转换成静态编译的C代码,这也是cython高效的原因。使用cython同C扩展一样,需要编译成动态链接库,在linux环境下既可以用命令行,也可以用distutils。
如果想要系统学习cython,建议从cython document入手,文档写得很好。下面通过一个简单的示例来展示cython的使用方法和性能(linux环境)。
首先,安装cython:
pip install Cython
下面是测试用的python代码,可以看到这两个case都是运算复杂度比较高的例子:
def f(): return x**2-x def integrate_f(a, b, N): s = 0 dx = (b-a)/N for i in range(N): s += f(a+i*dx) return s * dx def main(): import time begin = time.time() for i in xrange(10000): for i in xrange(100):f(10) print 'call f cost:', time.time() - begin begin = time.time() for i in xrange(10000): integrate_f(1.0, 100.0, 1000) print 'call integrate_f cost:', time.time() - begin if __name__ == '__main__': main()运行结果:
call f cost: 0.215116024017 call integrate_f cost: 4.33698010445不改动任何python代码也可以享受到cython带来的性能提升,具体做法如下:
step1:将文件名(cython_example.py)改为cython_example.pyx
step2:增加一个setup.py文件,添加一下代码:
from distutils.core import setup from Cython.Build import cythonize setup( name = 'cython_example', ext_modules = cythonize("cython_example.pyx"), )step3:执行python setup.py build_ext –inplace

可以看到 增加了两个文件,对应中间结果和***的动态链接库
step4:执行命令 python -c “import cython_example;cython_example.main()”(注意: 保证当前环境下已经没有 cython_example.py)
运行结果:
call f cost: 0.0874309539795 call integrate_f cost: 2.92381191254性能提升了大概两倍,我们再来试试cython提供的静态类型(static typing),修改cython_example.pyx的核心代码,替换f()和integrate_f()的实现如下:
def f(double x): # 参数静态类型 return x**2-x def integrate_f(double a, double b, int N): cdef int i cdef double s, dx s = 0 dx = (b-a)/N for i in range(N): s += f(a+i*dx) return s * dx然后重新运行上面的第三 四步:结果如下
call f cost: 0.042387008667 call integrate_f cost: 0.958620071411上面的代码,只是对参数引入了静态类型判断,下面对返回值也引入静态类型判断。
替换f()和integrate_f()的实现如下:
cdef double f(double x): # 返回值也有类型判断 return x**2-x cdef double integrate_f(double a, double b, int N): cdef int i cdef double s, dx s = 0 dx = (b-a)/N for i in range(N): s += f(a+i*dx) return s * dx然后重新运行上面的第三 四步:结果如下
call f cost: 1.19209289551e-06 call integrate_f cost: 0.187038183212Amazing!
pypy
pypy是CPython的一个替代实现,其最主要的优势就是pypy的速度,下面是官网的测试结果:
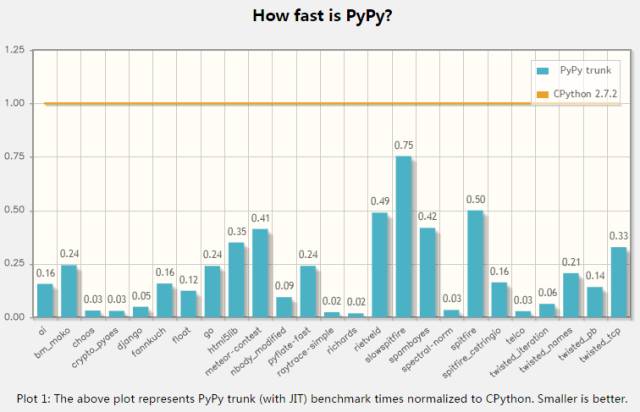
在实际项目中测试,pypy大概比cpython要快3到5倍!pypy的性能提升来自JIT Compiler。在前文提到google的Unladen Swallow 项目也是想在CPython中引入JIT,在这个项目失败后,很多开发人员都开始加入pypy的开发和优化。另外pypy占用的内存更少,而且支持stackless,基本等同于协程。
pypy的缺点在于对C扩展方面支持的不太好,需要使用CFFi来做binding。对于使用广泛的library来说,一般都会支持pypy,但是小众的、或者自行开发的C扩展就需要重新封装了。
“Python性能优化分析”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://mp.weixin.qq.com/s/TXy1W-3uibSWy42pYmKkkA



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



